全部的 K8S学习笔记总目录,请点击查看。
我们已经有了一些监控数据了,但是我们还需要一个监控面板,来展示我们的监控数据,这里我们使用Grafana来展示我们的监控数据。
Grafana介绍
Grafana 是一个开源的度量分析和可视化工具,可以通过将采集的数据查询展示成漂亮的图表,并且提供了丰富的插件支持。支持 Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus 自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大。
安装Grafana
最新的安装方式可以参考官方文档:在Kubernetes上安装Grafana,里面有资源配置清单可以参考进行安装。这里我们使用helm进行安装,如果想要单独安装请参考官方文档。
1 | # 添加helm仓库 |
安装完成后,我们就可以访问grafana了。
使用上面配置的用户名和密码登录后,我们就可以看到grafana的首页了。但是目前的grafana还没有任何的监控面板,我们需要导入一些监控面板。
导入监控面板
导入监控面板主要有三种方式:
- 导入dashboard
- 安装相应的插件
- 自定义监控面板
导入Dashboard的配置
官方已经提供了一些Dashboard的配置,我们可以直接导入使用,可以在官方Dashboard列表中找到需要的Dashboard。
这里我们导入两个Dashboard:
官方提供的Dashboard
进入官方提供的Dashboard页面,可以看到有很多的Dashboard样式,我们可以根据自己的需求进行选择,进行不同的筛选,选到自己的Dashboard后,点击进入详情页面,可以看到Dashboard的ID,我们可以通过这个ID来导入Dashboard。
Node Exporter
这个Dashboard是用来监控节点的,我们可以看到节点的CPU、内存、磁盘、网络等信息。
我们从官方提供的Dashboard页面中找到这个Dashboard,进入详情页面,可以看到Dashboard的ID为15172,我们可以通过这个ID来导入Dashboard。
进入grafana的首页,点击[+]按钮,选择Import
在输入框中输入Dashboard的ID,点击Load按钮
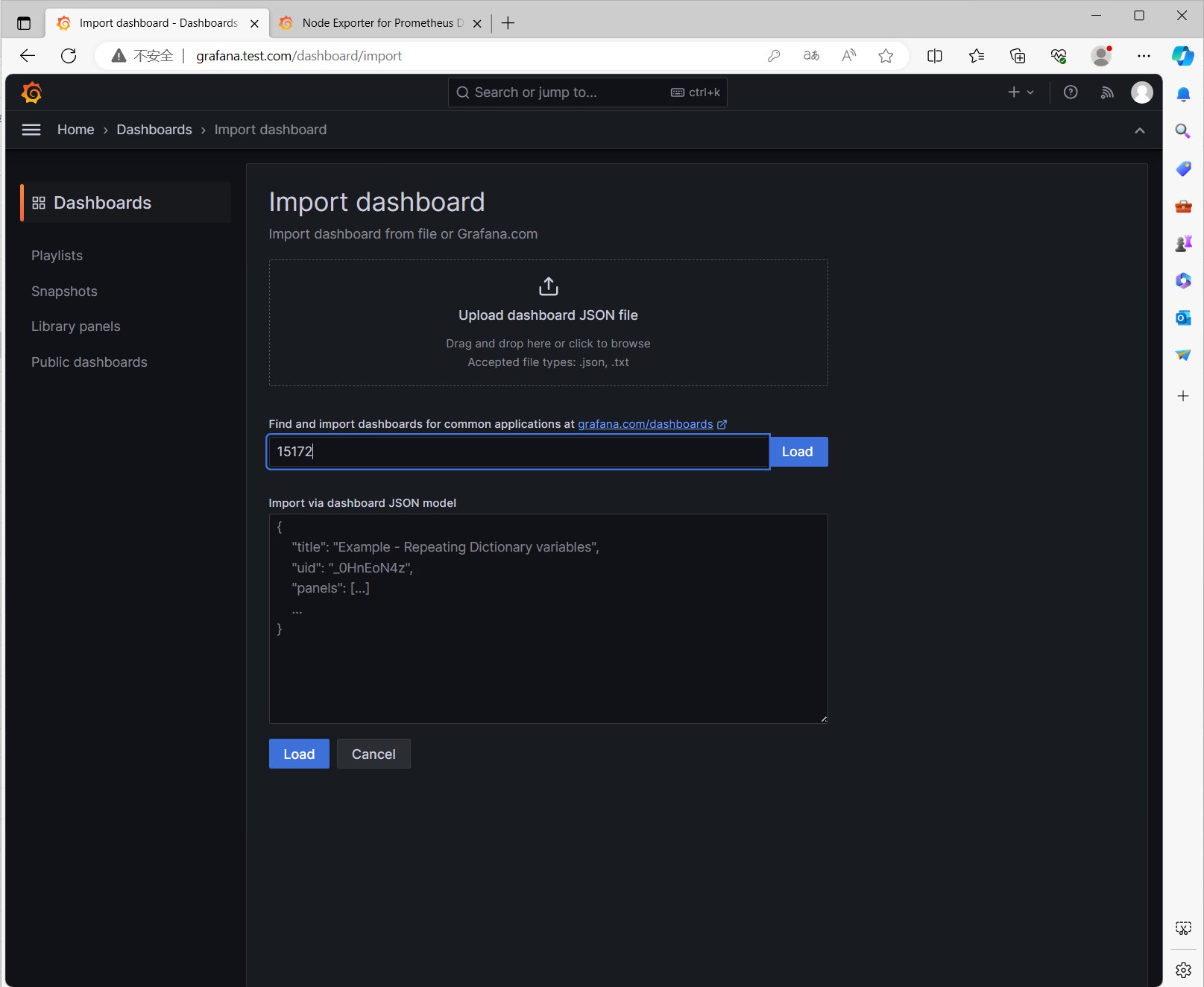
然后可以看到Dashboard的信息,点击Import按钮导入Dashboard
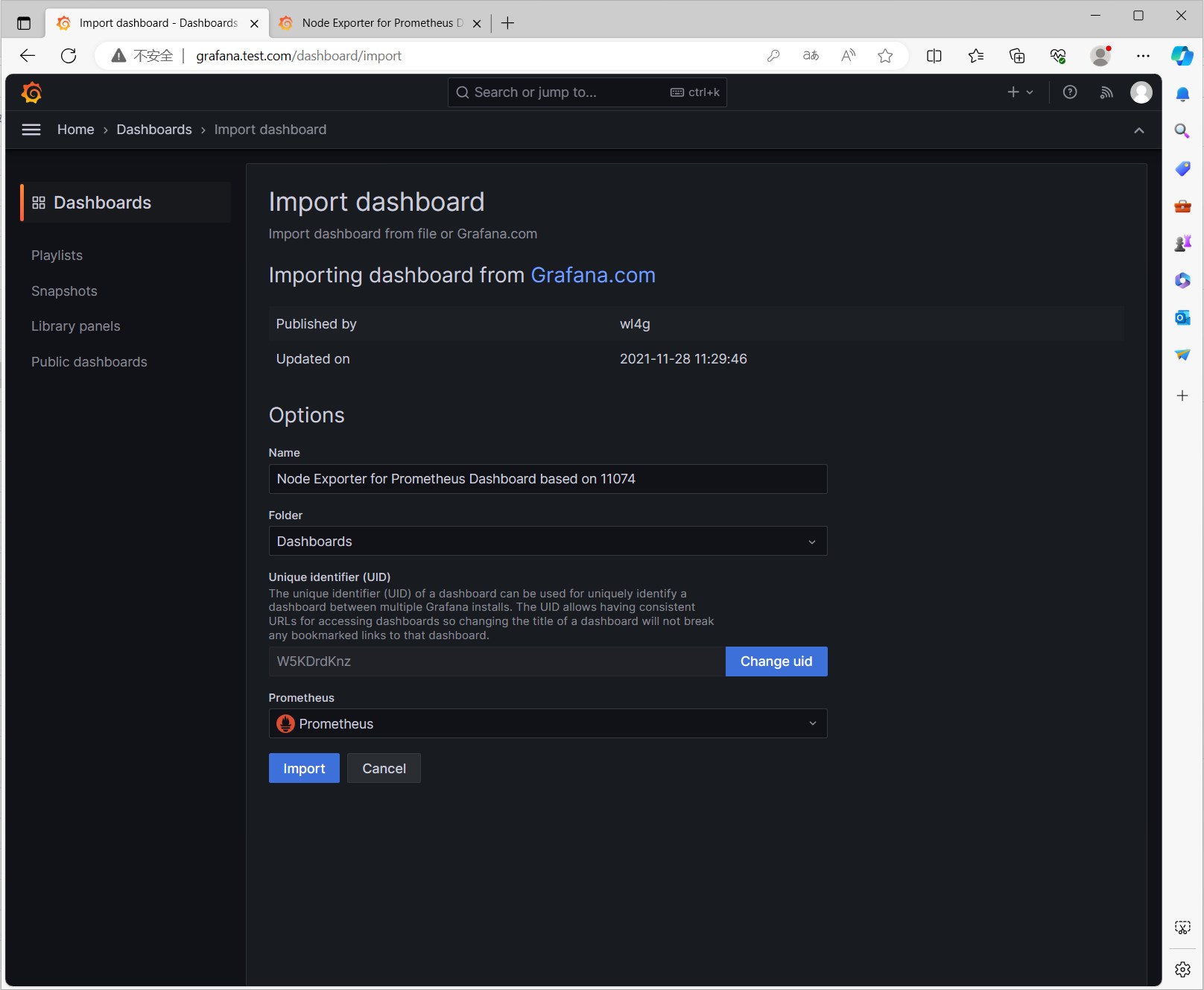
导入成功后,可以看到Dashboard的信息
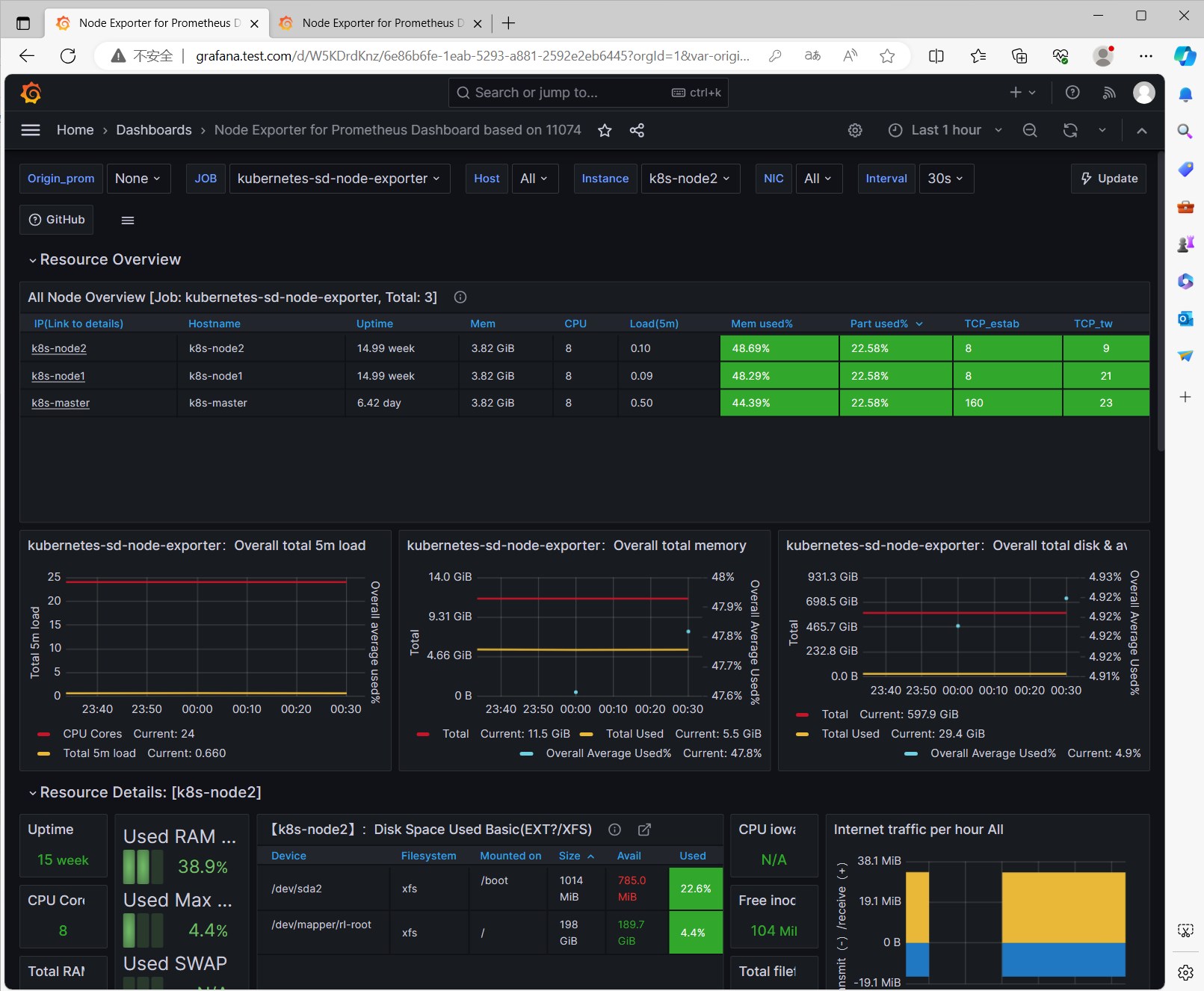
Kubernetes
