全部的 K8S学习笔记总目录,请点击查看。
Kubernetes 调度器是 Kubernetes 集群中的一个核心组件,它负责监控新创建的 Pod,并选择一个 Node 让 Pod 在上面运行。Kubernetes 调度器的核心功能是将 Pod 调度到合适的 Node 上,这里的合适是指满足 Pod 的资源需求和其他的一些调度策略。
Kubernetes调度
为何要控制Pod应该如何调度
- 集群中有些机器的配置高(SSD,更好的内存等),我们希望核心的服务(比如说数据库)运行在上面
- 某两个服务的网络传输很频繁,我们希望它们最好在同一台机器上
- ……
Kubernetes Scheduler 的作用是将待调度的 Pod 按照一定的调度算法和策略绑定到集群中一个合适的 Worker Node 上,并将绑定信息写入到 etcd 中,之后目标 Node 中 kubelet 服务通过 API Server 监听到 Scheduler 产生的 Pod 绑定事件获取 Pod 信息,然后下载镜像启动容器。
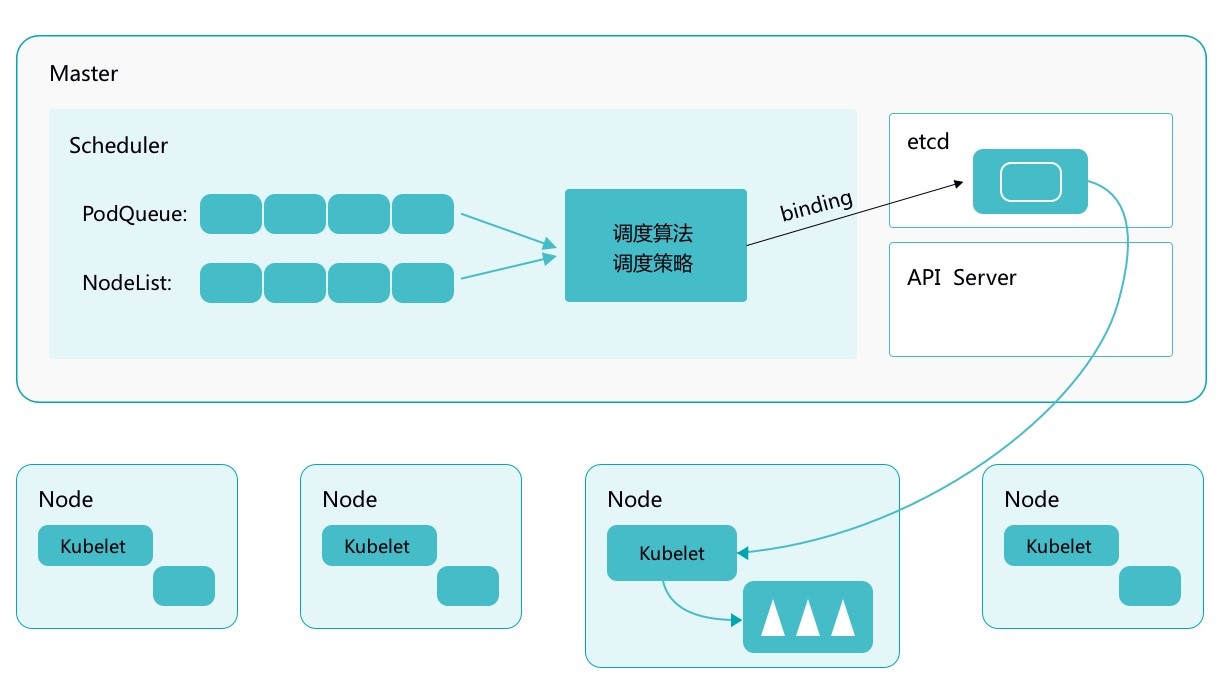
调度的过程
Scheduler 提供的调度流程分为预选 (Predicates) 和优选 (Priorities) 两个步骤:
- 预选,K8S会遍历当前集群中的所有 Node,筛选出其中符合要求的 Node 作为候选
- 优选,K8S将对候选的 Node 进行打分
经过预选筛选和优选打分之后,K8S选择分数最高的 Node 来运行 Pod,如果最终有多个 Node 的分数最高,那么 Scheduler 将从当中随机选择一个 Node 来运行 Pod。
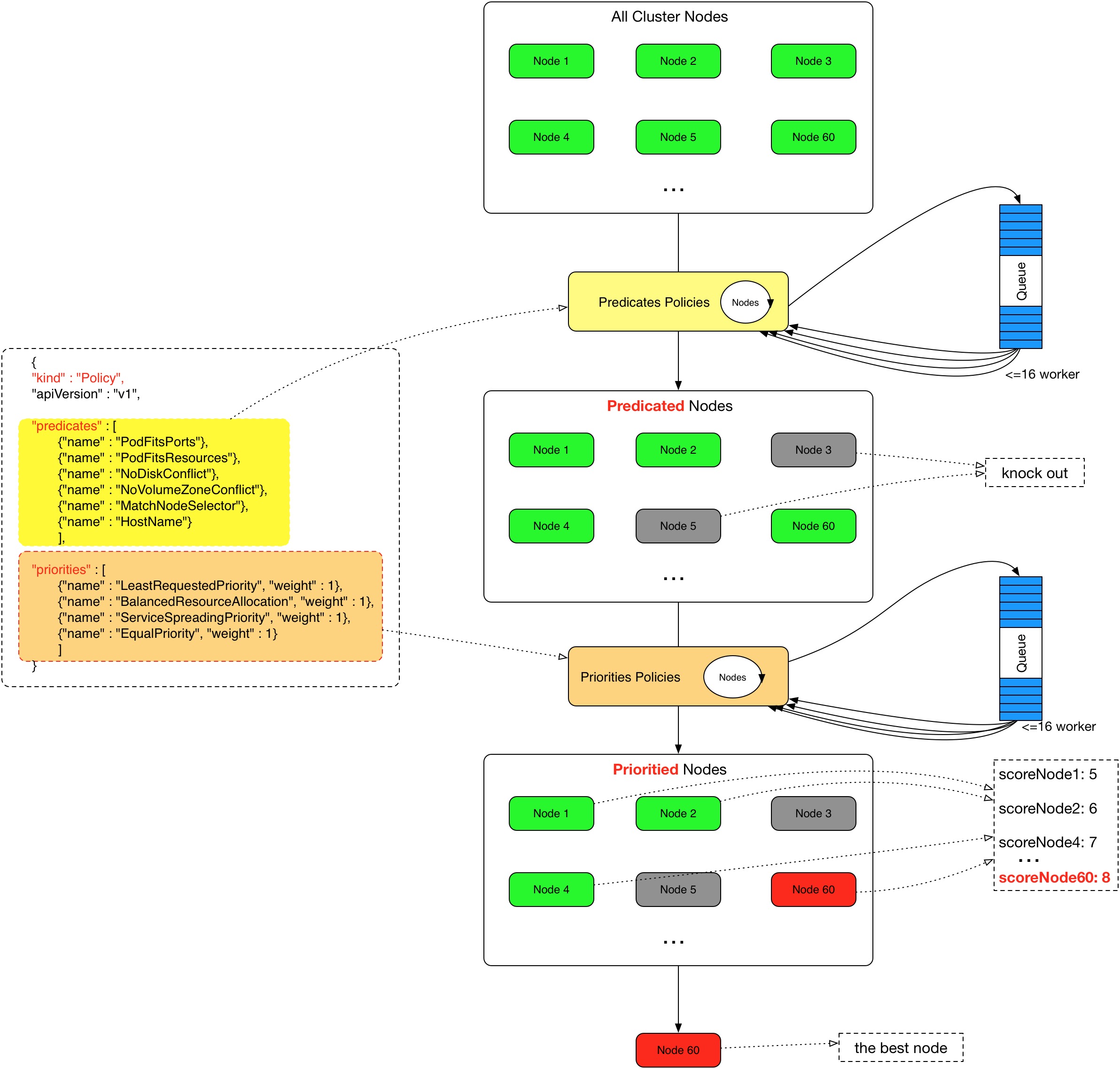
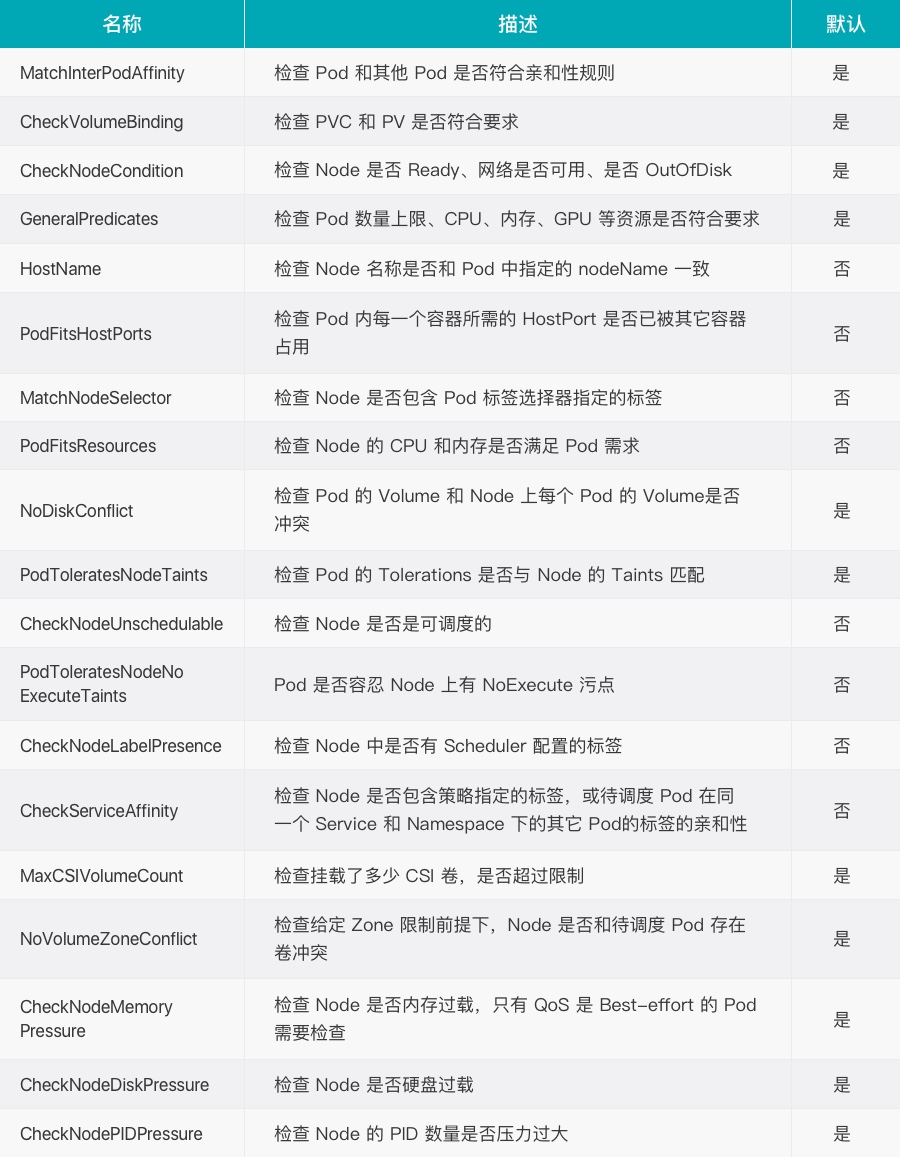
预选:
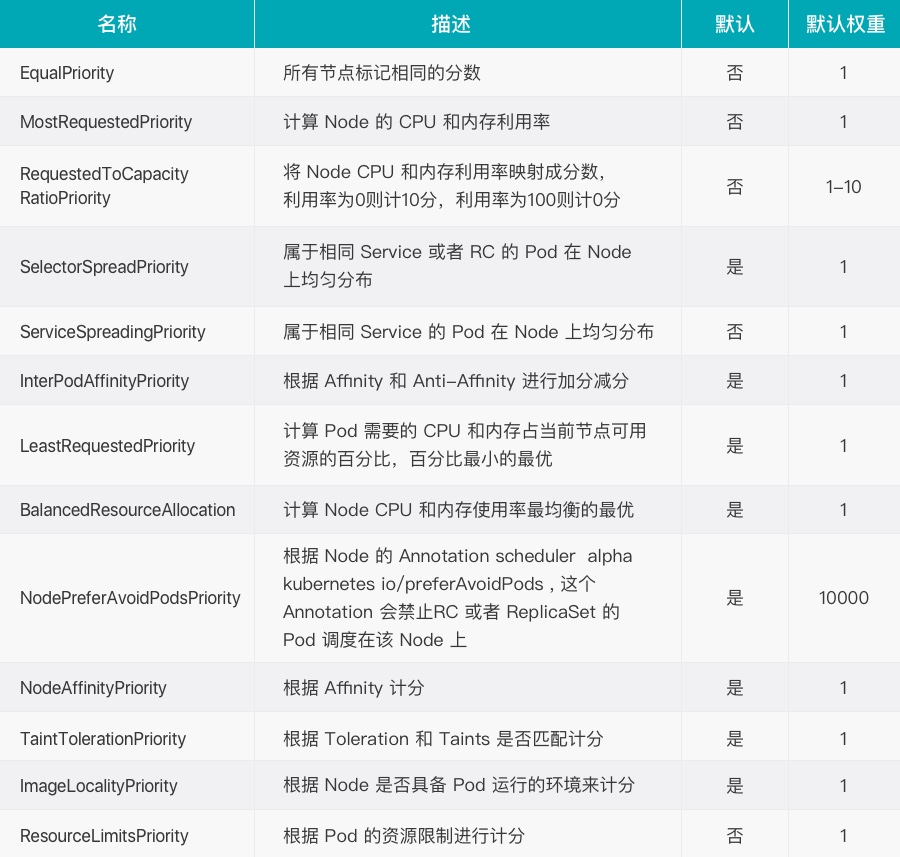
优选:
NodeSelector
