全部的 K8S学习笔记总目录 ,请点击查看。
上面我们已经部署了Prometheus,现在我们来看看如何添加监控目标。
添加coreDNS监控 coreDNS监控指标 无论是业务应用还是k8s系统组件,只要提供了metrics api,并且该api返回的数据格式满足标准的Prometheus数据格式要求即可。
其实,很多组件已经为了适配Prometheus采集指标,添加了对应的/metrics api,比如CoreDNS:
1 2 3 4 5 $ kubectl -n kube-system get po -owide | grep coredns coredns-66f779496c-cx2zv 1/1 Running 0 98d 10.244.1.2 k8s-node1 <none> <none> coredns-66f779496c-t5zs2 1/1 Running 0 98d 10.244.1.3 k8s-node1 <none> <none> $ curl 10.244.1.2:9153/metrics
修改target配置 加入coreDns的监控目标,只需要修改Prometheus的配置文件即可。因为Prometheus的配置文件是以configmap的形式保存的,所以我们需要修改configmap的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ kubectl -n kube-system get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 98d metrics-server ClusterIP 10.105.155.213 <none> 443/TCP 15d $ kubectl -n monitor edit configmap prometheus-config ... scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090' ] - job_name: 'coredns' static_configs: - targets: ['10.96.0.10:9153' ] $ kubectl -n monitor exec prometheus-5bc5966ff8-f84vx -- cat /etc/prometheus/prometheus.yml $ kubectl -n monitor get po -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES prometheus-5bc5966ff8-f84vx 1/1 Running 0 3h39m 10.244.0.26 k8s-master <none> <none> $ curl -XPOST 10.244.0.26:9090/-/reload
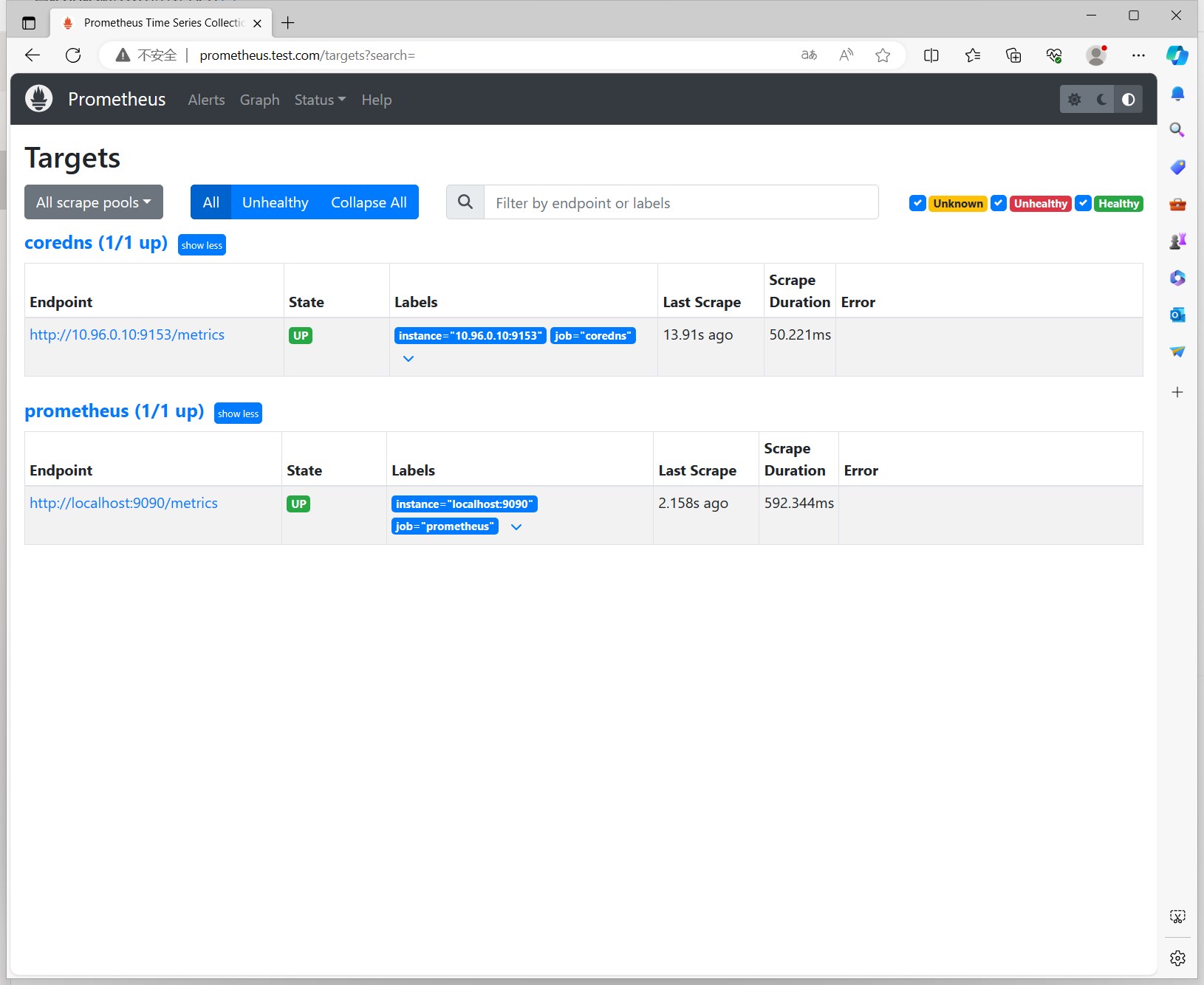
此时我们登录Prometheus的Web界面,可以看到coreDNS已经添加到监控目标中了。
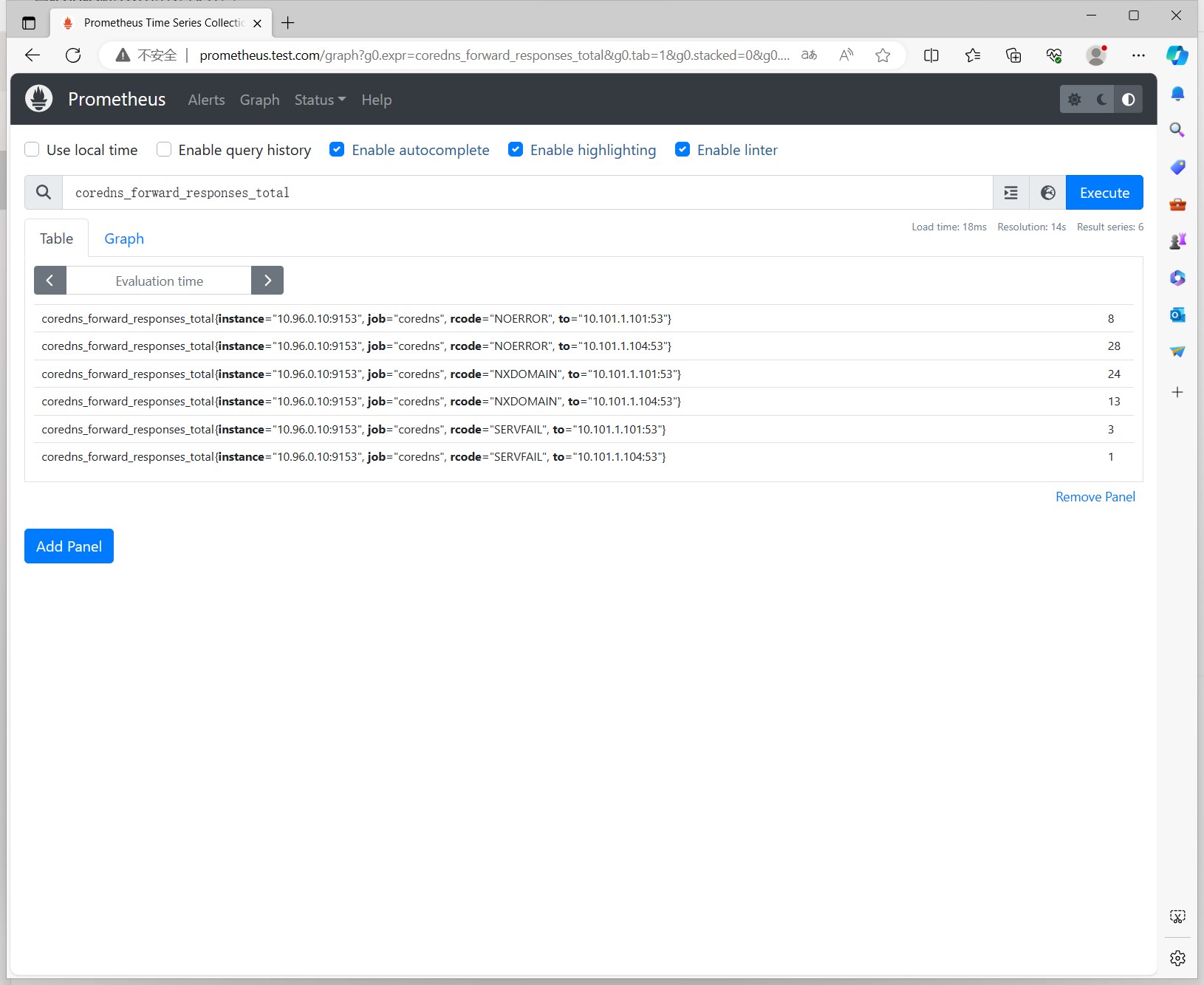
我们使用Prometheus的查询语句,可以看到coreDNS的监控指标:
监控api-server等系统组件 常用监控对象的指标采集 对于集群的监控一般我们需要考虑以下几个方面:
内部系统组件的状态:比如 kube-apiserver、kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
业务容器基础指标的监控(容器CPU、内存、磁盘等), hpa ,kubelet, advistor
业务容器业务指标的监控,业务代码实现了/metrics的api,暴露业务的指标
编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
监控 kube-apiserver api-server自身也提供了 /metrics 的api来提供监控数据
1 2 3 4 5 6 7 8 9 10 $ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 98d $ kubectl -n monitor create token prometheus $ token="eyJhbGciOiJSUzI1NiIsImtpZCI6IkFJa1A2OHMwZnVKdHl2VnBaWG5QWl9TRlFCbFhKcmtvcGdEZjFDR1RuMjQifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzAxNDQ5MzcyLCJpYXQiOjE3MDE0NDU3NzIsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJtb25pdG9yIiwic2VydmljZWFjY291bnQiOnsibmFtZSI6InByb21ldGhldXMiLCJ1aWQiOiJhNGJjMWI5Yi0wMzBjLTRhMGItYjI3MS1kOTMwNGJiZjEwYjAifX0sIm5iZiI6MTcwMTQ0NTc3Miwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Om1vbml0b3I6cHJvbWV0aGV1cyJ9.Frbx-O0rFmf0DXdFGCU2Nh1avWK6EUOlGahyebwoDHHJC0eFEITrJWw7oE8crOlC_fdBsRcqoLZkgRPna2lxJmzZ_Imxo6nepKqhzDjaoeXngcx1w-rAmuzkjSSJJxsCIIpwAjW3ZMBNdpaj1Q5cKhjOMgFwFEcfCAAzxabRrDkH_qPrMsY3eHmxYqFD168HktpVhUkDmzfUvJKypECp4YGccjNAtN7T5hpe8q94hn-_fdvf_xmRUeOqEUSHcdr9lwf8Tq8fF8rMcSM_0OCnUQjvHM6jixyxEOw53axoXmL2VN3RPajfUB5ECV27fi_XG1oTJck7OzE0vA0kOfUN3w" $ curl -k -H "Authorization: Bearer ${token} " https://10.96.0.1/metrics
确认api-server的监控数据已经正常返回后,就可以通过手动配置如下job来添加对apiserver服务的监控,
1 2 3 4 5 6 7 8 9 10 $ kubectl -n monitor edit configmap prometheus-config ... - job_name: 'kubernetes-apiserver' static_configs: - targets: ['10.96.0.1' ] scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