按照上面的步骤搜索到Kubernetes的Dashboard,进入详情页面,可以看到Dashboard的ID为13105,我们可以通过这个ID来导入Dashboard。
安装完成后,我们可以看到Dashboard的信息
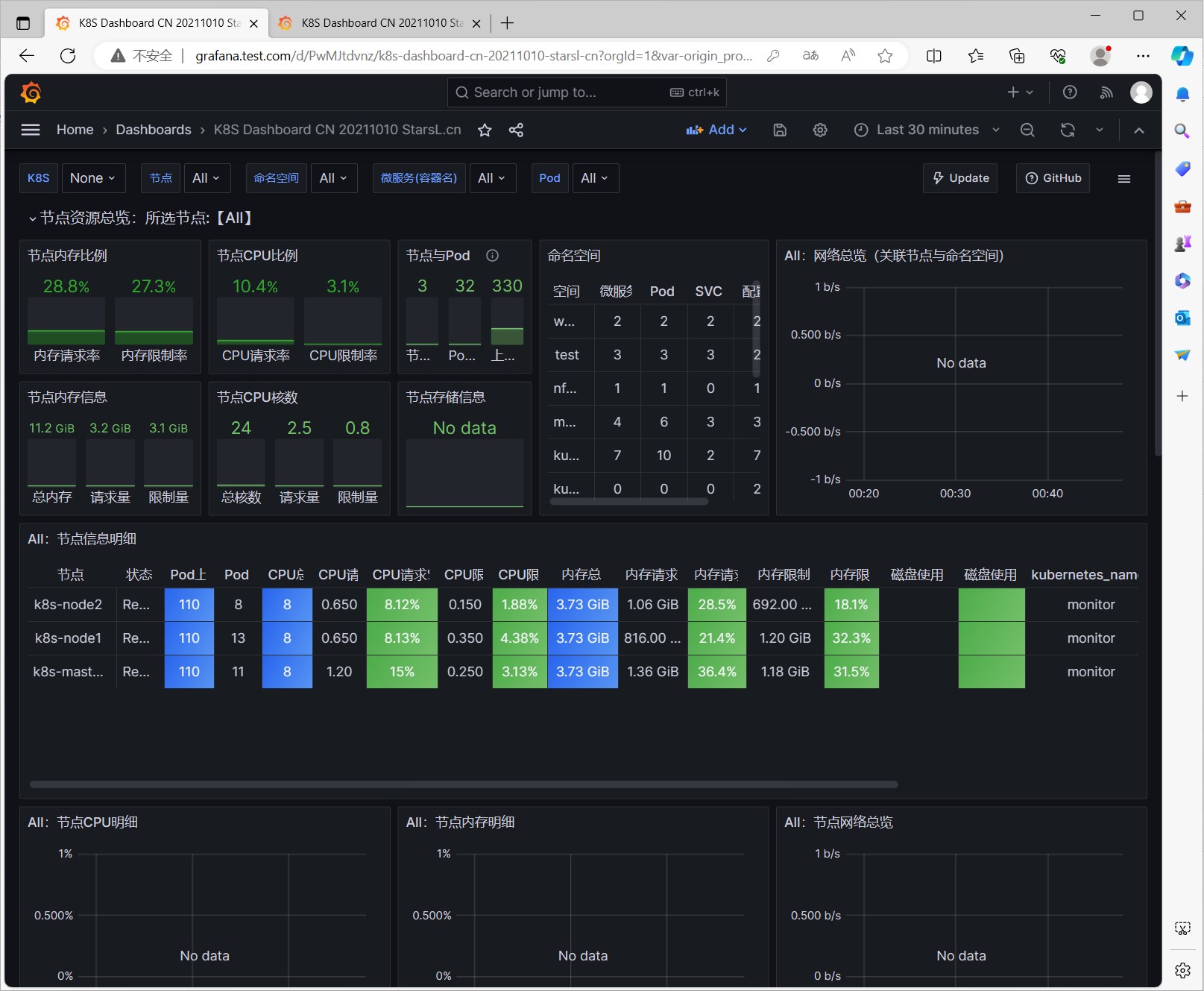
DevOpsProdigy KubeGraf插件的使用
除了直接导入Dashboard,我们还可以通过安装插件的方式获得,在侧边栏中点击Administartion -> Plugins,可以看到已经安装的插件,点击右上角的[Install]按钮,可以看到插件列表,我们可以在这里搜索到我们需要的插件。
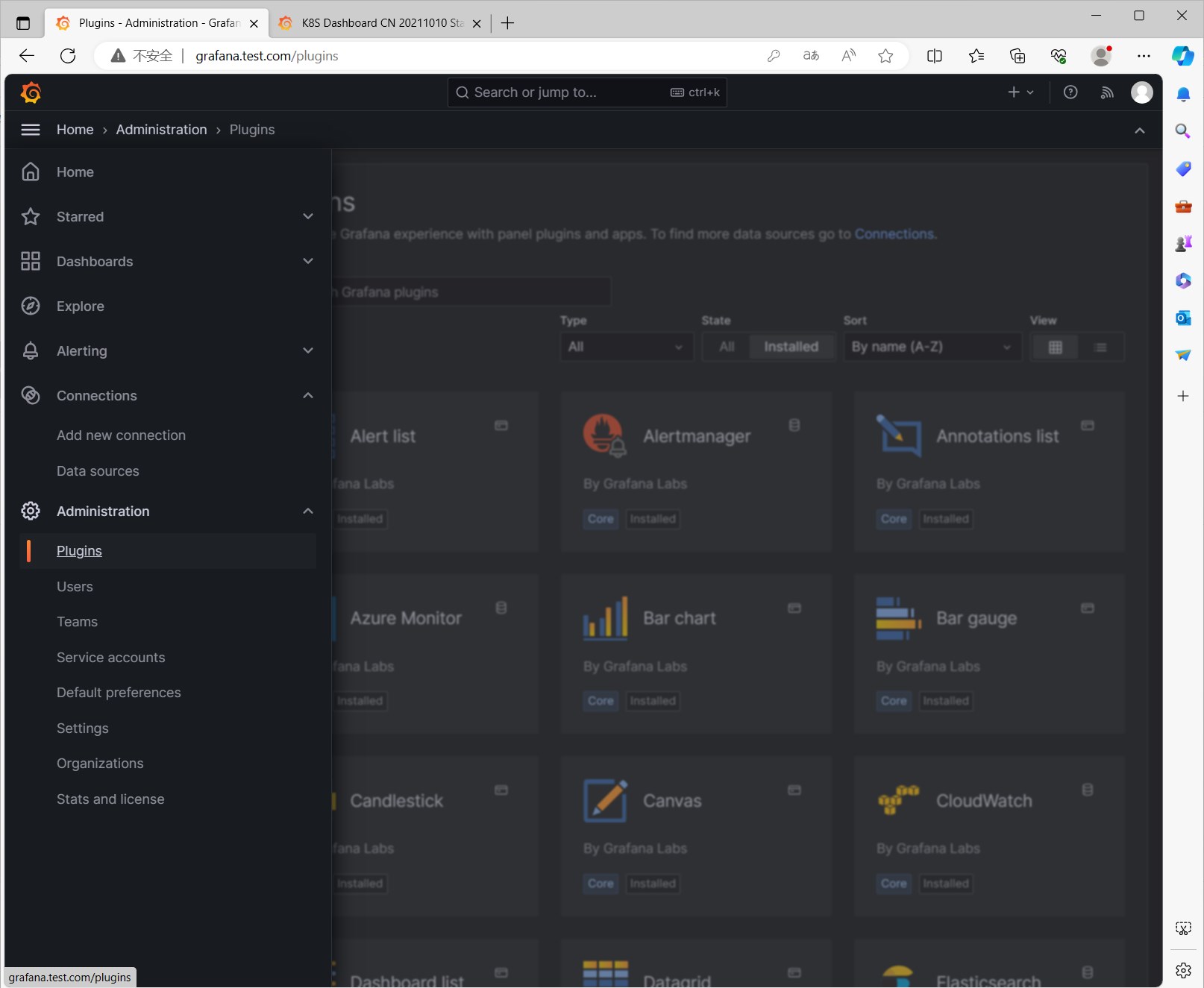
官方也提供了一些插件,我们可以在官方插件列表中找到需要的插件。
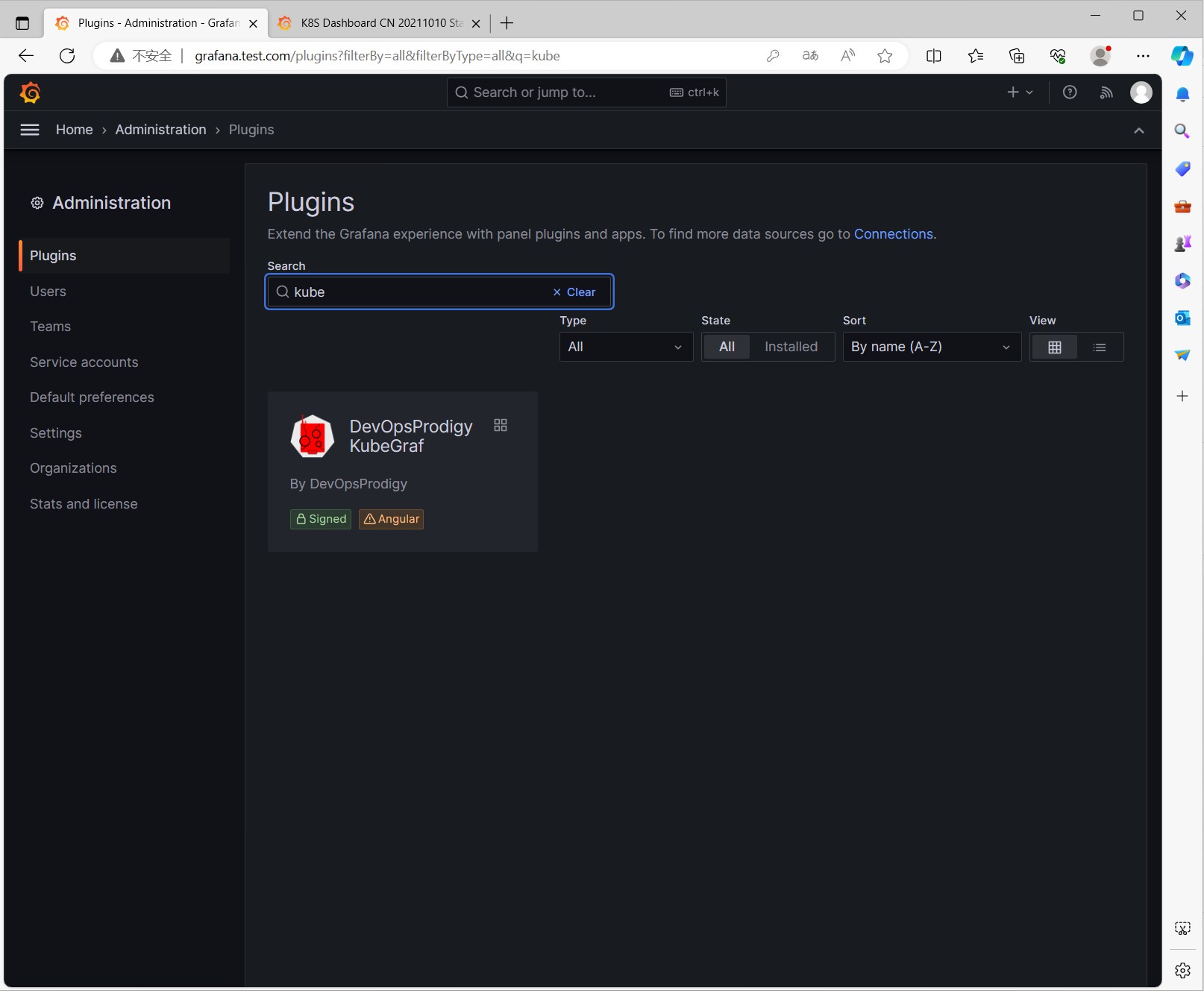
Kubernetes相关的插件:
DevOpsProdigy KubeGraf 是一个非常优秀的 Grafana Kubernetes 插件,是 Grafana 官方的 Kubernetes 插件的升级版本,该插件可以用来可视化和分析 Kubernetes 集群的性能,通过各种图形直观的展示了 Kubernetes 集群的主要服务的指标和特征,还可以用于检查应用程序的生命周期和错误日志。
我们可以通过安装插件的方式来安装这个插件,也可以通过导入Dashboard的方式来安装这个插件。

1 | # 进入grafana容器内部执行安装 |
这个插件已经被废弃了,以下为之前的安装方式,现在已经不适用了。
登录grafana界面,在 Plugins 中找到安装的插件,点击插件进入插件详情页面,点击 [Enable]按钮启用插件,点击 Set up your first k8s-cluster 创建一个新的 Kubernetes 集群:
- Name:test-k8s
- URL:https://kubernetes.default:443
- Access:使用默认的Server(default)
- Skip TLS Verify:勾选,跳过证书合法性校验
- Auth:勾选TLS Client Auth以及With CA Cert,勾选后会下面有三块证书内容需要填写,内容均来自
~/.kube/config文件,需要对文件中的内容做一次base64 解码- CA Cert:使用config文件中的
certificate-authority-data对应的内容 - Client Cert:使用config文件中的
client-certificate-data对应的内容 - Client Key:使用config文件中的
client-key-data对应的内容
- CA Cert:使用config文件中的
面板没有数据怎么办?