label是kubernetes中一个非常重要的概念,用户可以非常灵活的利用 label 来管理集群中的资源,POD 的调度可以根据节点的 label 进行特定的部署。
查看节点的label:
1 | $ kubectl get nodes --show-labels |
为节点打label:
1 | $ kubectl label node k8s-master disktype=ssd |
当 node 被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在spec字段中添加nodeSelector字段,里面是我们需要被调度的节点的 label。
1 | ... |
nodeAffinity
节点亲和性,比上面的nodeSelector更加灵活,它可以进行一些简单的逻辑组合,不只是简单的相等匹配。分为两种,硬策略和软策略。
- requiredDuringSchedulingIgnoredDuringExecution:硬策略,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然我就不会调度Pod。
- preferredDuringSchedulingIgnoredDuringExecution:软策略,如果你没有满足调度要求的节点的话,Pod就会忽略这条规则,继续完成调度过程,说白了就是满足条件最好了,没有满足就忽略掉的策略。
1 | #要求 Pod 不能运行在101和102两个节点上,如果有节点满足disktype=ssd或者sas的话就优先调度到这类节点上 |
这里的匹配逻辑是 label 的值在某个列表中,现在Kubernetes提供的操作符有下面的几种:
- “In”:label 的值在某个列表中
- “NotIn”:label 的值不在某个列表中
- “Gt”:label 的值大于某个值
- “Lt”:label 的值小于某个值
- “DoesNotExist”:某个 label 不存在
- “Exists”:某个 label 存在