只有我们创建了一个service account资源,就会在容器挂载目录/var/run/secrets/kubernetes.io/serviceaccount/下生成一个token文件,这个文件就是apiserver的token,我们可以通过这个token来访问apiserver的/metrics api。
1 2 3 4 5 # 确认配置文件更新 $ kubectl -n monitor exec prometheus-5bc5966ff8-f84vx -- cat /etc/prometheus/prometheus.yml # 重启Prometheus进程 $ curl -XPOST 10.244.0.26:9090/-/reload
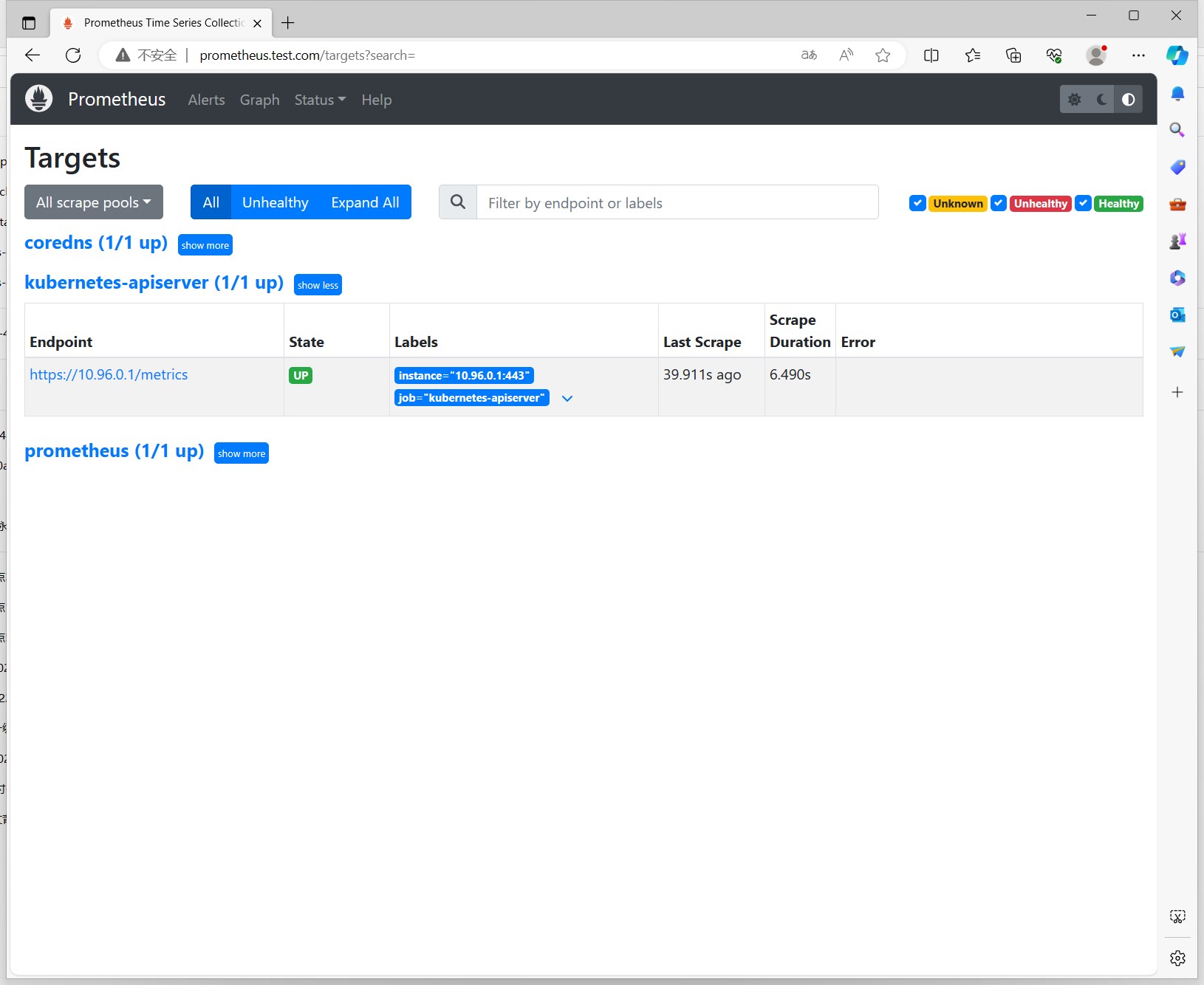
确认api-server已经添加到监控目标中了。
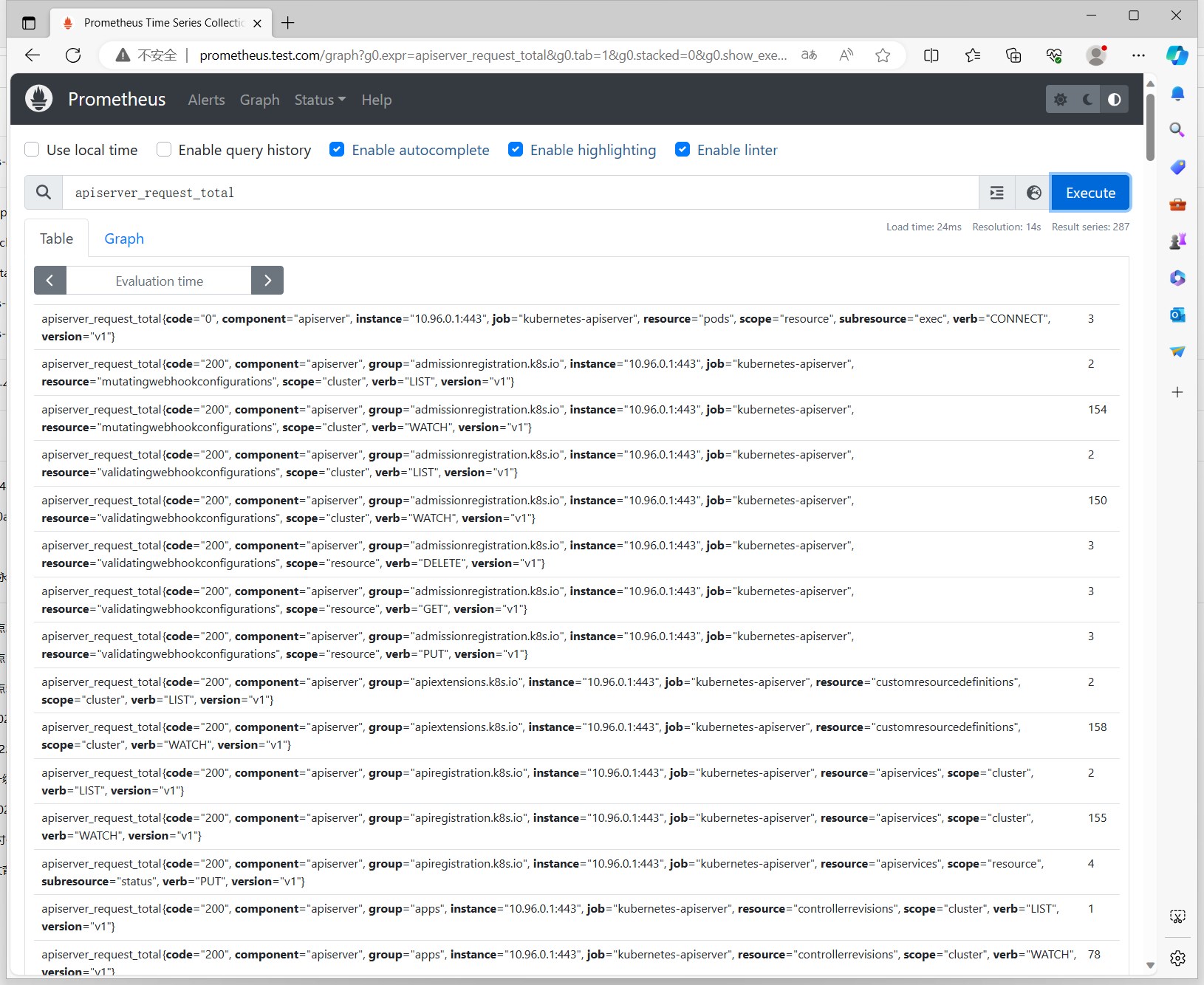
我们使用Prometheus的查询语句,可以看到apiserver的监控指标:
监控宿主机指标 监控集群节点基础指标 如果想要监控集群节点的基础指标,比如节点的cpu、load、disk、memory等指标,可以使用node_exporter来采集。
node_exporter 是一个开源的第三方组件,工作原理是通过在节点上启动一个进程,该进程会定期采集节点的基础指标,然后通过http的方式暴露给Prometheus采集。
我们要部署node_exporter,需要满足以下几个条件:
每个节点都需要监控,因此可以使用DaemonSet类型来管理node_exporter
添加节点的容忍配置,
挂载宿主机中的系统文件信息
部署node_exporter 创建 node-exporter 的资源清单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 $ cat node-exporter.ds.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: node-exporter namespace: monitor labels: app: node-exporter spec: selector: matchLabels: app: node-exporter template: metadata: labels: app: node-exporter spec: hostPID: true hostIPC: true hostNetwork: true nodeSelector: kubernetes.io/os: linux containers: - name: node-exporter image: prom/node-exporter:v1.7.0 args: - --web.listen-address=$(HOSTIP):9100 - --path.procfs=/host/proc - --path.sysfs=/host/sys - --path.rootfs=/host/root - --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+)($|/) - --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$ ports: - containerPort: 9100 env : - name: HOSTIP valueFrom: fieldRef: fieldPath: status.hostIP resources: requests: cpu: 150m memory: 180Mi limits: cpu: 150m memory: 180Mi securityContext: runAsNonRoot: true runAsUser: 65534 volumeMounts: - name: proc mountPath: /host/proc - name: sys mountPath: /host/sys - name: root mountPath: /host/root mountPropagation: HostToContainer readOnly: true tolerations: - operator: "Exists" volumes: - name: proc hostPath: path: /proc - name: dev hostPath: path: /dev - name: sys hostPath: path: /sys - name: root hostPath: path: /
创建node-exporter服务
1 2 3 4 5 6 7 8 9 10 11 $ kubectl apply -f node-exporter.ds.yaml $ kubectl -n monitor get po -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES node-exporter-7vdxl 1/1 Running 0 36s 192.168.100.3 k8s-node2 <none> <none> node-exporter-bkqj6 1/1 Running 0 36s 192.168.100.2 k8s-node1 <none> <none> node-exporter-bmv4m 1/1 Running 0 36s 192.168.100.1 k8s-master <none> <none> prometheus-5bc5966ff8-f84vx 1/1 Running 0 4h34m 10.244.0.26 k8s-master <none> <none> $ curl 192.168.100.1:9100/metrics
这样我们就可以通过node-exporter的服务来采集节点的基础指标了。
我们也可以通过helm来部署node-exporter,指令如下:
1 2 3 $ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts $ helm repo update $ helm install node-exporter prometheus-community/prometheus-node-exporter -n monitor
Prometheus的服务发现与Relabeling 接下来就要将node-exporter添加到监控目标,那么如何添加到Prometheus的target中呢?