- DaemonSet
label_values(kube_pod_info{namespace=”$namespace”,pod=~”$daemonset-.*”},pod)- Deployment
label_values(kube_pod_info{namespace=”$namespace”,pod=~”$deployment-.*”},pod)- Pod
label_values(kube_pod_info{namespace=”$namespace”},pod)
自定义监控面板
通用的监控需求基本上都可以使用第三方的Dashboard来解决,对于业务应用自己实现的指标的监控面板,则需要我们手动进行创建。
点击[+]按钮,选择New Dashboard,进入新建Dashboard页面
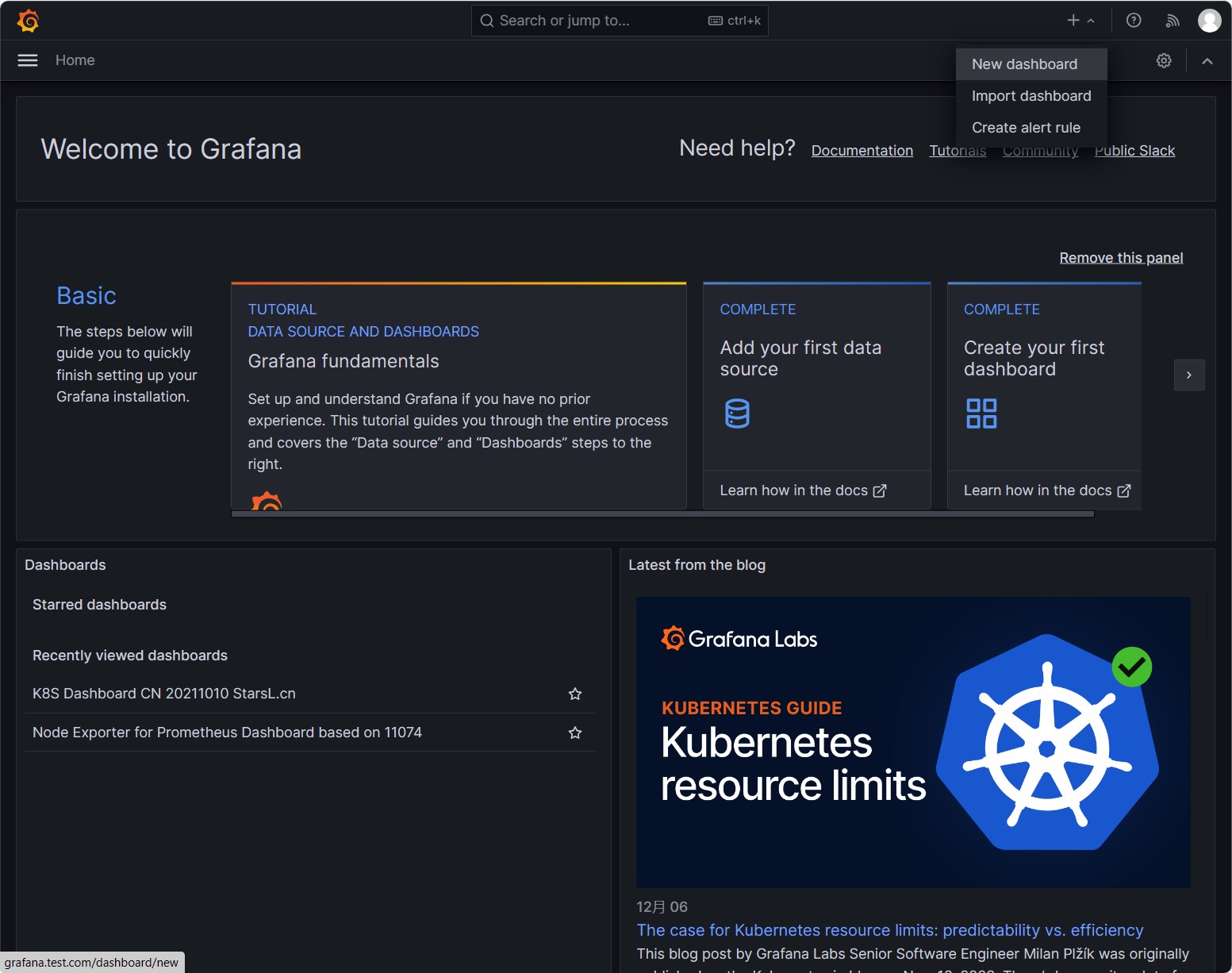
点击[Add visualizations]按钮,创建一个新的监控面板
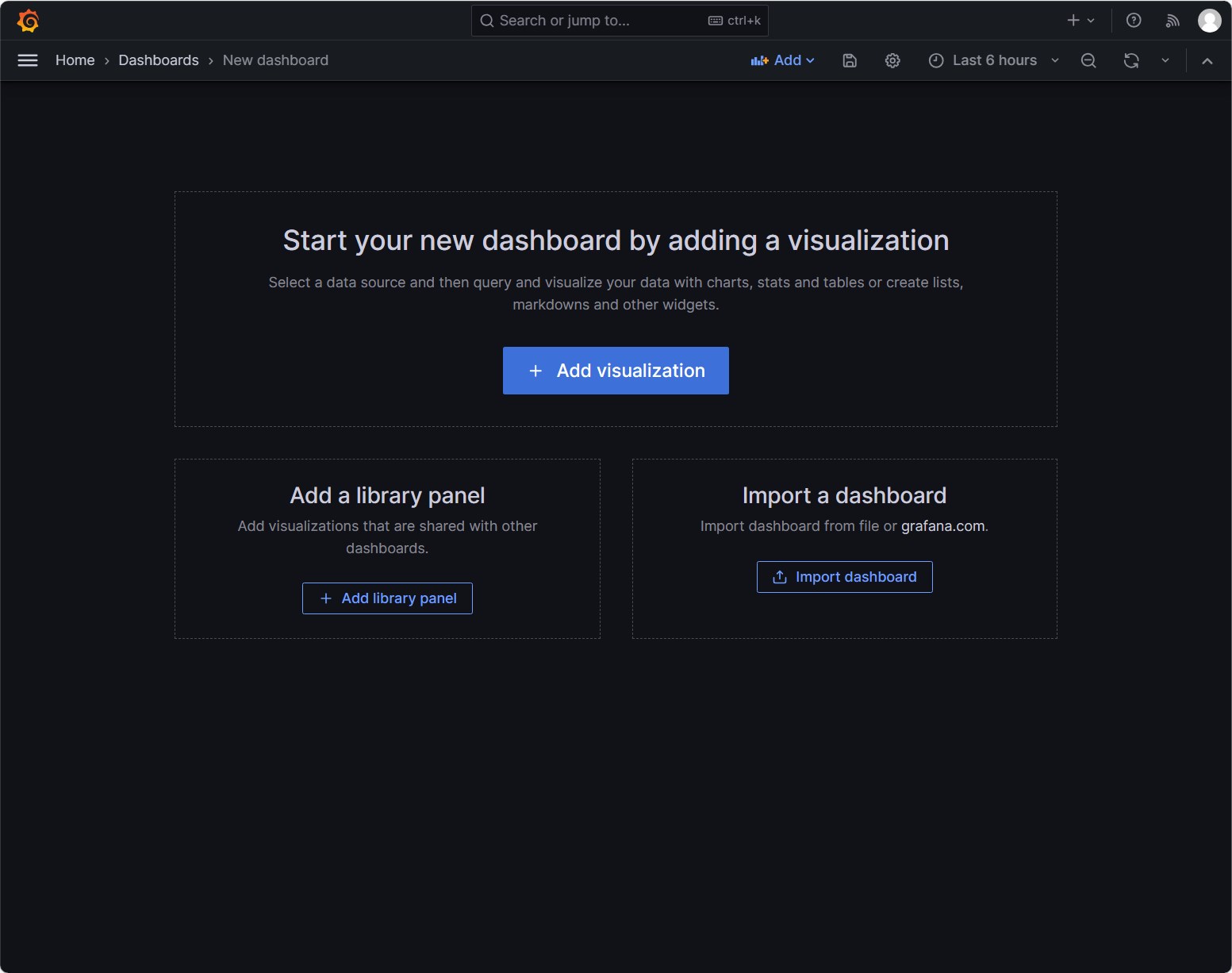
选择数据源,这里我们选择Prometheus
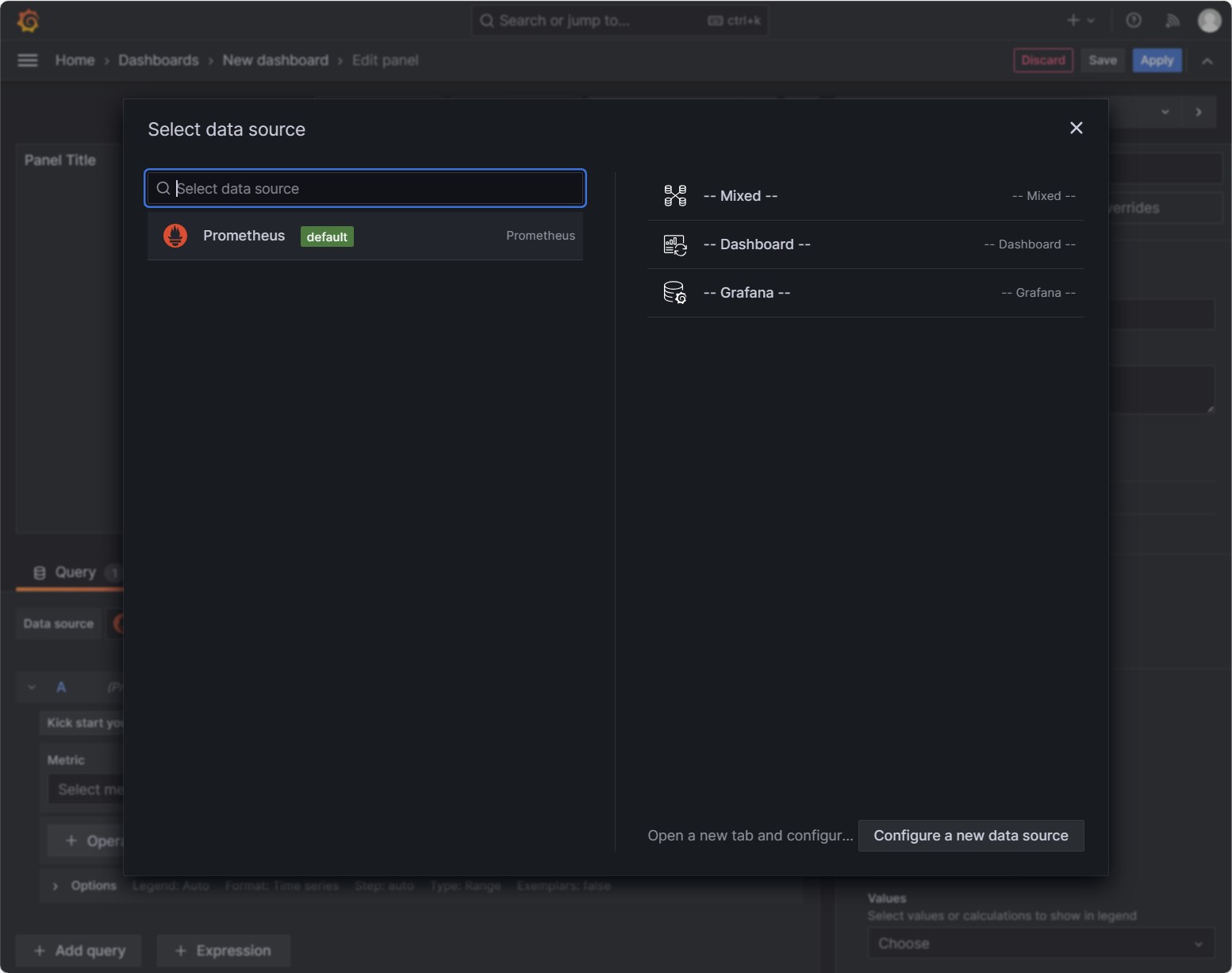
然后就可以开始创建监控面板了,这里我们创建一个监控节点CPU使用率的监控面板。
如何根据字段过滤,实现联动效果?比如想实现根据集群节点名称进行过滤,可以通过如下方式:
首先我们先apply监控面板
点击右上角的Edit按钮,进入编辑页面,选择Variables
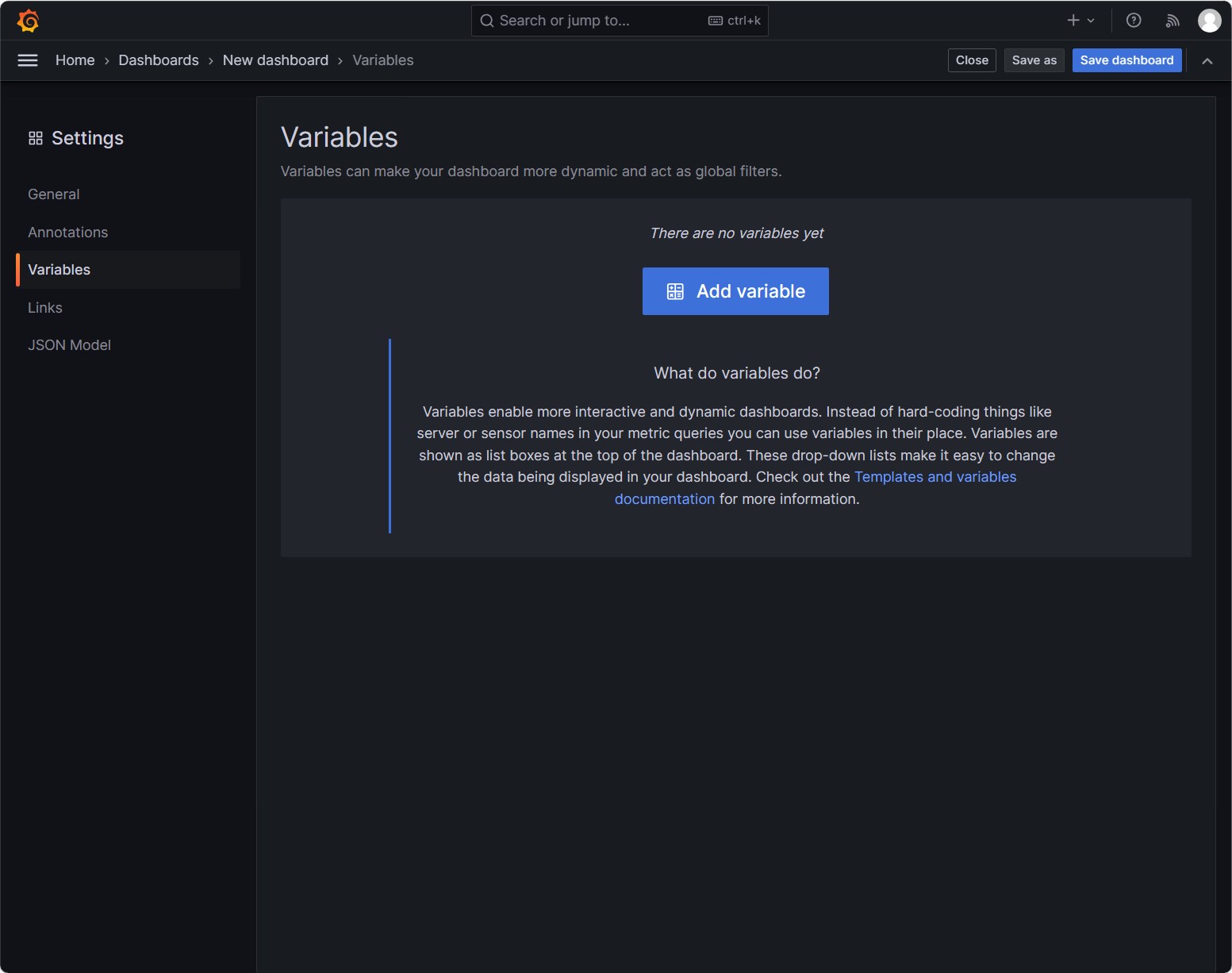
点击Add Variable,添加一个变量node
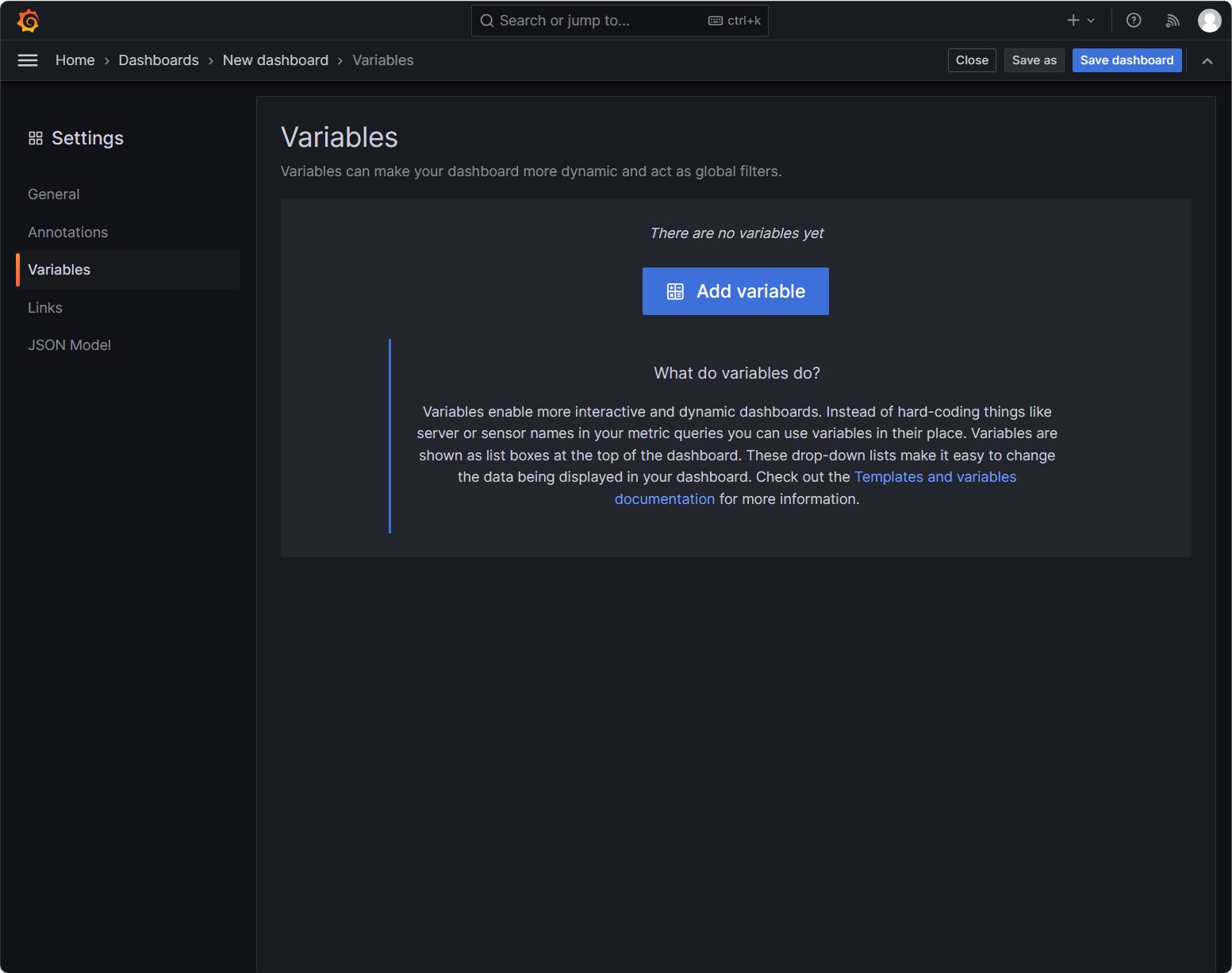
填写变量的信息
- Name:node
- Label:选择节点
- Data Source:Prometheus
- Query:
- Query type:Label values
- Label: node
- Metrics:kube_node_info
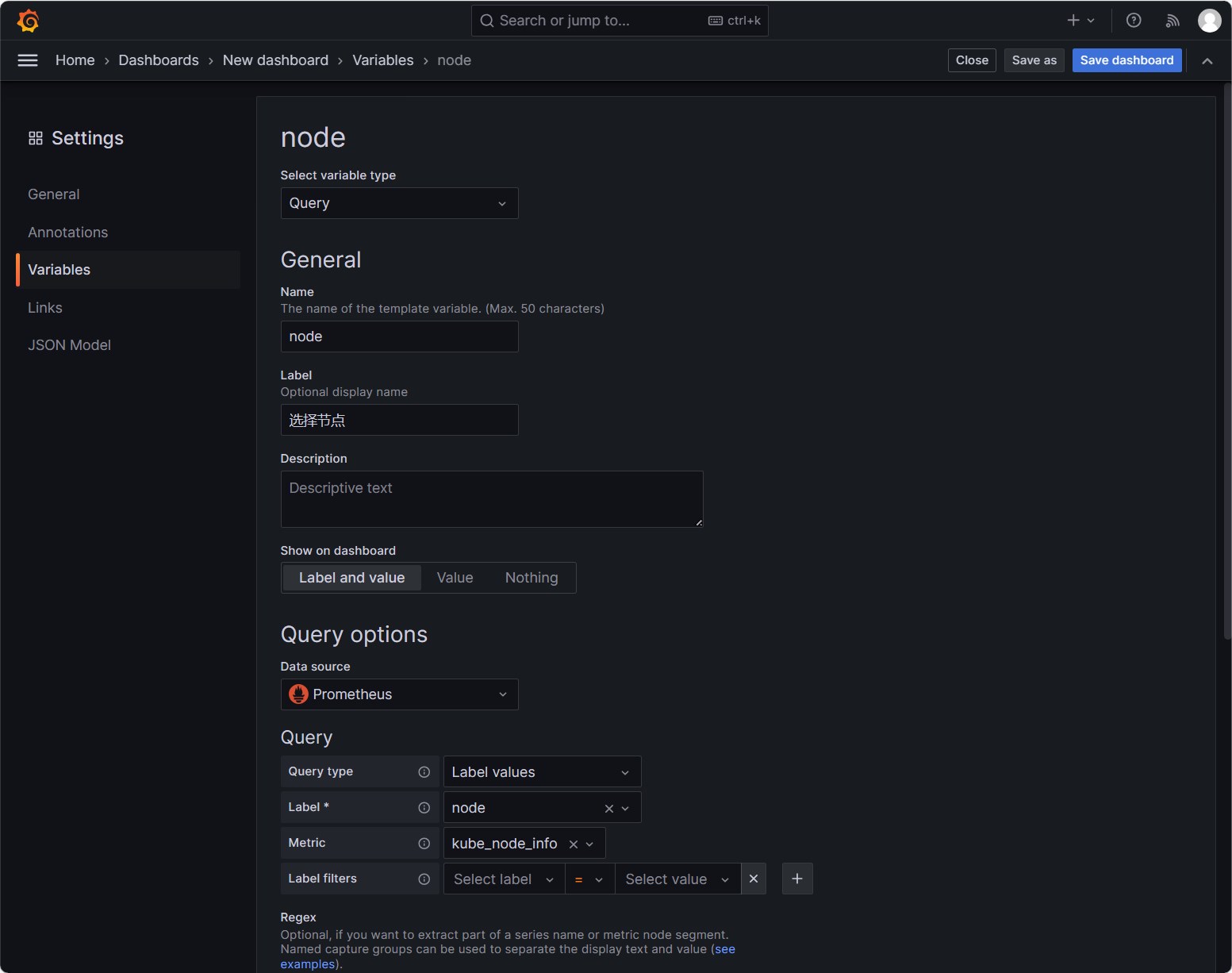
可以在页面下方的
Preview of values查看到当前变量的可选值,点击Apply按钮保存变量
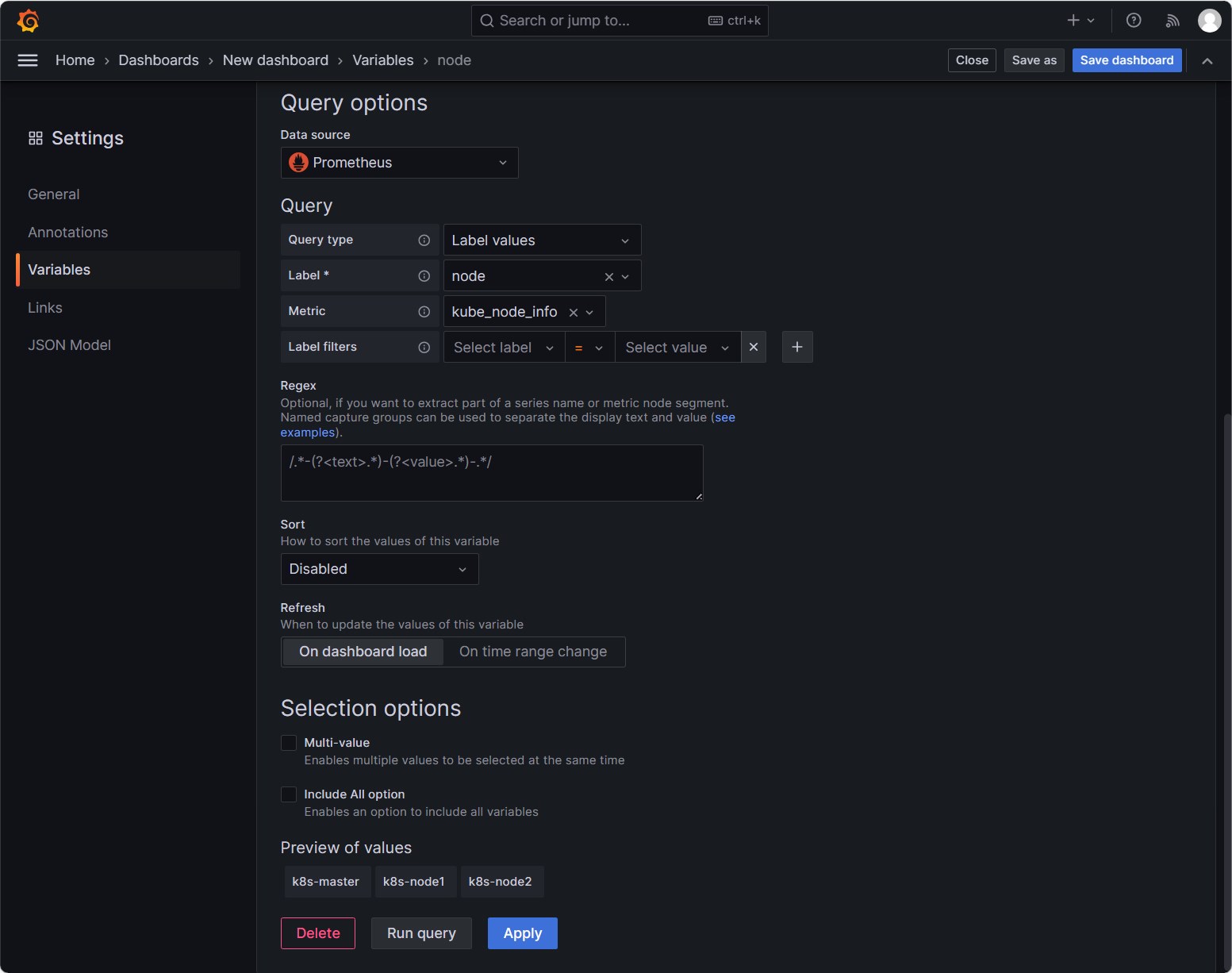
可以看到变量已经添加成功了
面板上方的变量选择框中,可以看到我们刚刚添加的变量
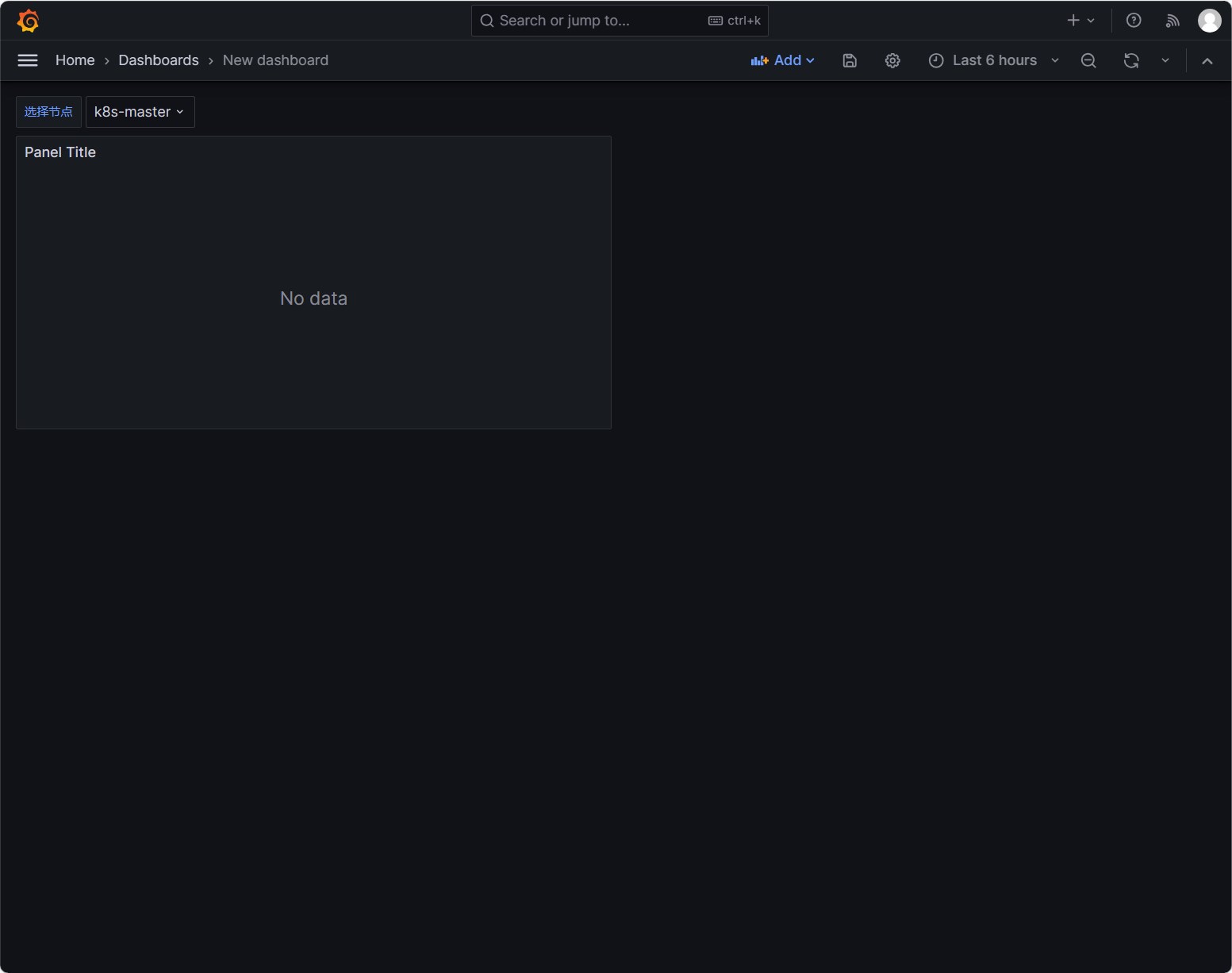
我们修改panel的Metrics,$node和变量名字保持一致,意思为自动读取当前设置的节点的名字