如果nodeSelectorTerms下面有多个选项的话,满足任何一个条件就可以了;如果matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度 Pod
pod亲和性和反亲和性
场景:
myblog 启动多副本,但是期望可以尽量分散到集群的可用节点中
分析:为了让myblog应用的多个pod尽量分散部署在集群中,可以利用pod的反亲和性,告诉调度器,如果某个节点中存在了myblog的pod,则可以根据实际情况,实现如下调度策略:
- 不允许同一个node节点,调度两个myblog的副本
- 可以允许同一个node节点中调度两个myblog的副本,前提是尽量把pod分散部署在集群中
1 | ... |
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
污点(Taints)与容忍(tolerations)
对于nodeAffinity无论是硬策略还是软策略方式,都是调度 Pod 到预期节点上,而Taints恰好与之相反,如果一个节点标记为 Taints ,除非 Pod 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度Pod。
Taints(污点)是Node的一个属性,设置了Taints(污点)后,因为有了污点,所以Kubernetes是不会将Pod调度到这个Node上的。于是Kubernetes就给Pod设置了个属性Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去。
场景一:私有云服务中,某业务使用GPU进行大规模并行计算。为保证性能,希望确保该业务对服务器的专属性,避免将普通业务调度到部署GPU的服务器。
场景二:用户希望把 Master 节点保留给 Kubernetes 系统组件使用,或者把一组具有特殊资源预留给某些 Pod,则污点就很有用了,Pod 不会再被调度到 taint 标记过的节点。
taint 标记节点举例如下:
设置污点:
1 | $ kubectl taint node [node_name] key=value:[effect] |