配置一个Service,后端挂载node-exporter的服务,把Service的地址配置到target中
带来新的问题,target中无法直观的看到各节点node-exporter的状态
把每个node-exporter的服务都添加到target列表中
带来新的问题,集群节点的增删,都需要手动维护列表
target列表维护量随着集群规模增加
于是我们需要一种更加智能的方式来添加监控目标,这就是Prometheus的服务发现机制。
我们之前已经给Prometheus配置了RBAC,有读取node的权限,因此Prometheus可以去调用Kubernetes API获取node信息,所以Prometheus通过与 Kubernetes API 集成,提供了内置的服务发现分别是:Node、Service、Pod、Endpoints、Ingress
我们再次修改prometheus的配置文件,添加node的服务发现配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...... scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090' ] - job_name: 'coredns' static_configs: - targets: ['10.96.0.10:9153' ] - job_name: 'kubernetes-sd-node-exporter' kubernetes_sd_configs: - role: node ......
重新reload后查看效果:
1 2 $ kubectl -n monitor exec prometheus-5bc5966ff8-f84vx -- cat /etc/prometheus/prometheus.yml $ curl -XPOST 10.244.0.26:9090/-/reload
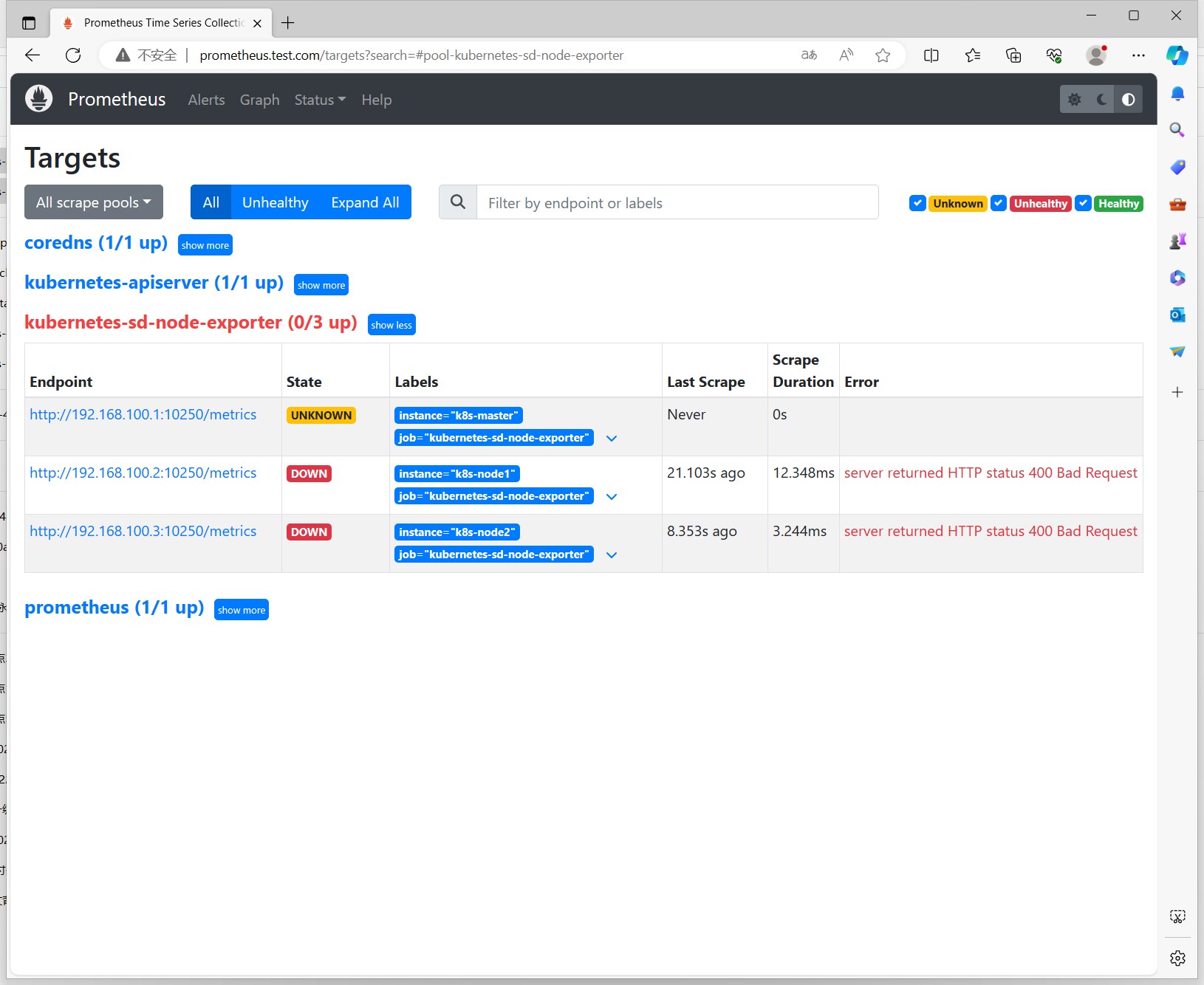
重新reload后,查看Prometheus的targets列表,可以看到node-exporter已经添加到监控目标中了,但是似乎有点问题,我们看到node-exporter的状态是DOWN的。
可以看到默认访问的地址是http://node-ip:10250/metrics,10250是kubelet API的服务端口,说明Prometheus的node类型的服务发现模式,默认是和kubelet的10250绑定的,而我们是期望使用node-exporter作为采集的指标来源,因此需要把访问的endpoint替换成http://node-ip:9100/metrics。
在真正抓取数据前,Prometheus提供了relabeling的能力。Relabeling 重新标记用于配置 Prometheus 元信息的方式,它是转换和过滤 Prometheus 中 label 标签对象的核心。
那怎么理解这个功能呢?
查看Target的Label列,可以发现,每个target对应会有很多Before Relabeling/Discovered labels的标签,这些__开头的label是系统内部使用,不会存储到样本的数据里,但是,我们在查看数据的时候,可以发现,每个数据都有两个默认的label,即:
1 prometheus_notifications_dropped_total{instance="localhost:9090" ,job="prometheus" }
instance的值其实则取自于__address__
这种发生在采集样本数据之前,对Target实例的标签进行重写的机制在Prometheus被称为Relabeling,这些配置还是在Prometheus配置文件里面配置。。
因此,利用relabeling的能力,只需要将__address__替换成node_exporter的服务地址即可。
1 2 3 4 5 6 7 8 9 10 11 ...... - job_name: 'kubernetes-sd-node-exporter' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace ......