1
node_load1{instance=~"$node"}
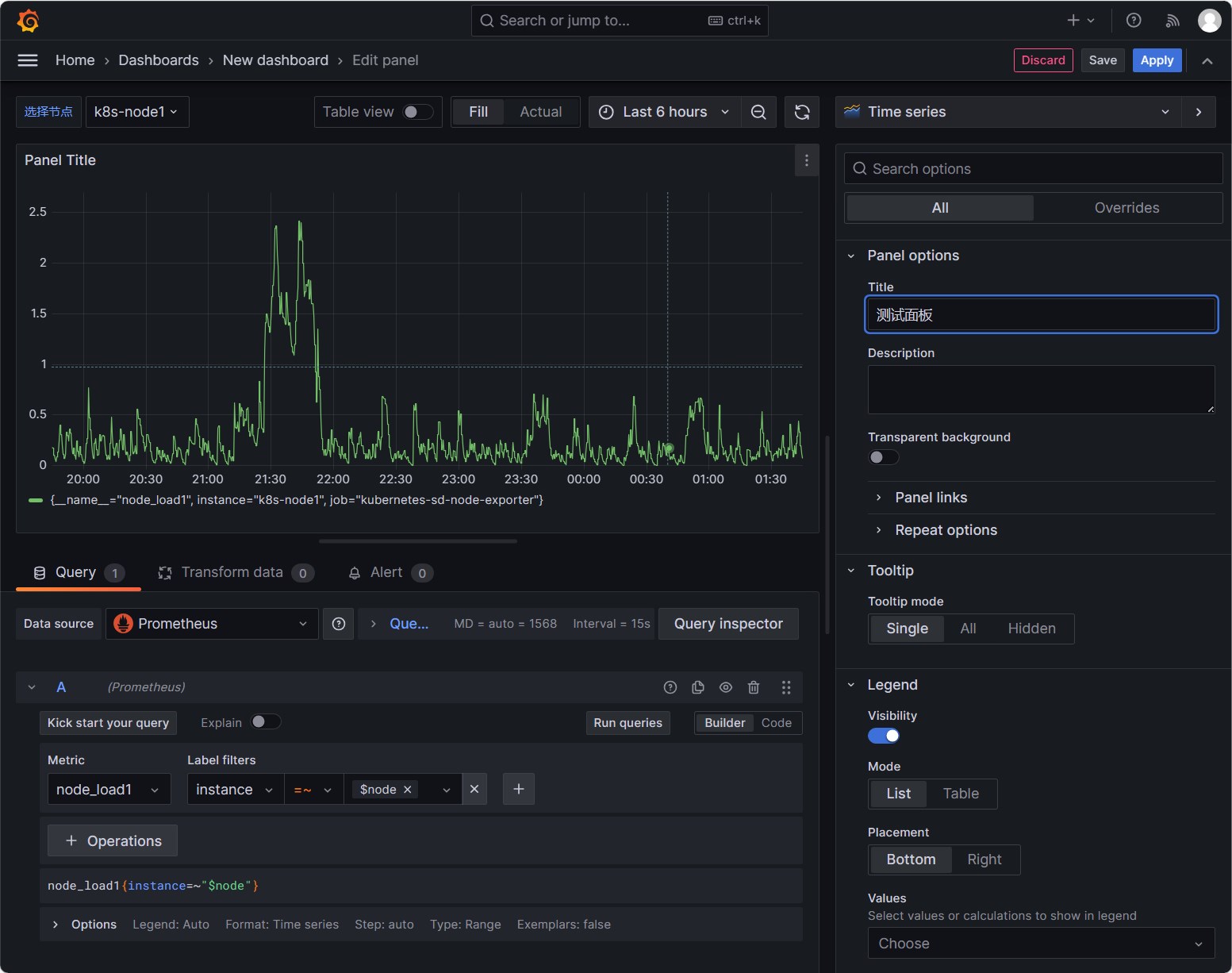
点击Apply按钮保存面板,可以看到面板已经有数据了
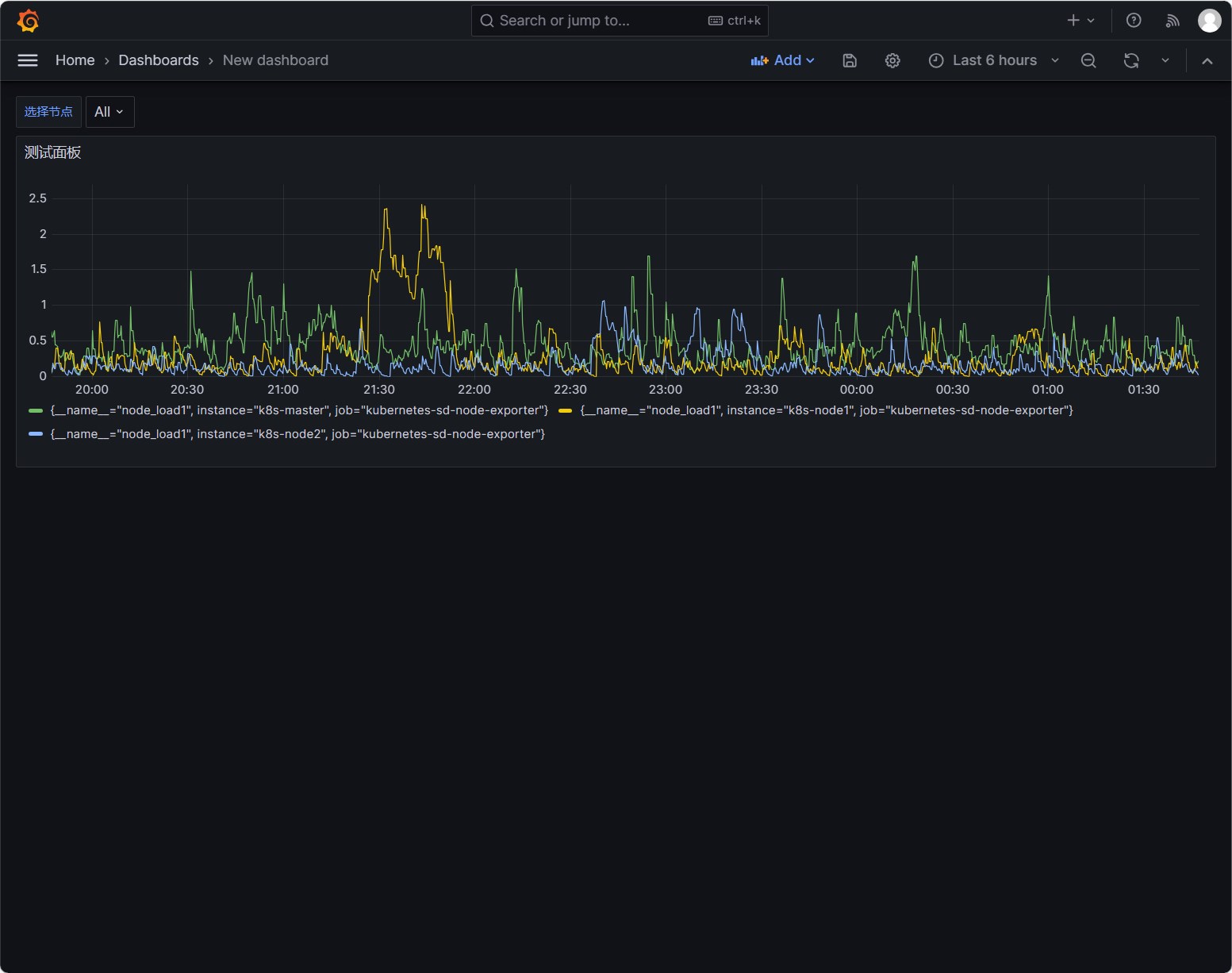
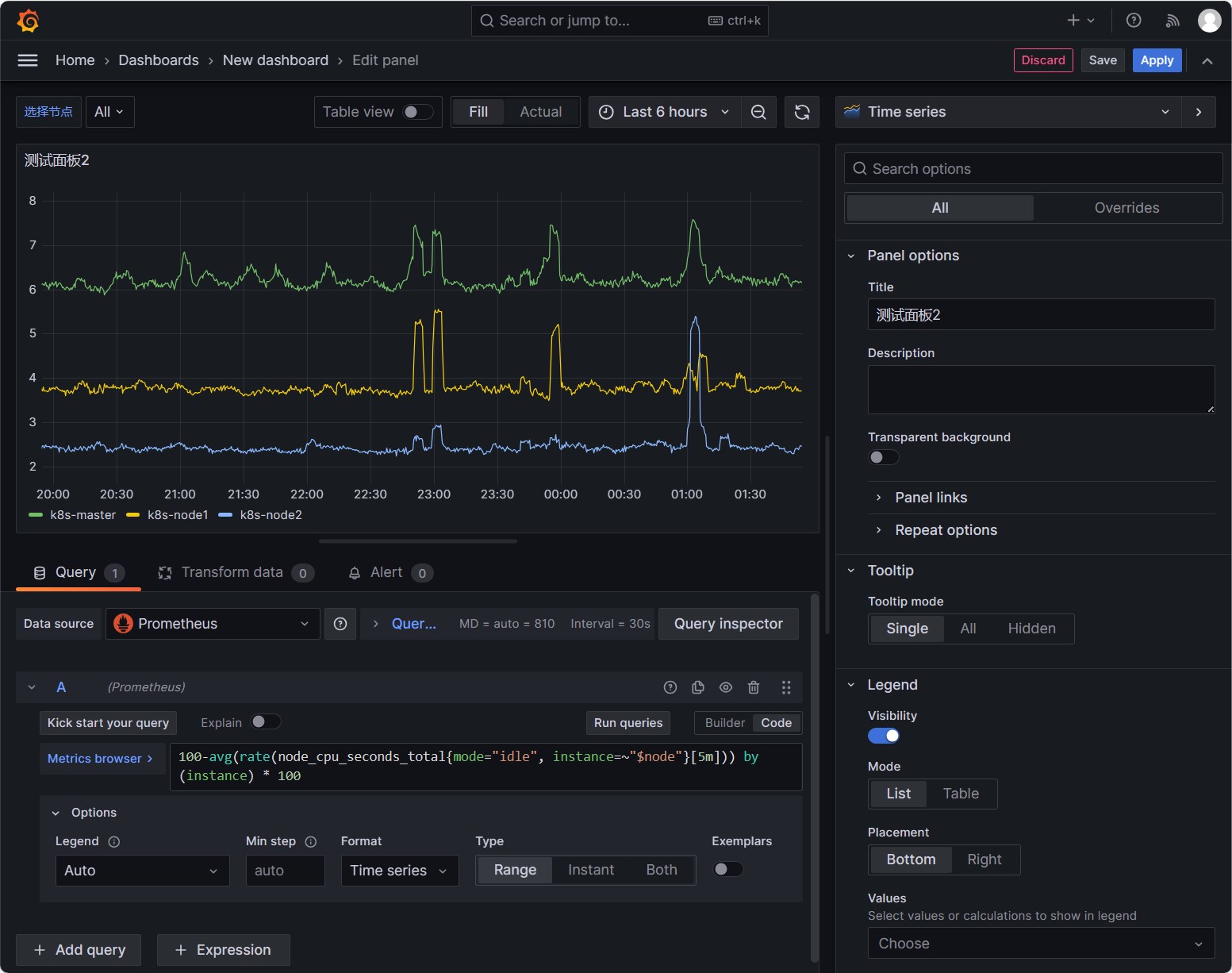
再添加一个面板,使用如下的表达式:
1
100-avg(irate(node_cpu_seconds_total{mode="idle",instance=~"$node"}[5m])) by (instance)*100
Metrics指标类型与PromQL
TSDB的样本分布示意图:
1 | ^ |
Prometheus的监控指标分为四种类型:
- Counter(计数器)
- 性质:表示单调递增的计数,通常用于表示事件发生的次数。
- 示例:HTTP请求数、任务启动次数等。node_cpu_seconds_total、http_requests_total、node_network_receive_bytes_total
- 用途:统计系统运行以来的总次数,如http请求总数、系统启动次数等
- 特性:只增不减,除非系统发生重置,Prometheus重启后会重置所有的Counter类型的指标
- Gauge(仪表盘)
- 性质:表示单个数值的度量值,通常用于表示系统的当前状态。也可以说表示可任意上升或下降的数值,用于测量瞬时值。
- 示例:node_memory_MemAvailable_bytes、node_load1、node_cpu_seconds_total
- 用途:反应系统的当前状态,如内存使用率、CPU利用率等。memory_usage_bytes、node_load1
- 特性:可增可减,表示一个瞬时值,常见的监控指标,如node_memory_MemAvailable_bytes、node_load1都是Gauge类型的监控指标
- Histogram(直方图)
- 性质:表示一组数据的分布情况,通常用于统计和分析数据的分布情况。
- 示例:请求持续时间、文件大小等。prometheus_http_request_duration_seconds_bucket
- 用途:统计和分析数据的分布情况,如http请求的响应时间分布情况
- 特性:通过分桶(bucket)和累积计数(cumulative count)表示一组数据的分布情况,常见的监控指标,如prometheus_http_request_duration_seconds_bucket都是Histogram类型的监控指标
- Summary(摘要)
