全部的 K8S学习笔记总目录,请点击查看。
CI/CD 是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法。CI/CD 的核心概念是持续集成、持续交付和持续部署。作为一种面向开发和运维团队的解决方案,CI/CD 主要针对在集成新代码时所引发的问题。这里主要介绍jenkins的使用。
ci/cd常用的持续集成工具:
- travis-ci
- circleci
- bamboo
- teamcity
- gitlabci
- jenkins
- tekton
- argo
- spinnaker
- drone
- concourse
- 等等……
本次要实现的效果是基于k8s集群部署gitlab、sonarQube、Jenkins等工具,并把上述一些工具集成到Jenkins中,以Django项目和SpringBoot项目为例,通过多分支流水线及Jenkinsfile实现项目代码提交到不同的仓库分支,实现自动代码扫描、单元测试、docker容器构建、k8s服务的自动部署。
其中包含的内容有:
- DevOps、CI、CD介绍
- Jenkins、sonarQube、gitlab的快速部署
- Jenkins初体验
- 流水线入门及Jenkinsfile使用
- Jenkins与Kubernetes的集成
- sonarQube代码扫描与Jenkins的集成
- 实践Django项目的基于Jenkinsfile实现开发、测试环境的CI/CD
DevOps、CI、CD介绍
CI/CD就是持续集成 Continuous Integration (CI) / 持续交付Continuous Delivery (CD)
一般的软件交付流程如下:
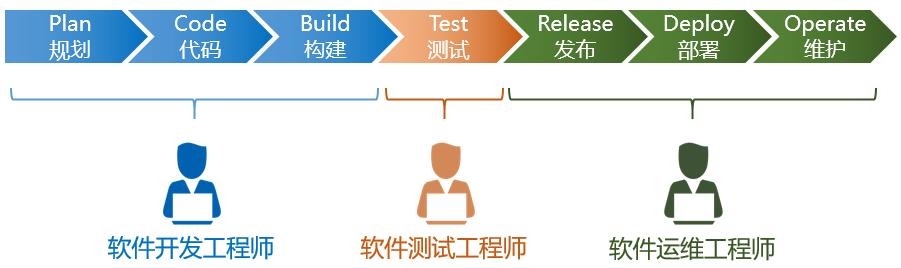
软件交付发展历程
一个软件从零开始到最终交付,大概包括以下几个阶段:规划、编码、构建、测试、发布、部署和维护,基于这些阶段,我们的软件交付模型大致经历了几个阶段:
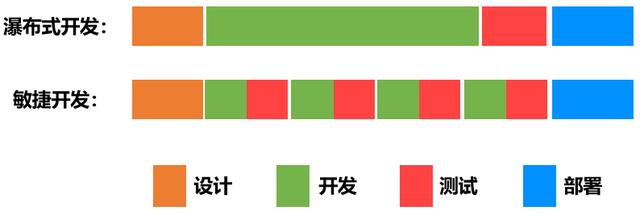
瀑布式流程
软件交付的早期阶段,大家都是采用瀑布式流程,如下图所示:

前期需求确立之后,软件开发人员花费数周和数月编写代码,把所有需求一次性开发完,然后将代码交给QA(质量保障)团队进行测试,然后将最终的发布版交给运维团队去部署。
瀑布模型,简单来说,就是等一个阶段所有工作完成之后,再进入下一个阶段。这种模式的问题也很明显,产品迭代周期长,灵活性差。一个周期动辄几周几个月,适应不了当下产品需要快速迭代的场景。
敏捷开发
为了解决瀑布模型的问题,以及更好地适应当下快速迭代的场景,敏捷开发模式越来越多地被采用。敏捷开发模式的核心是任务由大拆小,开发、测试协同工作,注重开发敏捷,不重视交付敏捷。
DevOps
敏捷开发模式注重开发敏捷,不重视交付敏捷。那么如何解决交付敏捷呢?DevOps就是为了解决这个问题而诞生的。
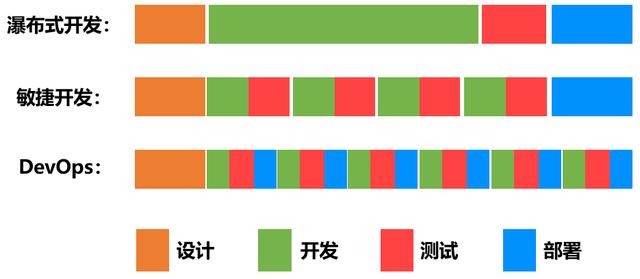
开发、测试、运维协同工作, 持续开发+持续交付。
DevOps的工具链
我们是否可以认为DevOps = 提倡开发、测试、运维协同工作来实现持续开发、持续交付的一种软件交付模式?为什么最初的开发模式没有直接进入DevOps的时代?