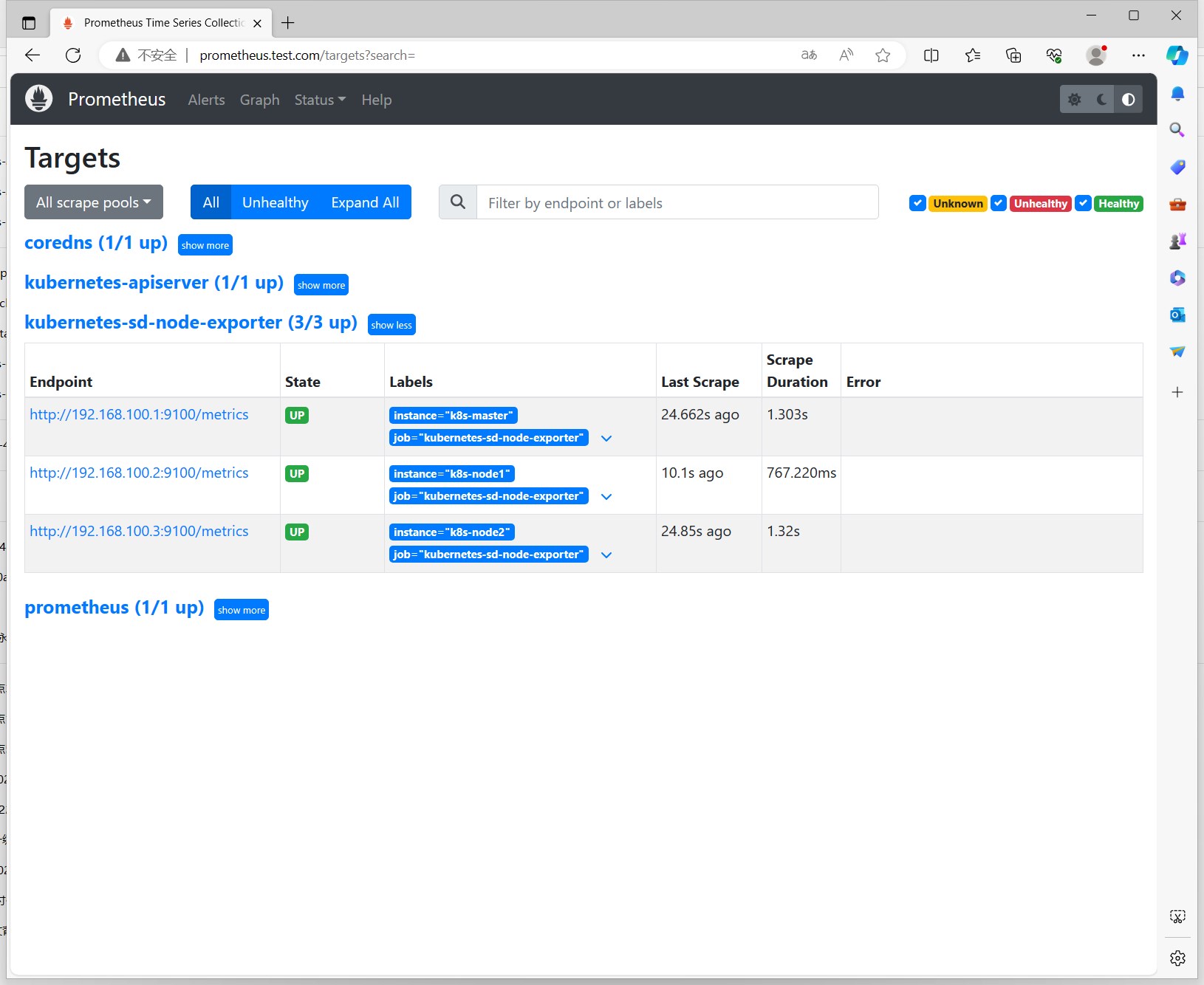
再次更新Prometheus服务后,查看targets列表及node-exporter提供的指标
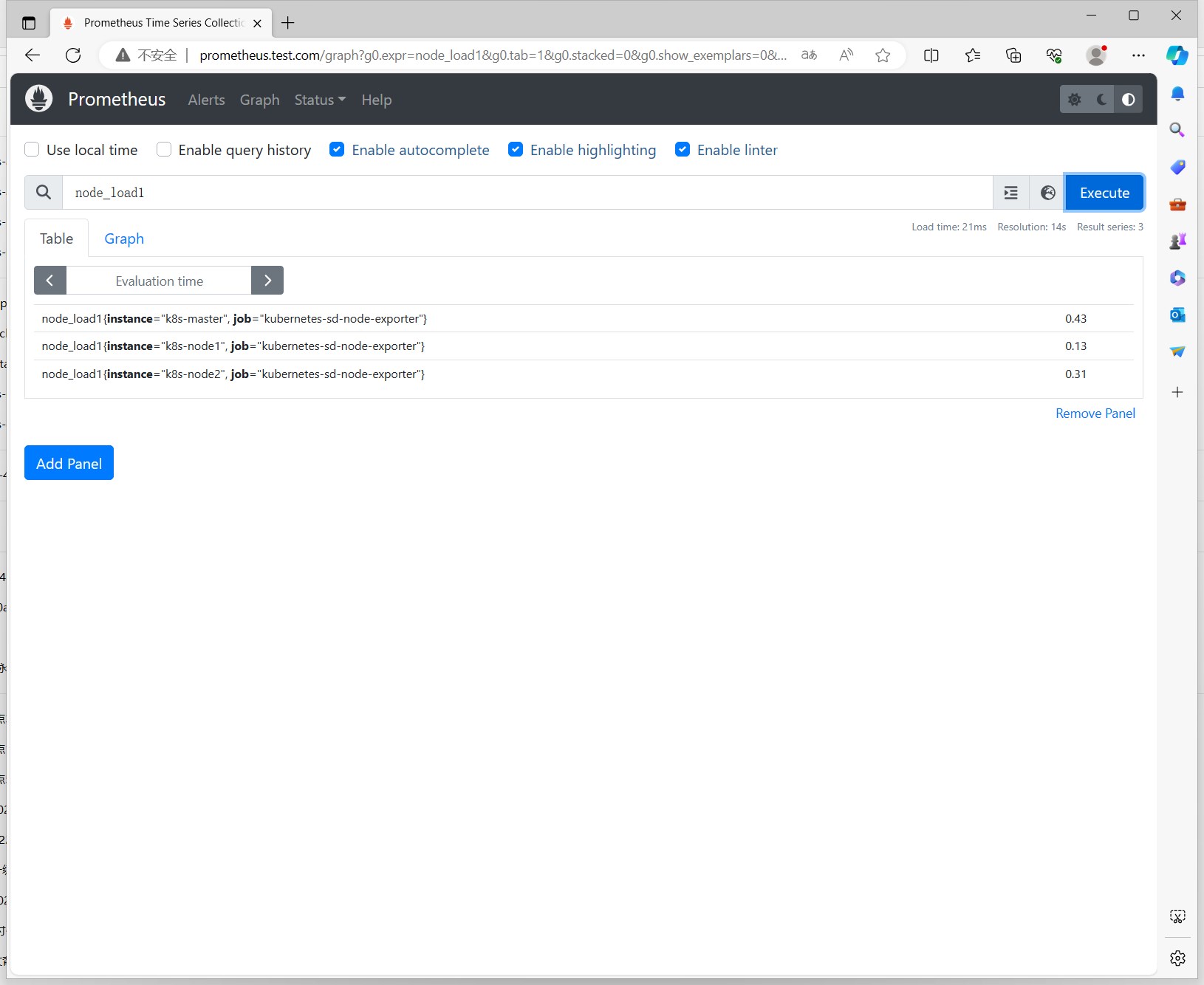
查看node-exporter的监控指标 node_load1 (1分钟的load)
容器指标采集 使用cadvisor实现容器指标的采集 目前cAdvisor集成到了kubelet组件内 ,因此如果我们希望通过cadvisor采集容器指标,可以通过kubelet的接口实现容器指标的采集,具体的API为:
1 2 3 4 5 https://<node-ip>:10250/metrics/cadvisor https://<node-ip>:10250/metrics
因此,针对容器指标来讲,我们期望的采集target是:
1 2 3 https://192.168.100.1:10250/metrics/cadvisor https://192.168.100.2:10250/metrics/cadvisor https://192.168.100.3:10250/metrics/cadvisor
即每个node节点都需要去采集数据,联想到prometheus的服务发现中的node类型,因此,配置:
1 2 3 4 5 ...... - job_name: 'kubernetes-sd-cadvisor' kubernetes_sd_configs: - role: node ......
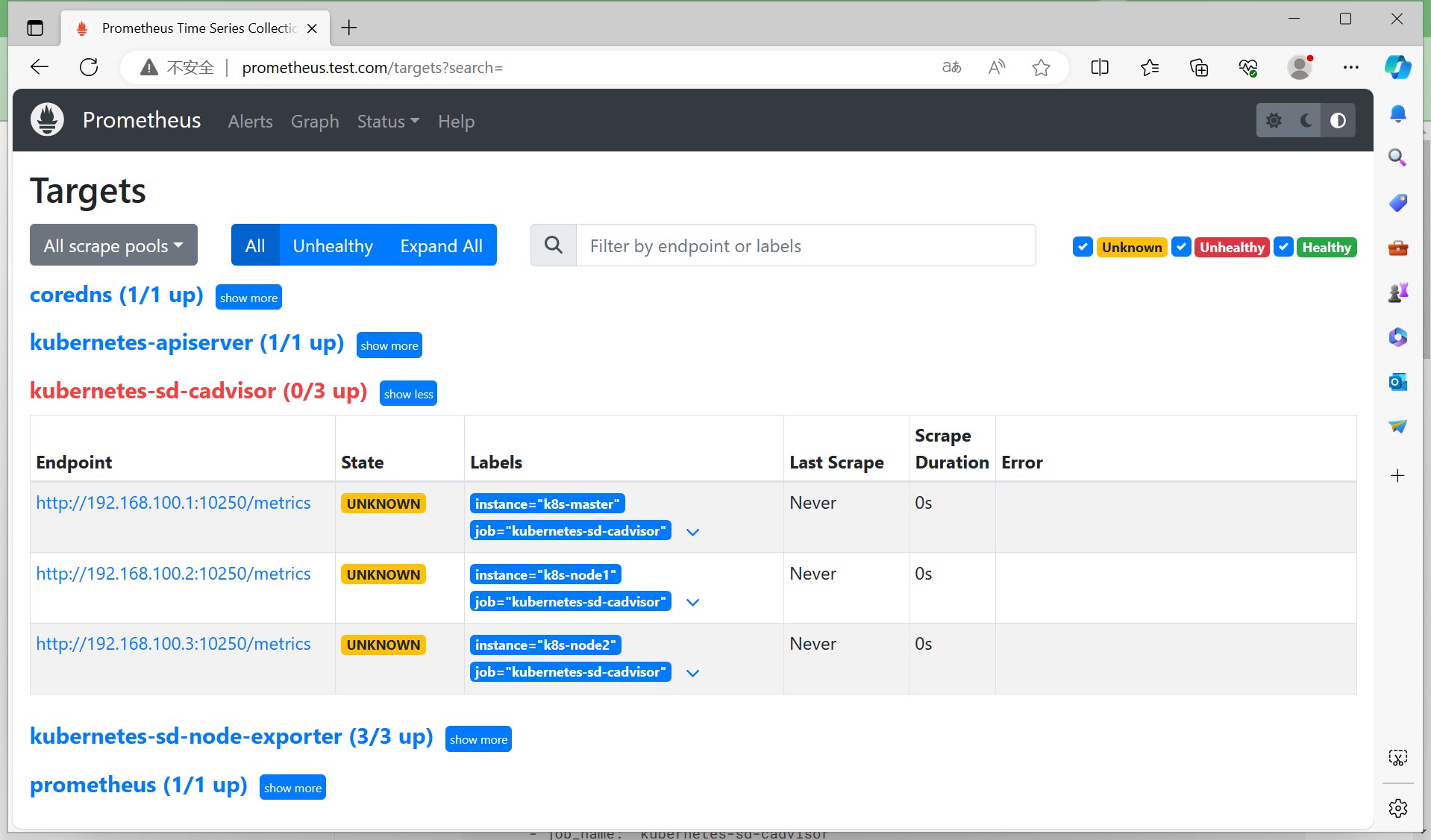
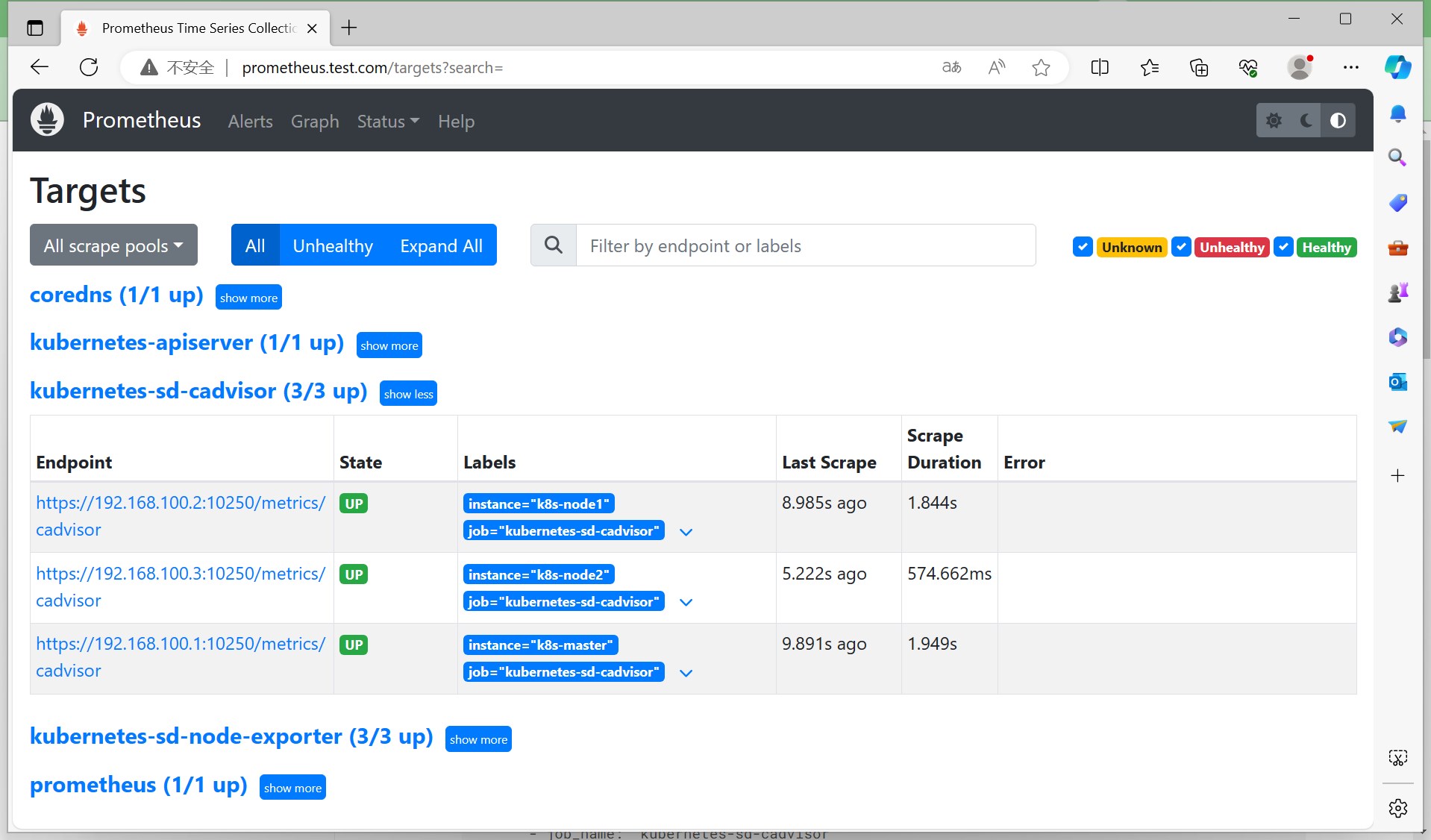
重新加载配置(reload,具体过程与上面类似,这里不再赘述),查看targets列表,可以看到cadvisor已经添加到监控目标中了。