- 性质:与直方图类似,用于观察和分析样本值的分布情况,但更适用于长时间运行的服务。通常用于统计和分析数据的分布情况。
- 示例:请求持续时间、文件大小等。http_request_duration_seconds
- 用途:统计和分析数据的分布情况,如http请求的响应时间分布情况
- 特性:通过样本值的分位数表示一组数据的分布情况,常见的监控指标,如http_request_duration_seconds都是Summary类型的监控指标
Guage类型
最常用类型的监控指标,如node_memory_MemAvailable_bytes、node_load1都是Gauge类型的监控指标。
Gauge类型的指标侧重于反应系统的当前状态。
- 这类指标的样本数据可增可减。
- 常见指标如:node_memory_MemAvailable_bytes(可用内存大小)、node_load1(系统平均负载)
1 | $ kubectl -n monitor get po -o wide | grep k8s-master |
Guage类型的数据,通常直接查询就会有比较直观的业务含义,比如:
- node_load5
- node_memory_MemAvailable_bytes
我们也会对这类数据做简单的处理,比如:
- 过滤其中某些节点
- 对指标进行数学运算
这就是PromQL提供的能力,可以对收集到的数据做聚合、计算等处理。
PromQL( Prometheus Query Language )是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。
比如以下几种:
只显示k8s-master节点的平均负载
1
node_load1{instance="k8s-master"}
显示除了k8s-master节点外的其他节点的平均负载
1
node_load1{instance!="k8s-master"}
显示过去一段时间内的样本数据
1
node_load1[5m]
使用系统方法对数据进行处理
1
avg(node_cpu_seconds_total{mode="system", instance="k8s-master"}) by (instance)
正则匹配
1
node_load1{instance=~"k8s-master|k8s-slave1"}
集群各节点系统内存使用率
1
((node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes))/node_memory_MemTotal_bytes)*100
Counter类型:
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu_seconds_total都是Counter类型的监控指标。
通常计数器类型的指标,名称后面都以_total结尾。我们通过理解CPU利用率的PromQL表达式来讲解Counter指标类型的使用。
1 | $ curl -s 192.168.100.1:9100/metrics | grep node_cpu_seconds_total |
我们通过一个示例来说明Counter类型的指标如何使用以及PromQL的使用。 这个例子是计算各节点CPU的平均使用率表达式,具体如下:
1 | (1- sum(increase(node_cpu_seconds_total{mode="idle"}[2m])) by (instance) / sum(increase(node_cpu_seconds_total{}[2m])) by (instance)) * 100 |
接下来我们来分析一下这个表达式:
node_cpu_seconds_total的指标含义是统计系统运行以来,CPU资源分配的时间总数,单位为秒,是累加的值。
我们在Prometheus中查询这个指标,可以看到很多结果,显示的是所有节点、所有CPU核心、在各种工作模式下分配的时间总和。
其中mode的值和我们平常在系统中执行top命令看到的CPU显示的信息一致,每个mode对应的含义如下:
user(us) 表示用户态空间或者说是用户进程(running user space processes)使用CPU所耗费的时间。这是日常我们部署的应用所在的层面,最常见常用。system(sy) 表示内核态层级使用CPU所耗费的时间。分配内存、IO操作、创建子进程……都是内核操作。这也表明,当IO操作频繁时,System参数会很高。steal(st) 当运行在虚拟化环境中,花费在其它 OS 中的时间(基于虚拟机监视器 hypervisor 的调度);可以理解成由于虚拟机调度器将 cpu 时间用于其它 OS 了,故当前 OS 无法使用 CPU 的时间。softirq(si) 从系统启动开始,累计到当前时刻,软中断时间irq(hi) 从系统启动开始,累计到当前时刻,硬中断时间nice(ni) 从系统启动开始,累计到当前时刻, 低优先级(低优先级意味着进程 nice 值小于 0)用户态的进程所占用的CPU时间iowait(wa) 从系统启动开始,累计到当前时刻,IO等待时间idle(id) 从系统启动开始,累计到当前时刻,除IO等待时间以外的其它等待时间,亦即空闲时间
我们通过指标拿到的各核心cpu分配的总时长数据,都是瞬时的数据,如何转换成 CPU的利用率?