原因是:沟通成本。
各角色人员去沟通协作的时候都是手动去做,交流靠嘴,靠人去指挥,很显然会出大问题。所以说不能认为DevOps就是一种交付模式,因为解决不了沟通协作成本,这种模式就不具备可落地性。
那DevOps时代如何解决角色之间的成本问题?DevOps的核心就是自动化。自动化的能力靠什么来支撑,工具和技术。
DevOps工具链
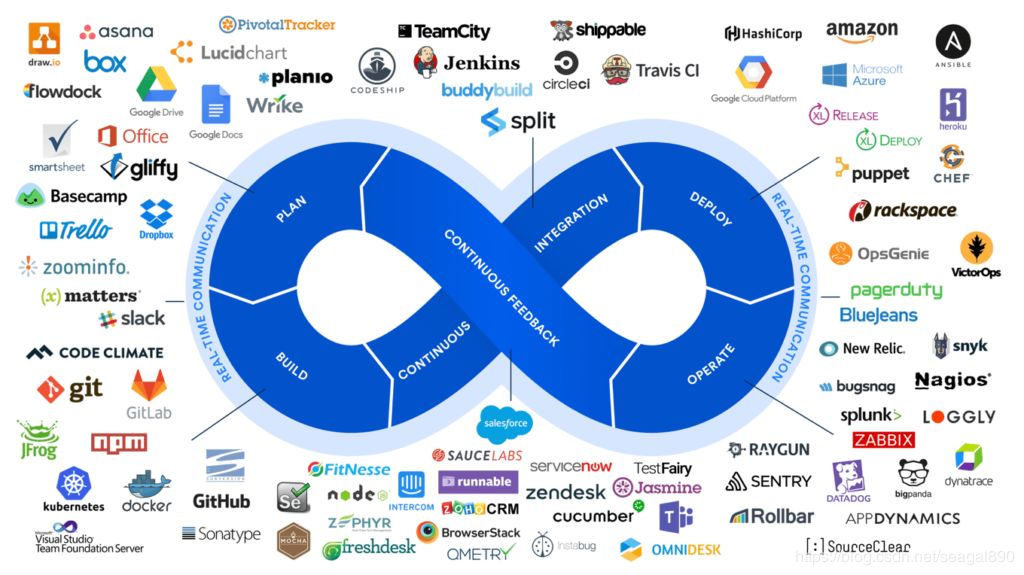
靠这些工具和技术,才实现了自动化流程,进而解决了协作成本,使得devops具备了可落地性。因此我们可以大致给devops一个定义:
devops = 提倡开发、测试、运维协同工作来实现持续开发、持续交付的一种软件交付模式 + 基于工具和技术支撑的自动化流程的落地实践。
因此devops不是某一个具体的技术,而是一种思想+自动化能力,来使得构建、测试、发布软件能够更加地便捷、频繁和可靠的落地实践。本次核心内容就是要教会大家如何利用工具和技术来实现完整的DevOps平台的建设。我们主要使用的工具有:
- gitlab,代码仓库,企业内部使用最多的代码版本管理工具。
- Jenkins, 一个可扩展的持续集成引擎,用于自动化各种任务,包括构建、测试和部署软件。
- robotFramework, 基于Python的自动化测试框架
- sonarqube,代码质量管理平台
- maven,java包构建管理工具
- Kubernetes
- Docker
Kubernetes环境中部署jenkins
本次部署使用helm部署的方式,也可以使用yaml文件部署,参考其他部署方式
注意点:
- 第一次启动很慢
- 因为后面Jenkins会与kubernetes集群进行集成,会需要调用kubernetes集群的api,因此安装的时候创建了ServiceAccount并赋予了cluster-admin的权限
- 初始化容器来设置权限
- ingress来外部访问
- 数据存储通过pvc挂载到宿主机中
安装jenkins
1 | 新建chart仓库 |
由于默认的插件地址安装非常慢,我们可以替换成国内清华的源,进入 jenkins 工作目录,目录下面有一个 updates 的目录,下面有一个 default.json 文件,我们执行下面的命令替换插件地址:
1 | $ kubectl -n jenkins exec -it jenkins-0 -c jenkins -- bash |
暂时先不用重新启动pod,汉化后一起重启。
配置升级站点的URL:
- 进入 web ui 的界面,点击 Manage Jenkins -> Plugins 按钮,进入插件管理页面:http://jenkins.test.com/manage/pluginManager/advanced
- 选择最后一项 Advanced settings
- 在 Update Site 中将原有url替换为:https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