但是默认添加的target列表为:__schema__://__address__ __metrics_path__
1 2 3 http://192.168.100.1:10250/metrics http://192.168.100.2:10250/metrics http://192.168.100.3:10250/metrics
和期望值不同的是__schema__和__metrics_path__,针对__schema__,我们可以直接针对__metrics_path__可以使用relabel修改
1 2 3 4 5 6 7 8 9 10 11 12 13 ...... - job_name: 'kubernetes-sd-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - target_label: __metrics_path__ replacement: /metrics/cadvisor ......
重新应用配置,然后重建Prometheus的pod。
查看targets列表,可以看到targets已经更新为我们期望的值。
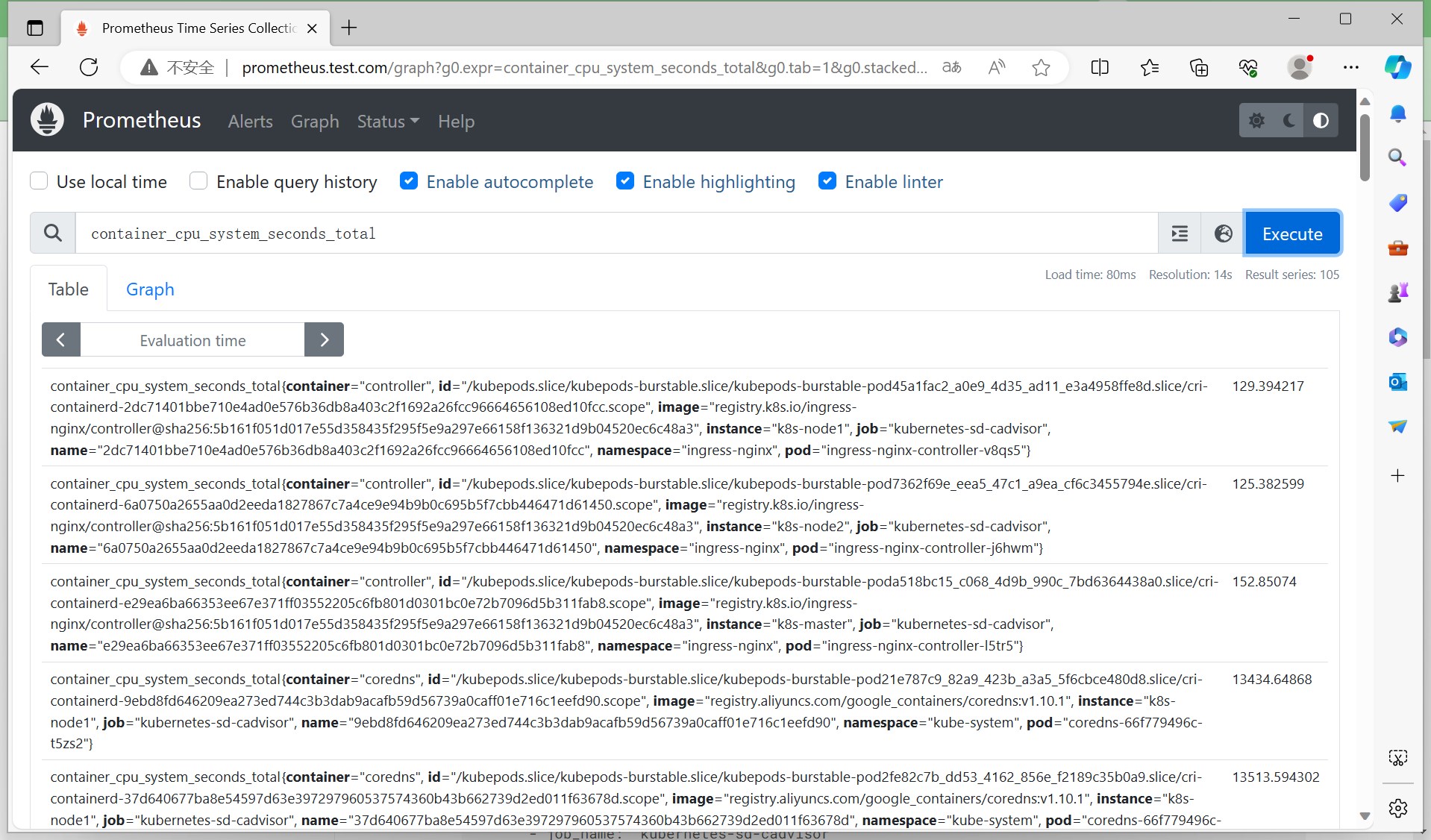
查看cadvisor指标,比如container_cpu_system_seconds_total,container_memory_usage_bytes
综上,利用node类型的服务发现,可以实现对daemonset类型服务的目标自动发现以及监控数据抓取。
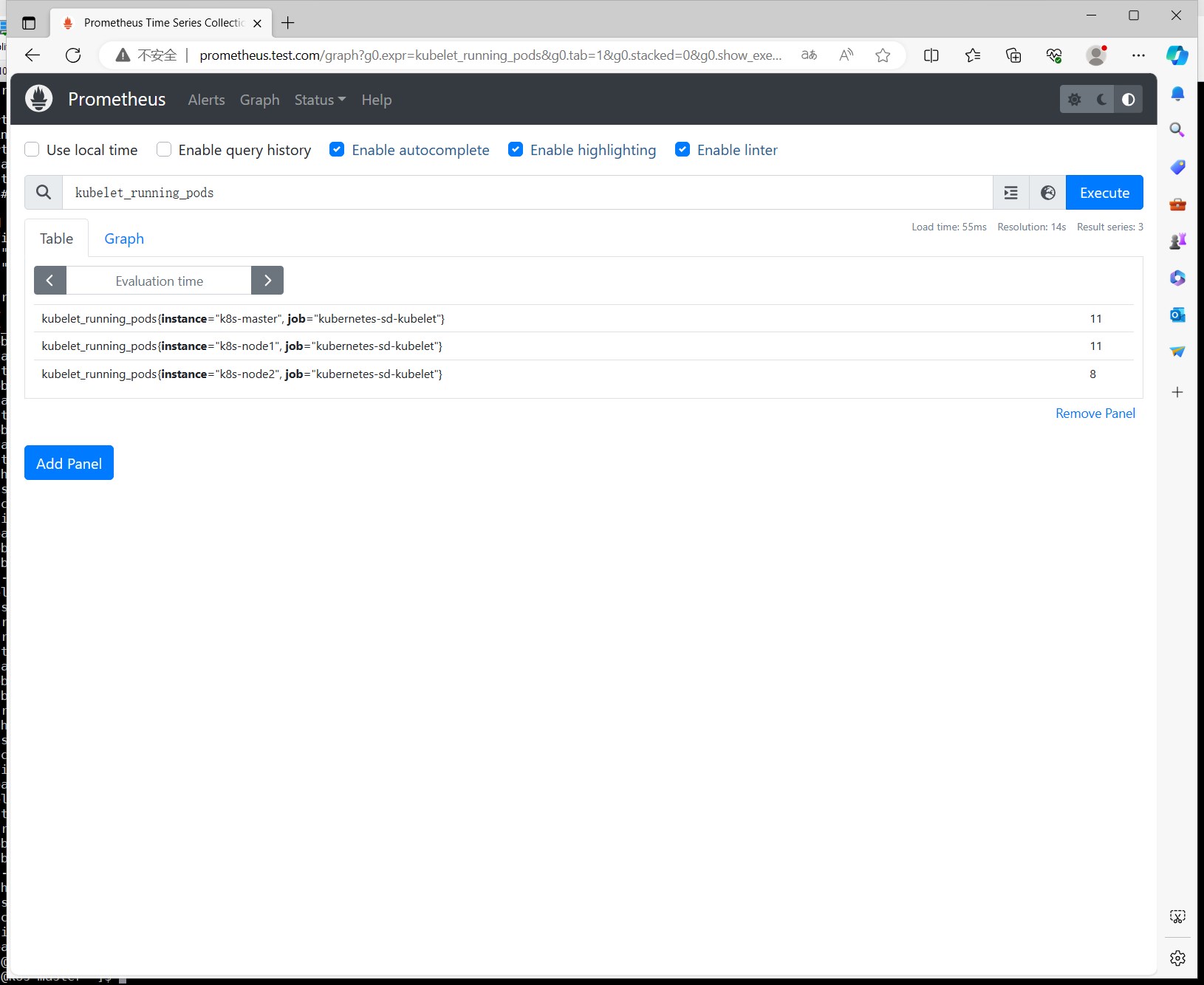
采集kubelet的指标 若想采集kubelet的指标,只需要使用以下配置即可:
1 2 3 4 5 6 7 8 9 10 ...... - job_name: 'kubernetes-sd-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token ......