先来考虑如何我们如何计算CPU利用率,假如我的k8s-master节点是4核CPU,我们来考虑如下场景:
- 过去60秒内每个CPU核心处于idle空闲状态的时长,假如分别为 :
- cpu0:20s
- cpu1:30s
- cpu2:50s
- cpu3:40s
- 则四个核心总共可分配的时长是 4*60=240s
- 实际空闲状态的总时长为20+30+50+40=140s
- 那么我们可以计算出过去1分钟k8s-master节点的CPU利用率为 (1- 140/240) * 100 = 41.7%
因此,我们只需要使用PromQL取出上述过程中的值即可:
1 | # 过滤出当前时间点idle的时长 |
除此之外,还会经常看到avg,irate和rate方法的使用:
irate() 是基于最后两个数据点计算一个时序指标在一个范围内的每秒递增率 ,举个例子:
1 | # 1min内,k8s-master节点的idle状态的cpu分配时长增量值 |
因此rate的值,相对来讲更平滑,因为计算的是时间段内的平均,更适合于用作告警。
取CPU平均使用率也可以用如下表达式表示:(1 - avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) * 100
Alertmanager
Alertmanager是一个独立的告警模块,主要作用有以下几点:
- 接收Prometheus等客户端发来的警报
- 通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;
- 告警方式可以按照不同的规则发送给不同的模块负责人。Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
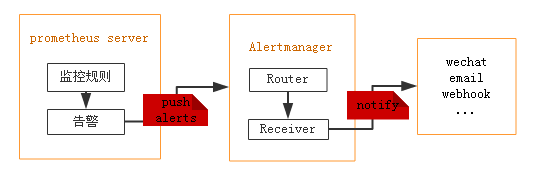
如果集群主机的内存使用率超过80%,且该现象持续了2分钟?想实现这样的监控告警,如何做?
从上图可得知设置警报和通知的主要步骤是:
- 安装和配置 Alertmanager
- 配置Prometheus与Alertmanager对话
- 在Prometheus中创建警报规则
安装
alertmanager的安装方式可以参考官方仓库,但是这里我们使用helm来安装。
1 | $ helm pull prometheus-community/alertmanager |
修改的values.yaml文件内容如下:
1 | ...... |
其中config字段中的内容是alertmanager的主要配置,它的作用如下:
- global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
- route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
- receivers: 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
当alertmanager接收到一条新的alert时,会先根据group_by为其确定一个聚合组group,然后等待group_wait时间,如果在此期间接收到同一group的其他alert,则这些alert会被合并,然后再发送(alertmanager发送消息单位是group)。此参数的作用是防止短时间内出现大量告警的情况下,接收者被告警淹没。
在该组的alert第一次被发送后,该组会进入睡眠/唤醒周期,睡眠周期将持续group_interval时间,在睡眠状态下该group不会进行任何发送告警的操作(但会插入/更新(根据fingerprint)group中的内容),睡眠结束后进入唤醒状态,然后检查是否需要发送新的alert或者重复已发送的alert(resolved类型的alert在发送完后会从group中剔除)。这就是group_interval的作用。
聚合组在每次唤醒才会检查上一次发送alert是否已经超过repeat_interval时间,如果超过则再次发送该告警。
配置Prometheus与Alertmanager对话
是否告警是由Prometheus进行判断的,若有告警产生,Prometheus会将告警push到Alertmanager,因此,需要在Prometheus端配置alertmanager的地址:
1 | $ kubectl -n monitor edit configmap prometheus-config |
到这里已经安装了alertmanager,也配置了Prometheus与Alertmanager对话,接下来就是配置告警规则了。
配置告警规则
目前Prometheus与Alertmanager已经连通,接下来我们可以针对收集到的各类指标配置报警规则,一旦满足报警规则的设置,则Prometheus将报警信息推送给Alertmanager,进而转发到我们配置的邮件中。
在哪里配置?同样是在prometheus-configmap中配置。我们配置报警文件的路径,然后使用configmap的方式,将报警规则文件挂载到prometheus容器内部。
1 | $ kuectl -n monitor edit configmap prometheus-config |
告警规则的几个要素:
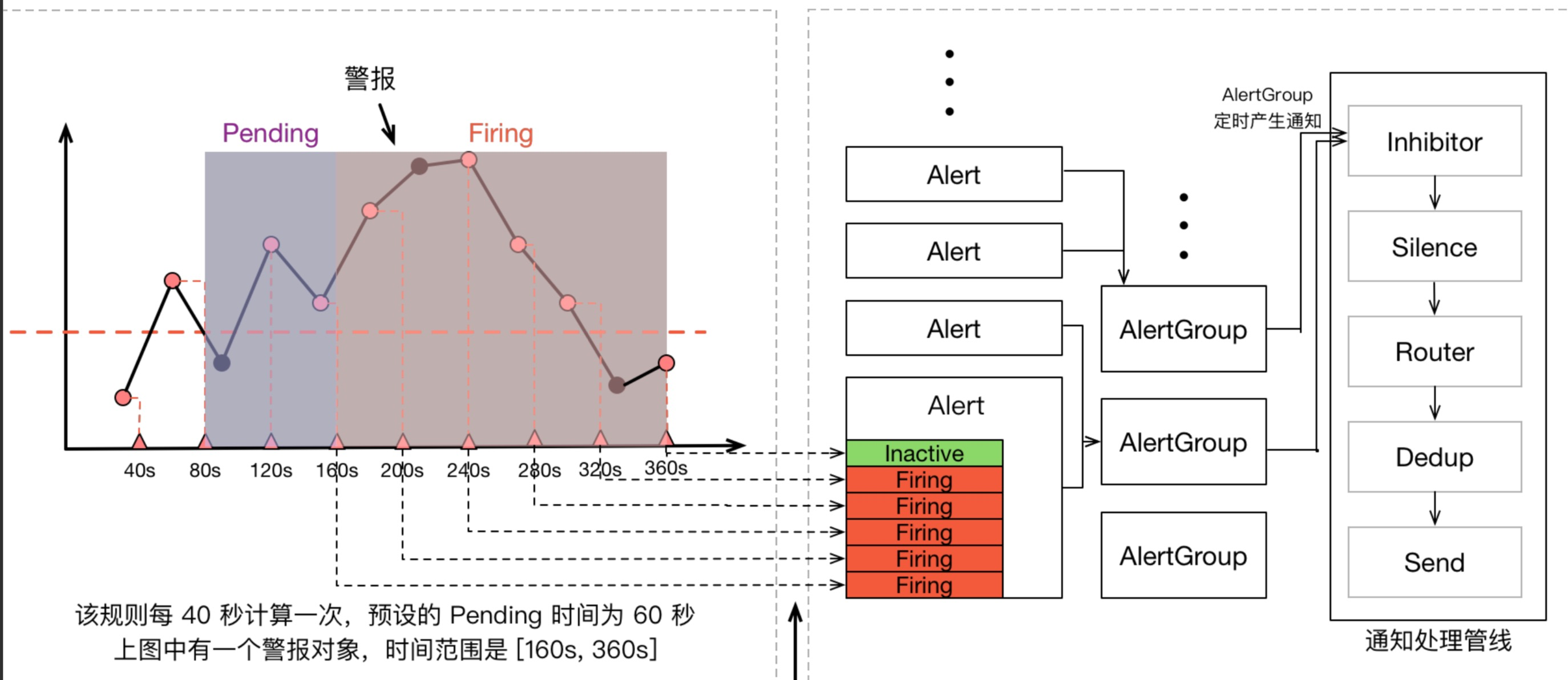
group.name:告警分组的名称,一个组下可以配置一类告警规则,比如都是物理节点相关的告警alert:告警规则的名称expr:是用于进行报警规则 PromQL 查询语句,expr通常是布尔表达式,可以让Prometheus根据计算的指标值做 true or false 的判断for:评估等待时间(Pending Duration),用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending,屏蔽掉瞬时的问题,把焦点放在真正有持续影响的问题上labels:自定义标签,允许用户指定额外的标签列表,把它们附加在告警上,可以用于后面做路由判断,通知到不同的终端,通常被用于添加告警级别的标签annotations:指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的
规则配置中,支持模板的方式,其中:
{{$labels}}可以获取当前指标的所有标签,支持{{$labels.instance}}或者{{$labels.job}}这种形式{{ $value }}可以获取当前计算出的指标值
一个报警信息在生命周期内有下面3种状态:
inactive: 表示当前报警信息处于非活动状态,即不满足报警条件pending: 表示在设置的阈值时间范围内被激活了,即满足报警条件,但是还在观察期内firing: 表示超过设置的阈值时间被激活了,即满足报警条件,且报警触发时间超过了观察期,会发送到Alertmanager端
对于已经 pending 或者 firing 的告警,Prometheus 也会将它们存储到时间序列ALERTS{}中。当然我们也可以通过表达式去查询告警实例:
1 | ALERTS{} |
自定义webhook实现告警消息的推送
目前官方内置的第三方通知集成包括:邮件、 即时通讯软件(如Slack、Hipchat)、移动应用消息推送(如Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops)。可以在alertmanager的管理界面中查看到。
每一个receiver具有一个全局唯一的名称,并且对应一个或者多个通知方式:
1 | name: <string> |
如果想实现告警消息推送给企业常用的即时聊天工具,如钉钉或者企业微信,如何配置?