去除污点:
1 | 去除指定key及其effect: |
污点演示:
1 | ## 给k8s-node1打上污点,smoke=true:NoSchedule |
Pod容忍污点示例:myblog/deployment/deploy-myblog-taint.yaml
1 | ... |
1 | $ kubectl apply -f deploy-myblog-taint.yaml |
Pod容忍污点示例:myblog/deployment/deploy-myblog-all-taint.yaml
1 | spec: |
1 | $ kubectl apply -f deploy-myblog-all-taint.yaml |
Cordon
cordon 停止调度
将节点标记为不可调度,即使该节点上有空闲资源,也不会再将新的 Pod 调度到该节点上。本质上,cordon 只是给节点打上了一个污点,key 为 node.kubernetes.io/unschedulable,value 为 true,效果为 NoSchedule。因此,如果节点上已经有了 Pod,那么这些 Pod 不会受到影响,它们依然会在该节点上运行,同时,可以容忍该污点的 Pod 也可以继续被调度到该节点上。
停止调度命令如下:
1 | $ kubectl cordon [node_name] |
1 | $ kubectl cordon k8s-node2 |
uncordon 恢复调度
将节点标记为可调度,本质上,uncordon 只是将节点上的污点删除。
恢复调度命令如下:
1 | $ kubectl uncordon [node_name] |
1 | $ kubectl uncordon k8s-node2 |
drain 节点维护
drain 命令会将节点标记为不可调度,并且驱逐该节点上的所有 Pod。
drain 本质上做了两件事情,一是将节点标记为不可调度,与cordon类似,打的污点也是一样的,二是驱逐该节点上的所有 Pod。因此,drain 命令会触发 Pod 的删除过程,而不是 Pod 的重建过程。如果节点上有 DaemonSet 类型的 Pod,那么 drain 命令不会驱逐这些 Pod,除非指定了 –ignore-daemonsets 参数。