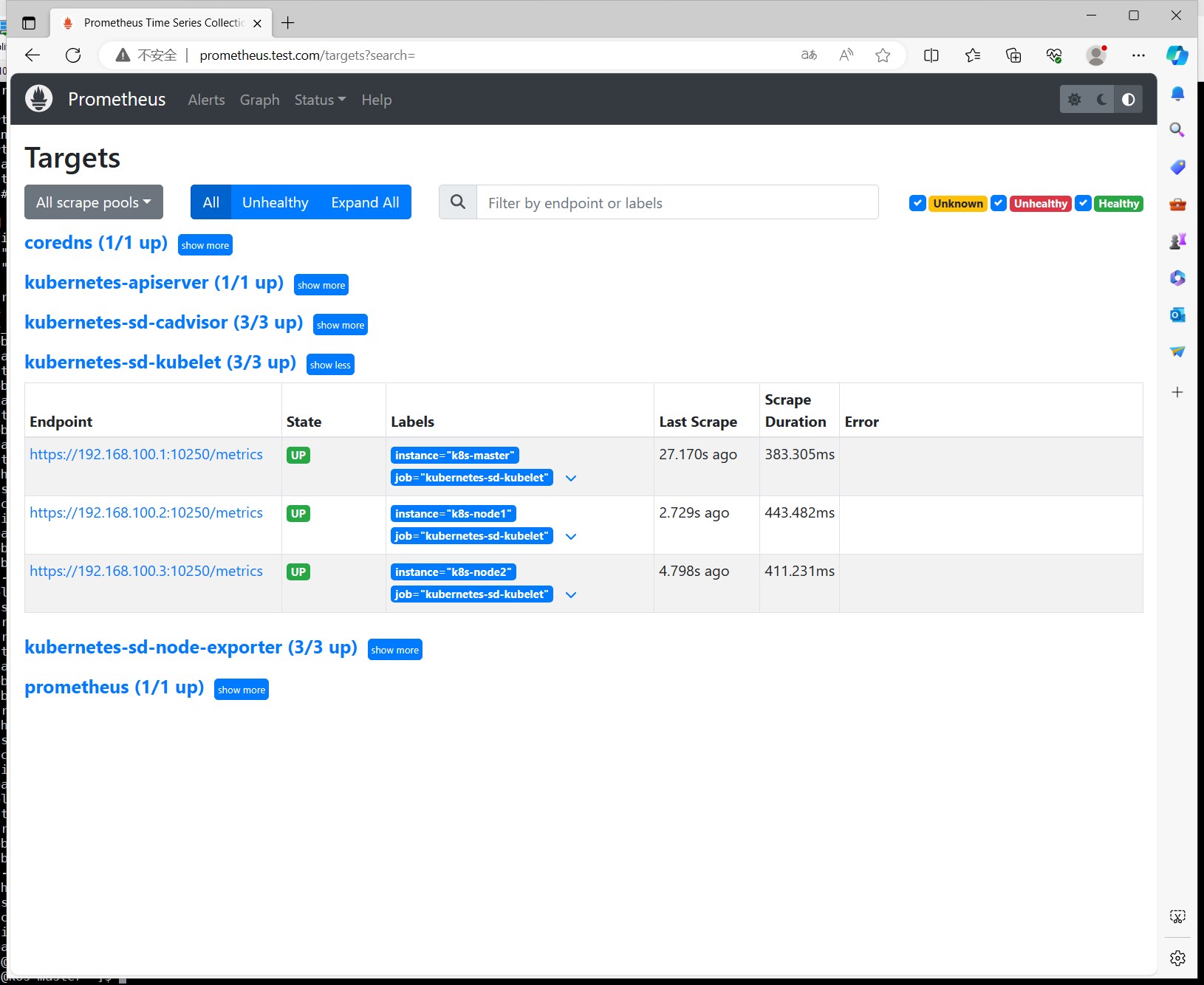
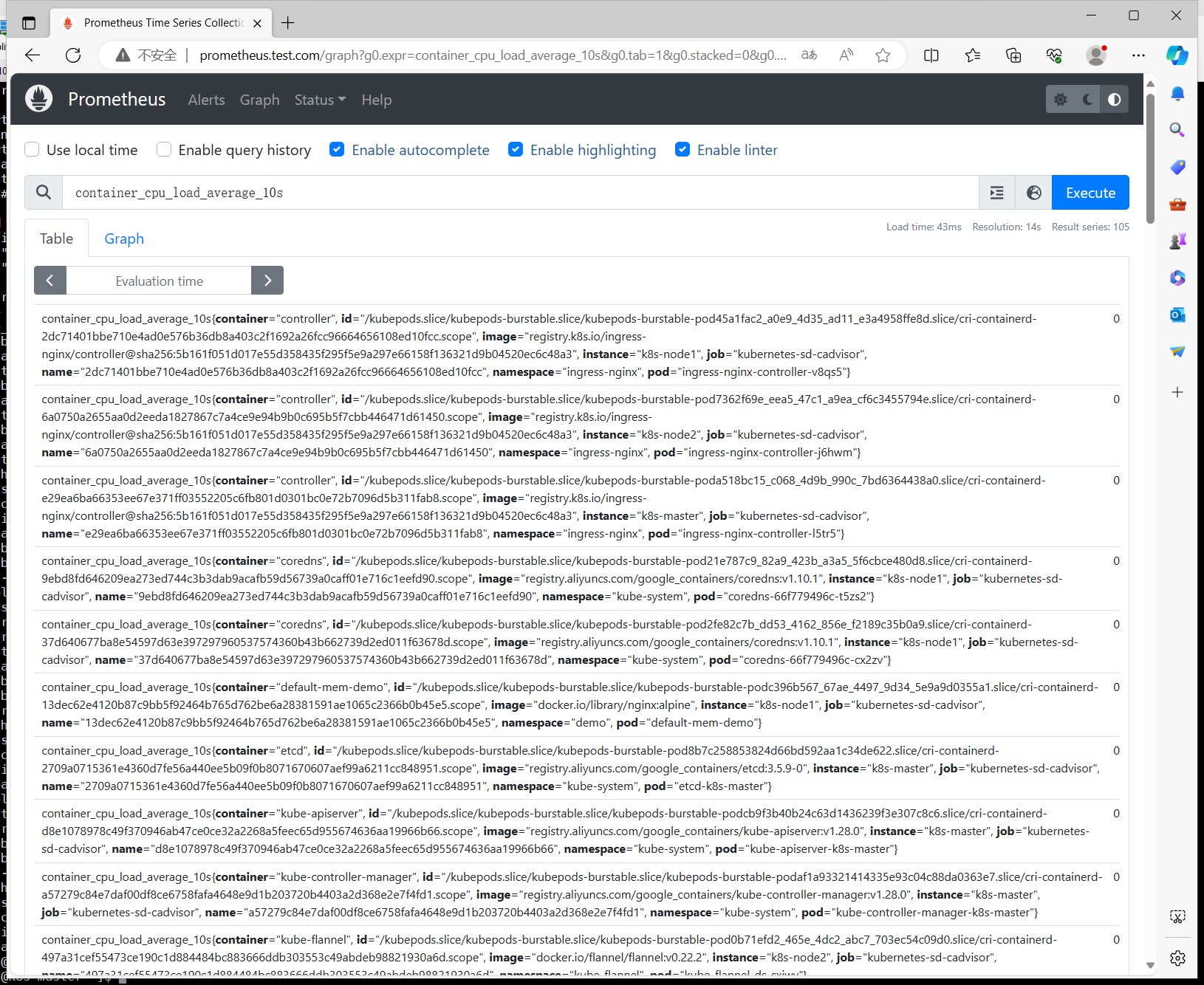
还是同样的操作,修改配置文件,reload,重建pod,查看targets列表,查看kubelet的监控指标。
集群Service服务的监控指标采集 服务发现 比如集群中存在100个业务应用,每个业务应用都需要被Prometheus监控。
每个服务都需要手动添加配置的话,工作量太大,而且随着集群规模的增加,维护成本也会增加。那么有没有更好的方式呢?
答案是肯定的,Prometheus提供了服务发现的功能,可以自动发现集群中的服务,然后自动添加到监控目标中。
我们只需要在Prometheus的配置文件中,添加如下配置即可:
1 2 3 4 5 ...... - job_name: 'kubernetes-sd-endpoints' kubernetes_sd_configs: - role: endpoints ......