Alertmanager的通知方式中还可以支持Webhook,通过这种方式开发者可以实现更多个性化的扩展支持,配置的格式如下:
1 | # 警报接收者 |
当我们配置了上述webhook地址,则当告警路由到alertmanager时,alertmanager端会向webhook地址推送POST请求:
1 | $ curl -X POST -d"$demoAlerts" http://demo-webhook/alert/send |
因此,假如我们想把报警消息自动推送到钉钉群聊,只需要完成3个步骤:
- 创建一个能给钉钉群聊发送消息的钉钉机器人
- 实现一个数据解析的容器,将Alertmanager传过来的数据做解析,成为钉钉机器人能够识别的格式,然后调用钉钉机器人的API,实现消息推送
- 配置alertmanager的receiver为webhook地址
首先,我们要想给钉钉群聊发送消息,需要创建一个钉钉机器人,按照以下步骤创建。
- 登录钉钉群
- 点击群设置
- 选择机器人管理
- 然后选择自定义机器人
- 创建一个机器人
- 选择自定义关键词
- 然后输入关键词
- 点击完成,即可创建一个机器人
- 创建完成后,会生成一个webhook地址,这个地址就是钉钉机器人的访问地址,后面我们会使用到
接下来,我们试一下钉钉机器人的API,看看如何给钉钉群聊发送消息。
1 | $ curl 'https://oapi.dingtalk.com/robot/send?access_token=f628f749a7ad70e86ca7bcb68658d0ce5af7c201ce8ce32acaece4c592364ca9' \ |
再然后我们就需要一个容器,来实现Alertmanager传过来的数据解析,然后调用钉钉机器人的API,实现消息推送。这里我们选择使用项目:prometheus-webhook-dingtalk
项目也有docker镜像,镜像地址:timonwong/prometheus-webhook-dingtalk:master
这个项目的二进制运行方式为:
1 | $ ./prometheus-webhook-dingtalk --config.file=config.yml |
假如使用如下配置:
1 | targets: |
则prometheus-webhook-dingtalk启动后会自动支持如下API的POST访问:
1 | http://locahost:8060/dingtalk/webhook_dev/send |
这样可以使用一个prometheus-webhook-dingtalk来实现多个钉钉群的webhook地址
那么我们来部署一下prometheus-webhook-dingtalk,从项目的Dockerfile可以得知需要注意以下几点:
- 默认使用配置文件
/etc/prometheus-webhook-dingtalk/config.yml,可以通过configmap挂载 - 该目录下还有模板文件,因此需要使用subpath的方式挂载
- 部署Service,作为Alertmanager的默认访问,服务端口默认8060
首先准备配置文件的资源清单,通过configmap挂载:
1 | $ cat webhook-dingtalk-configmap.yaml |
准备Deployment和Service的资源清单:
1 | $ cat webhook-dingtalk-deploy.yaml |
创建资源清单并部署prometheus-webhook-dingtalk:
1 | $ kubectl apply -f webhook-dingtalk-configmap.yaml |
一切准备就绪了,接下来就可以修改Alertmanager路由及webhook配置了:
1 | $ kubectl -n monitor edit configmap alertmanager |
验证钉钉消息是否正常收到。
基于Label的动态告警处理
真实的场景中,我们往往期望可以给告警设置级别,而且可以实现不同的报警级别可以由不同的receiver接收告警消息。
Alertmanager中路由负责对告警信息进行分组匹配,并向告警接收器发送通知。告警接收器可以通过以下形式进行配置:
1 | routes: |
因此可以为了更全面的感受报警的逻辑,我们再添加两个报警规则,并且它们通过labels字段打标签:
1 | alert_rules.yml: | |
我们为不同的报警规则设置了不同的标签,如severity: critical,针对规则中的label,来配置alertmanager路由规则,实现转发给不同的接收者。
1 | $ cat alertmanager-configmap.yaml |
再配置一个钉钉机器人,修改webhook-dingtalk的配置,添加webhook_ops的配置:
1 | $ cat webhook-dingtalk-configmap.yaml |
分别更新Prometheus和Alertmanager配置,查看报警的发送。
抑制和静默
前面我们知道,告警的group(分组)功能通过把多条告警数据聚合,有效的减少告警的频繁发送。除此之外,Alertmanager还支持Inhibition(抑制)和Silences(静默),帮助我们抑制或者屏蔽报警。
Inhibition 抑制
抑制是当出现其它告警的时候压制当前告警的通知,可以有效的防止告警风暴。
比如当机房出现网络故障时,所有服务都将不可用而产生大量服务不可用告警,但这些警告并不能反映真实问题在哪,真正需要发出的应该是网络故障告警。当出现网络故障告警的时候,应当抑制服务不可用告警的通知。
在Alertmanager配置文件中,使用inhibit_rules定义一组告警的抑制规则:
1 | inhibit_rules: |
每一条抑制规则的具体配置如下:
1 | target_match: |
当已经发送的告警通知匹配到target_match或者target_match_re规则,当有新的告警规则如果满足source_match或者定义的匹配规则,并且已发送的告警与新产生的告警中equal定义的标签完全相同,则启动抑制机制,新的告警不会发送。
例如,定义如下抑制规则:
1 | - source_match: |
如当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别severity=critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签node的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。
演示:实现如果 NodeMemoryUsage 报警触发,则抑制NodeLoad指标规则引起的报警。
1 | inhibit_rules: |
Silences: 静默
简单直接的在指定时段关闭告警。静默通过匹配器(Matcher)来配置,类似于路由树。警告进入系统的时候会检查它是否匹配某条静默规则,如果是则该警告的通知将忽略。静默规则在Alertmanager的Web界面里配置。
告警的生命周期
一条告警产生后,还要经过 Alertmanager 的分组、抑制处理、静默处理、去重处理和降噪处理最后再发送给接收者。这个过程中可能会因为各种原因会导致告警产生了却最终没有进行通知,可以通过下图了解整个告警的生命周期:
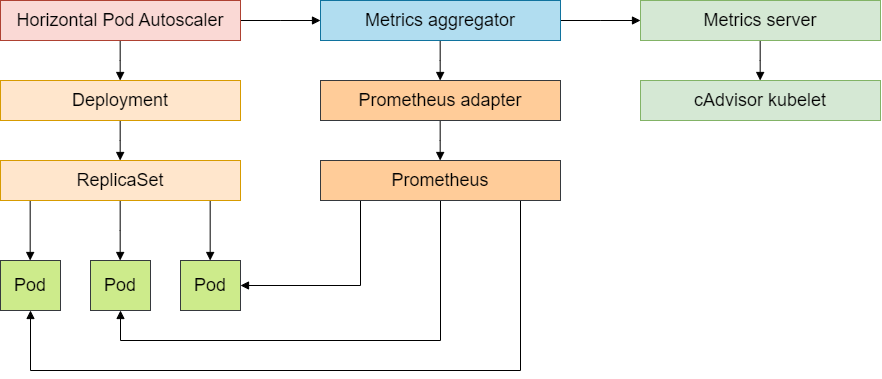
自定义指标实现业务伸缩
Kubernetes Metrics API体系回顾
前面章节,我们讲过基于CPU和内存的HPA,即利用metrics-server及HPA,可以实现业务服务可以根据pod的cpu和内存进行弹性伸缩。
k8s对监控接口进行了标准化:
- Resource Metrics 对应的接口是 metrics.k8s.io,主要的实现就是 metrics-server
- Custom Metrics 对应的接口是 custom.metrics.k8s.io,主要的实现是 Prometheus, 它提供的是资源监控和自定义监控
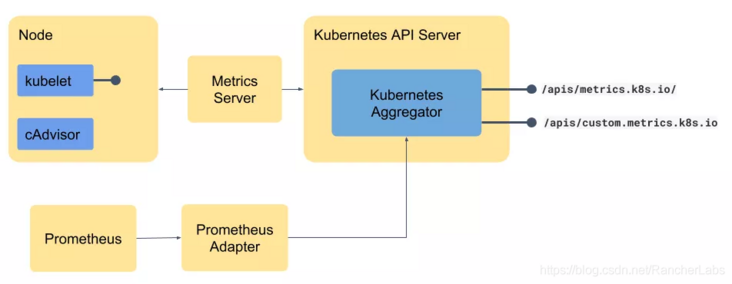
安装完metrics-server后,利用kube-aggregator的功能,实现了metrics api的注册。可以通过如下命令
1 | $ kubectl api-versions |
HPA通过使用该API获取监控的CPU和内存资源:
1 | # 查询nodes节点的cpu和内存数据 |
同样,为了实现通用指标的采集,需要部署Prometheus Adapter,来提供custom.metrics.k8s.io,作为HPA获取通用指标的入口。
Adapter安装对接(仅记录没有实验)
k8s-prometheus-adapter是一个Prometheus的适配器,它可以将Prometheus的指标数据转换成k8s的Metrics API,从而可以被HPA使用。项目地址在这里 k8s-prometheus-adapter
1 | $ git clone -b v0.8.4 https://github.com/DirectXMan12/k8s-prometheus-adapter.git |
查看部署说明 deploy
镜像使用官方提供的v0.8.4最新版
准备证书
1
2
3
4
5
6
7$ export PURPOSE=serving
$ openssl req -x509 -sha256 -new -nodes -days 3650 -newkey rsa:2048 -keyout ${PURPOSE}.key -out ${PURPOSE}.crt -subj "/CN=ca"
$ kubectl -n monitor create secret generic cm-adapter-serving-certs --from-file=./serving.crt --from-file=./serving.key
# 查看证书
$ kubectl -n monitor describe secret cm-adapter-serving-certs替换命名空间
1
2# 资源清单文件默认用的命名空间是custom-metrics,替换为本例中使用的monitor
$ sed -i 's/namespace: custom-metrics/namespace: monitor/g' manifests/*配置adapter对接的Prometheus地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 由于adapter会和Prometheus交互,因此需要配置对接的Prometheus地址
# 替换掉28行:yamls/custom-metrics-apiserver-deployment.yaml 中的--prometheus-url
$ vim manifests/custom-metrics-apiserver-deployment.yaml
...
18 spec:
19 serviceAccountName: custom-metrics-apiserver
20 containers:
21 - name: custom-metrics-apiserver
22 image: directxman12/k8s-prometheus-adapter-amd64:v0.7.0
23 args:
24 - --secure-port=6443
25 - --tls-cert-file=/var/run/serving-cert/serving.crt
26 - --tls-private-key-file=/var/run/serving-cert/serving.key
27 - --logtostderr=true
28 - --prometheus-url=http://prometheus:9090/
29 - --metrics-relist-interval=1m
30 - --v=10
31 - --config=/etc/adapter/config.yaml
...部署服务
1
2
3
4
5
6
7
8
9
10
11
12$ mv manifests/custom-metrics-config-map.yaml .
$ vi manifests/custom-metrics-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitor
data:
config.yaml: |
rules:
- {}
$ kubectl apply -f manifests/
完成后验证一下:
1 | $ kubectl api-versions|grep metrics |
配置自定义指标
通用指标示例程序部署
为了演示效果,我们新建一个deployment来模拟业务应用。
1 | $ cat custom-metrics-demo.yaml |
部署应用:
1 | $ kubectl apply -f custom-metrics-demo.yaml |
注册为Prometheus的target:
1 | $ cat custom-metrics-demo-svc.yaml |
自动注册为Prometheus的采集Targets。
通常web类的应用,会把每秒钟的请求数作为业务伸缩的指标依据。
部署完成,接下我们需要进行测试了。但是测试前还有一些问题得解决。
使用案例应用custom-metrics-demo,如果custom-metrics-demo最近1分钟内每秒钟的请求数超过10次,则自动扩充业务应用的副本数。
配置自定义指标
告诉Adapter去采集转换哪些指标,Adapter支持转换的指标,才可以作为HPA的依据
配置HPA规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: front-app-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: custom-metrics-demo
minReplicas: 1
maxReplicas: 3
metrics:
- type: Pods
pods:
metricName: http_requests_per_second
targetAverageValue: 10
Adapter配置自定义指标
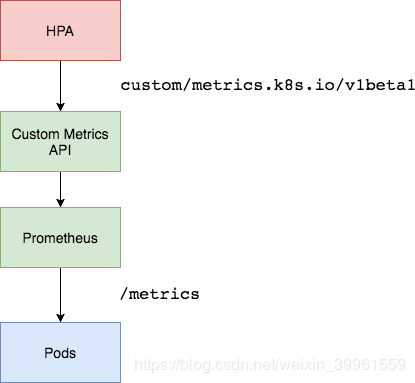
前面讲CPU的平均使用率的采集,其实是通过node_cpu_seconds_total指标计算得到的。
1 | ^ |
同样,如果想获得每个业务应用最近1分钟内每秒的访问次数,也是根据总数来做计算,因此,需要使用业务自定义指标http_requests_total,配合rate方法即可获取每秒钟的请求数。
1 | rate(http_requests_total[2m]) |
自定义指标可以配置多个,因此,需要将规则使用数组来配置
1
2rules:
- {}告诉Adapter,哪些自定义指标可以使用
1
2rules:
- seriesQuery: 'http_requests_total{}'seriesQuery是PromQL语句,和直接用
http_requests_total查询到的结果一样,凡是seriesQuery可以查询到的指标,都可以用作自定义指标告诉Adapter,指标中的标签和k8s中的资源对象的关联关系
1
2
3
4
5
6rules:
- seriesQuery: 'http_requests_total{}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}hpa 拿着k8s里的namepace和pod名称,来查询adaptor,adaptor去查询Prometheus的时候根据resources的适配来转换,namepace=default, pod=front-app-xxxx, kubernetes_namespace=”default”
我们查询到的可用指标格式为:
1
http_requests_total{instance="10.244.2.140:8080", job="kubernetes-sd-endpoints", kubernetes_name="custom-metrics-demo", kubernetes_namespace="default", kubernetes_pod_name="front-app-df5fc79dd-rmzr6", namespace="default", pod="front-app-df5fc79dd-rmzr6"}
由于HPA在调用Adapter接口的时候,告诉Adapter的是查询哪个命名空间下的哪个Pod的指标,因此,Adapter在去查询的时候,需要做一层适配转换(因为并不是每个prometheus查询到的结果中都是叫做
kubernetes_namespace和kubernetes_pod_name)/apis/custom.metrics.k8s.io/v1beta2/namespaces/default/pods/xxx/http_requests_total指定自定义的指标名称,供HPA配置使用
1
2
3
4
5
6
7
8rules:
- seriesQuery: 'http_requests_total{}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
as: "http_requests_per_second"因为Adapter转换完之后的指标含义为:每秒钟的请求数。因此提供指标名称,该配置根据正则表达式做了匹配替换,转换完后的指标名称为:
http_requests_per_second,HPA规则中可以直接配置该名称。告诉Adapter如何获取最终的自定义指标值
1
2
3
4
5
6
7
8
9rules:
- seriesQuery: 'http_requests_total{}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
as: "http_requests_per_second"
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'
我们最终期望的写法可能是这样:
1 | sum(rate(http_requests_total{kubernetes_namespace="default",kubernetes_pod_name="xxxx"}[2m])) by (kubernetes_pod_name) |
但是Adapter提供了更简单的写法:
1 | sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>) |
Series: 指标名称LabelMatchers: 指标查询的labelGroupBy: 结果分组,针对HPA过来的查询,都会匹配成kubernetes_pod_name
更新Adapter的配置:
1 | $ vi custom-metrics-configmap.yaml |
需要更新configmap并重启adapter服务:
1 | $ kubectl apply -f custom-metrics-configmap.yaml |
再次查看可用的指标数据:
1 | $ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 |jq |
实际中,hpa会去对如下地址发起请求,获取数据:
1 | $ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta2/namespaces/default/pods/*/http_requests_per_second |jq |
其中33m等于0.033,即当前指标查询每秒钟请求数为0.033次.
我们发现有两个可用的resources,引用官方的一段解释:
1 | Notice that we get an entry for both "pods" and "namespaces" -- the adapter exposes the metric on each resource that we've associated the metric with (and all namespaced resources must be associated with a namespace), and will fill in the <<.GroupBy>> section with the appropriate label depending on which we ask for. |
https://github.com/DirectXMan12/k8s-prometheus-adapter/blob/master/docs/config-walkthrough.md
https://github.com/DirectXMan12/k8s-prometheus-adapter/blob/master/docs/config.md