安全驱逐的方式允许 pod 中的容器遵循指定的 PodDisruptionBudgets 执行优雅的终止,以确保应用程序的可用性。
安全驱逐命令如下:
1 | $ kubectl drain k8s-node2 |
恢复调度命令如下:
1 | # 命令与恢复cordron一样,因为drain本质上就是cordon+驱逐Pod,所以恢复调度也就是uncordon即可 |
Pod驱逐策略
K8S 有个特色功能叫 pod eviction,它在某些场景下如节点 NotReady,或者资源不足时,把 pod 驱逐至其它节点,这也是出于业务保护的角度去考虑的。
Kube-controller-manager: 周期性检查所有节点状态,当节点处于 NotReady 状态超过一段时间后,驱逐该节点上所有 pod。
pod-eviction-timeout:NotReady 状态节点超过该时间后,执行驱逐,默认 5 min,适用于k8s 1.13版本之前1.13版本后,集群开启
TaintBasedEvictions与TaintNodesByCondition功能,即taint-based-evictions,即节点若失联或者出现各种异常情况,k8s会自动为node打上污点,同时为pod默认添加如下容忍设置:1
2
3
4
5
6
7
8
9tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300即各pod可以独立设置驱逐容忍时间。
Kubelet: 周期性检查本节点资源,当资源不足时,按照优先级驱逐部分 pod
memory.available:节点可用内存nodefs.available:节点根盘可用存储空间nodefs.inodesFree:节点inodes可用数量imagefs.available:镜像存储盘的可用空间imagefs.inodesFree:镜像存储盘的inodes可用数量