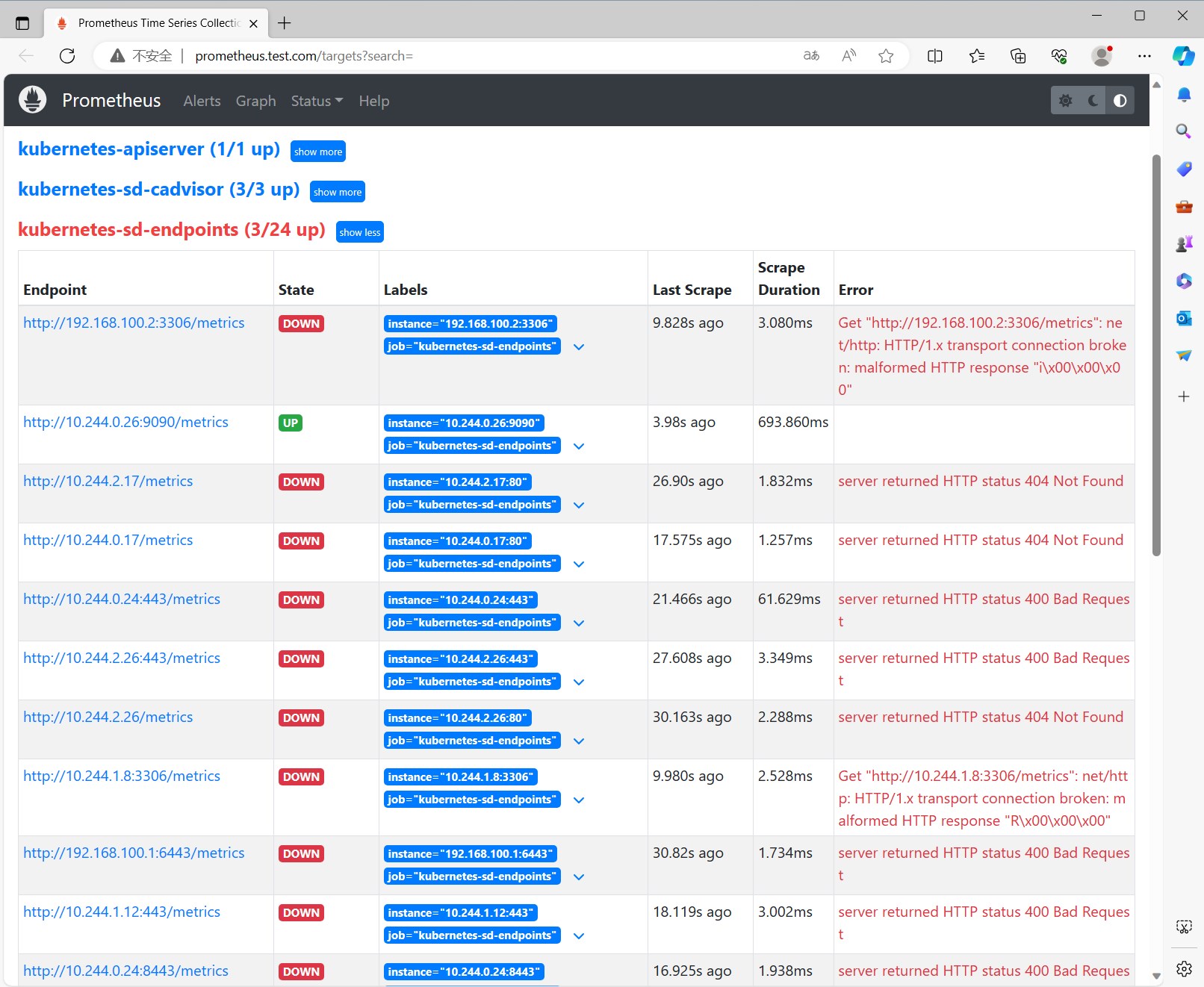
同样的,还是那几个步骤,修改配置文件,reload,重建pod,查看targets列表。
可以看到,targets列表中,kubernetes-sd-endpoints下出现了N多条数。
这些数据其实就是集群中所有的Service的Endpoint列表中的内容每一个都添加/metrics后缀,然后作为监控目标。
我们可以通过查看集群中的所有ep列表来对比网页中的数据。
1 $ kubectl get endpoints --all-namespaces
但是实际上并不是每个服务都已经实现了/metrics监控的,也不是每个实现了/metrics接口的服务都需要注册到Prometheus中,因此,我们需要一种方式对需要采集的服务实现自主可控。这就需要利用relabeling中的keep功能。
relabeling的keep功能 我们知道,relabel的作用对象是target的Before Relabling标签,那么我们可以定义如下的配置:
1 2 3 4 5 6 7 8 9 ...... - job_name: 'kubernetes-sd-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape ] action: keep regex: true ......
上面的配置的意思是,如果target的Before Relabling中存在__meta_kubernetes_service_annotation_prometheus_io_scrape,且值为true的话,则会加入到kubernetes-sd-endpoints这个target中,否则就会被删除。
因此可以为我们期望被采集的服务,加上对应的Prometheus的label即可,那么就可以只采集我们期望的服务了。
添加label 那么问题来了,怎么添加这个label呢?
解决这个问题之前,我们先来查看coredns的metrics类型Before Relabling中的值,可以发现,存在如下类型的Prometheus的标签:
1 2 __meta_kubernetes_service_annotation_prometheus_io_scrape="true" __meta_kubernetes_service_annotation_prometheus_io_port="9153"
接下来我们查看一下coredns对应的service的属性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ kubectl -n kube-system get service kube-dns -oyaml apiVersion: v1 kind: Service metadata: annotations: prometheus.io/port: "9153" prometheus.io/scrape: "true" creationTimestamp: "2023-08-25T07:17:31Z" labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" kubernetes.io/name: CoreDNS name: kube-dns namespace: kube-system ......
发现存在annotations声明,并且和之前查看的Before Relabling中的值是一致的,因此可以联想到二者存在对应关系,Service的定义中的annotations里的特殊字符会被转换成Prometheus中的label中的下划线。
这样的话,我们只需要为我们需要采集的服务定义上如下的annotations声明,即可实现Prometheus自动采集数据
1 2 3 4 5 6 apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: "true" ......
修改path 有些时候,我们业务应用提供监控数据的path地址并不一定是/metrics,如何实现兼容呢?
同样的思路,我们知道,Prometheus会默认使用Before Relabling中的__metrics_path作为采集路径,因此,我们再自定义一个annotation,prometheus.io/path,然后想办法让prometheus使用该值替换__metrics_path即可。
1 2 3 4 5 6 7 apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: "true" prometheus.io/path: "/path/to/metrics" ......
这样,Prometheus端会自动生成如下标签:
1 __meta_kubernetes_service_annotation_prometheus_io_path="/path/to/metrics"
我们只需要在relabel_configs中用该标签的值,去重写__metrics_path__的值即可。因此:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...... - job_name: 'kubernetes-sd-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape ] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path ] action: replace target_label: __metrics_path__ regex: (.+) ......
修改port 有些时候,业务服务的metrics是独立的端口,比如coredns,业务端口是53,监控指标采集端口是9153,这种情况,又该如何处理呢?
很自然的,还是通过自定义annotation来处理,
1 2 3 4 5 6 7 8 apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: "true" prometheus.io/path: "/path/to/metrics" prometheus.io/port: "9153" ......
annotations已经编写好了,那么如何替换又是一个问题了。
我们知道Prometheus默认使用Before Relabeling中的__address__进行作为服务指标采集的地址,但是该地址的格式通常是这样的
1 2 __address__="10.244.1.2:53" __address__="10.244.1.3"
我们的目标是将如下两部分拼接在一起:
10.244.1.2
prometheus.io/port定义的值,即__meta_kubernetes_service_annotation_prometheus_io_port的值
因此,需要使用正则规则取出上述两部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ...... - job_name: 'kubernetes-sd-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape ] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path ] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__ , __meta_kubernetes_service_annotation_prometheus_io_port ] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 ......
需要注意的几点:
__address__中的:<port>有可能不存在,因此,使用()?的匹配方式进行表达式中,三段()我们只需要第一和第三段,不需要中间括号部分的内容,因此使用?:的方式来做非获取匹配,即可以匹配内容,但是不会被记录到$1,$2这种变量中
多个source_labels中间默认使用;号分割,因此匹配的时候需要注意添加;号
添加更多的label 此外,还可以将Before relabeling中的更多常用的字段取出来添加到目标的label中,比如:
1 2 3 4 5 6 7 8 9 - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_service_name - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name
全部配置 因此,目前的relabel的配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ...... - job_name: 'kubernetes-sd-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape ] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path ] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__ , __meta_kubernetes_service_annotation_prometheus_io_port ] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - source_labels: [__meta_kubernetes_namespace ] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name ] action: replace target_label: kubernetes_service_name - source_labels: [__meta_kubernetes_pod_name ] action: replace target_label: kubernetes_pod_name ......
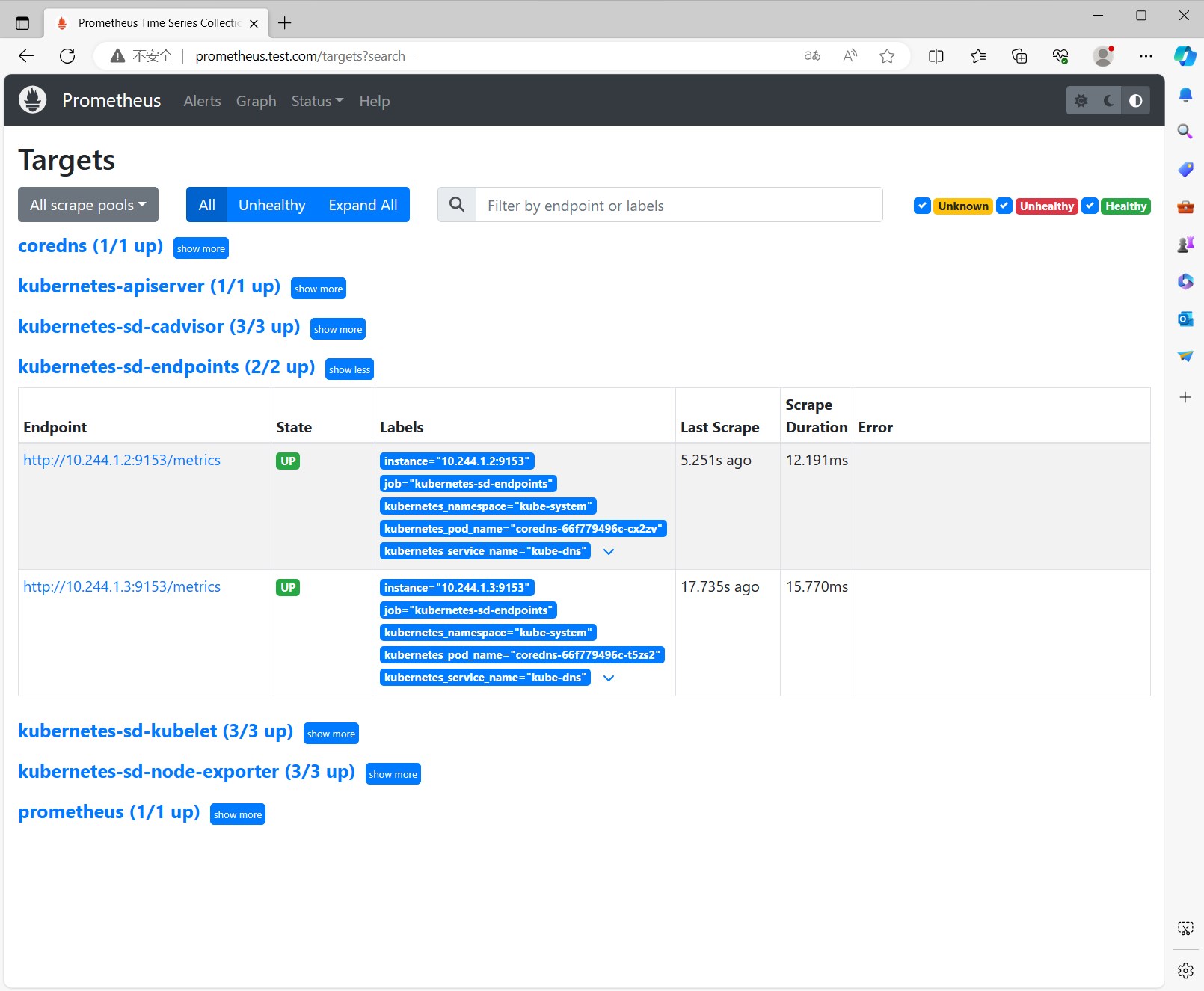
重新加载配置,查看效果 更新configmap并reload Prometheus服务,查看target列表。
kube-state-metrics监控 kube-state-metrics监控是什么? 已经有了cadvisor,容器运行的指标已经可以获取到,但是下面这种情况却无能为力:
我调度了多少个replicas?现在可用的有几个?
多少个Pod是running/stopped/terminated状态?
Pod重启了多少次?
而这些则是kube-state-metrics提供的内容,它基于client-go开发,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。因此,需要借助于kube-state-metrics来实现。
kube-state-metrics提供的指标 指标类别包括:
CronJob Metrics
DaemonSet Metrics
Deployment Metrics
Job Metrics
LimitRange Metrics
Node Metrics
PersistentVolume Metrics
PersistentVolumeClaim Metrics
Pod Metrics
kube_pod_info
kube_pod_owner
kube_pod_status_phase
kube_pod_status_ready
kube_pod_status_scheduled
kube_pod_container_status_waiting
kube_pod_container_status_terminated_reason
…
Pod Disruption Budget Metrics
ReplicaSet Metrics
ReplicationController Metrics
ResourceQuota Metrics
Service Metrics
StatefulSet Metrics
Namespace Metrics
Horizontal Pod Autoscaler Metrics
Endpoint Metrics
Secret Metrics
ConfigMap Metrics
部署kube-state-metrics kube-state-metrics的部署,可以参考官方文档
这里我使用helm部署,helm的官方chart在这里 ,部署清单的github地址是prometheus-community/helm-charts
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts $ helm repo update $ helm pull prometheus-community/kube-state-metrics $ tar zxf kube-state-metrics-5.15.2.tgz $ helm install kube-state-metrics prometheus-community/kube-state-metrics -n monitor
如何添加到Prometheus监控target中 因为我们已经添加了kubernetes-sd-endpoints的服务发现,因此,只需要在Service的annotations中添加prometheus.io/scrape: "true"即可。这里我们使用的helm进行的部署,因此使用默认的配置即可,不需要做任何修改。
如果使用yaml文件进行部署,可以参考如下的配置修改service的配置让其支持prometheus的监控:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ cat service.yaml apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: "true" prometheus.io/port: "8080" labels: app.kubernetes.io/name: kube-state-metrics app.kubernetes.io/version: 2.1.0 name: kube-state-metrics namespace: monitor spec: clusterIP: None ports: - name: http-metrics port: 8080 targetPort: http-metrics - name: telemetry port: 8081 targetPort: telemetry selector: app.kubernetes.io/name: kube-state-metrics $ kubectl apply -f service.yaml
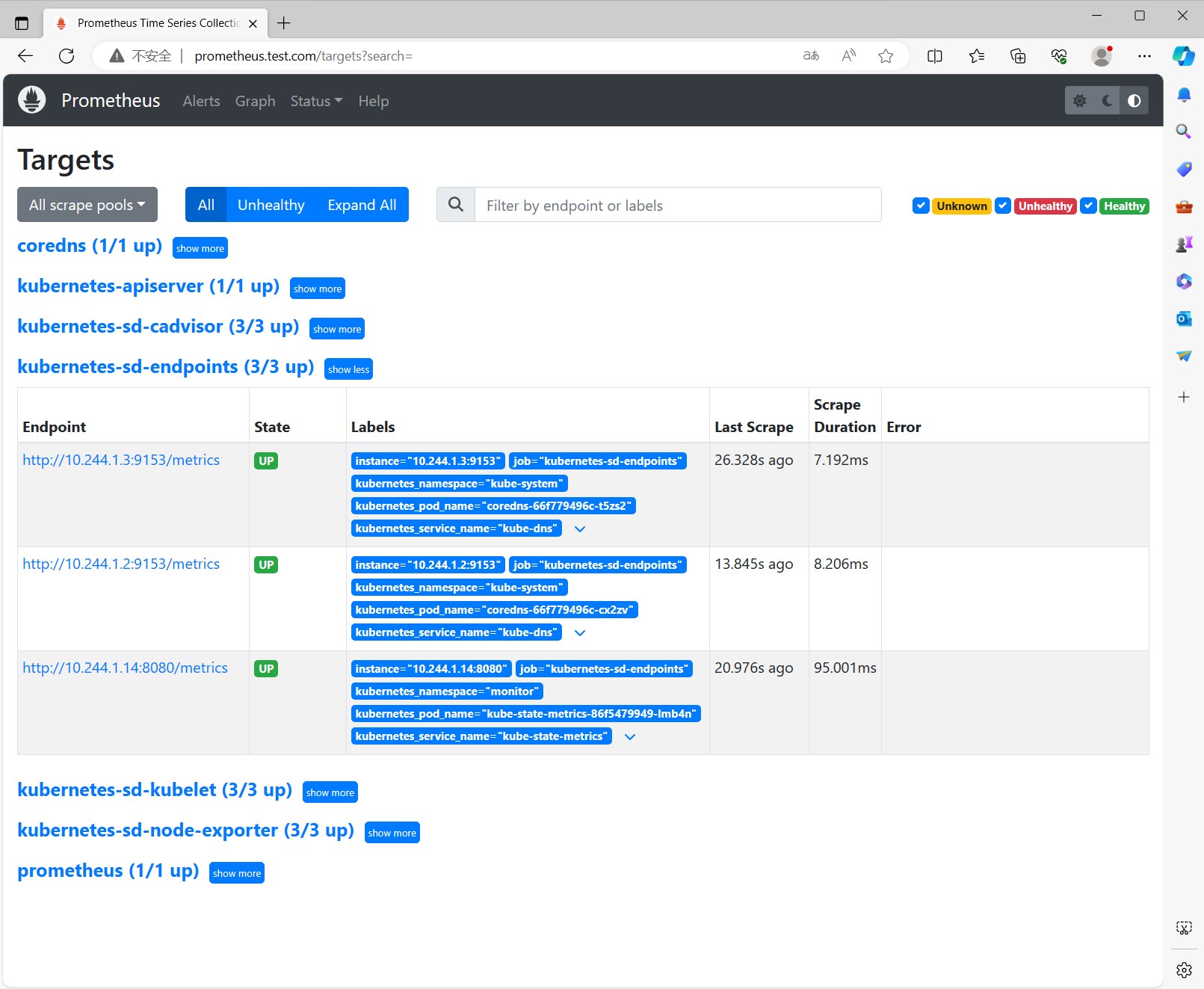
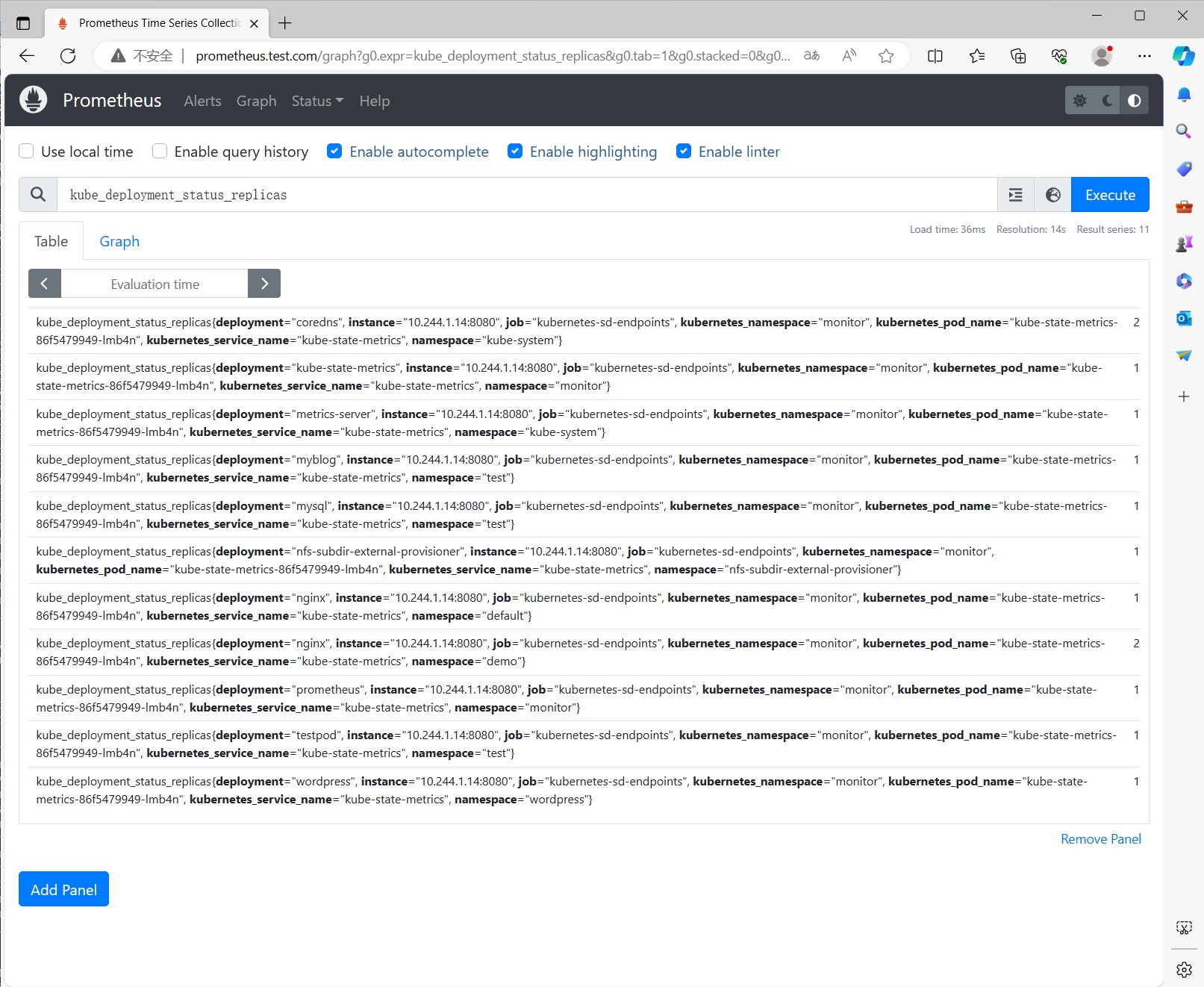
查看效果 不需要修改Prometheus的配置文件了,因为有了kubernetes-sd-endpoints的服务发现,直接查看targets列表,可以看到kubenetes-sd-endpoints下已经添加了kube-state-metrics的监控目标。
查看kube-state-metrics的监控指标,比如kube_pod_container_status_running,kube_deployment_status_replicas,kube_deployment_status_replicas_unavailable等。