- 点击 Submit 按钮,保存设置
接下来我们就可以重启服务了。重启jenkins服务有两种方式:
- 删除pod,kubernetes会自动重启
- 访问下面这个url重启:http://jenkins.test.com/restart/ 这样重启的话,pod不会重建
安装插件
分别点击以下菜单 Jenkins -> Manage Jenkins -> Plugins -> Avaliable plugins
主要安装以下插件:
- GitLab
- Pipeline: Multibranch
- Blue Ocean
- Localization: Chinese (Simplified)
Gogs (太老了,没有维护,但是gitlab比较重,这里先安装gogs,仅实验使用,之后webhook和gitlab用法相同)- gitea (gogs的继承者,安装gogs已经很久没有维护了,这里安装gitea)
- Generic Webhook Trigger
如果安装超时,需要查看之前更改的数据源是否生效,如果没有生效,需要重新配置。
选中后,选择[Install],等待下载完成,然后点击[ Restart Jenkins when installation is complete and no jobs are running ],让Jenkins自动重启
启动后,界面默认变成中文。
Kubernetes环境中部署gogs
gogs已经很久没有维护了,这里仅记录一下安装过程,下一节我们会使用gitea。
这里我们需要一个git仓库,因为实验使用的环境比较轻量,因此选用gogs来部署。
安装gogs
gogs的helm仓库已经很老了,因此整理了以下的资源清单,使用k8s部署gogs。
1 | # postgres secret |
有了资源配置清单,我们就可以部署gogs了。
1 | # 创建命名空间 |
全部容器启动成功后,我们就可以配置host然后通过浏览器访问gogs了。

这时可以点击右上角的注册按钮,注册一个账户,在gogs中id=0,也就是第一个注册的账户,是管理员账户,可以创建组织、创建仓库等操作。
注册完成后,我们就可以使用这个账户登录gogs了。
创建仓库
安装完成gogs我们就可以创建一个仓库了。这里创建一个django项目的仓库,仓库名称为moonlight。创建方法与github类似,这里就不再赘述。
创建完成后的仓库如下图所示:
然后就可以创建django项目了,然后将远程仓库地址添加到django项目中,合并后提交到远程仓库。
1 | $ django-admin startproject moonlight |
通过gogs的网页,可以看到代码已经提交到了仓库中。
配置jenkins
在gogs中,我们可以配置webhook,当代码提交到仓库后,会触发webhook,然后调用jenkins的接口,从而触发jenkins的流水线。
webhook触发的是jenkins的流水线,因此我们需要先创建一个流水线,然后再配置webhook。
因此我们先创建一个流水线
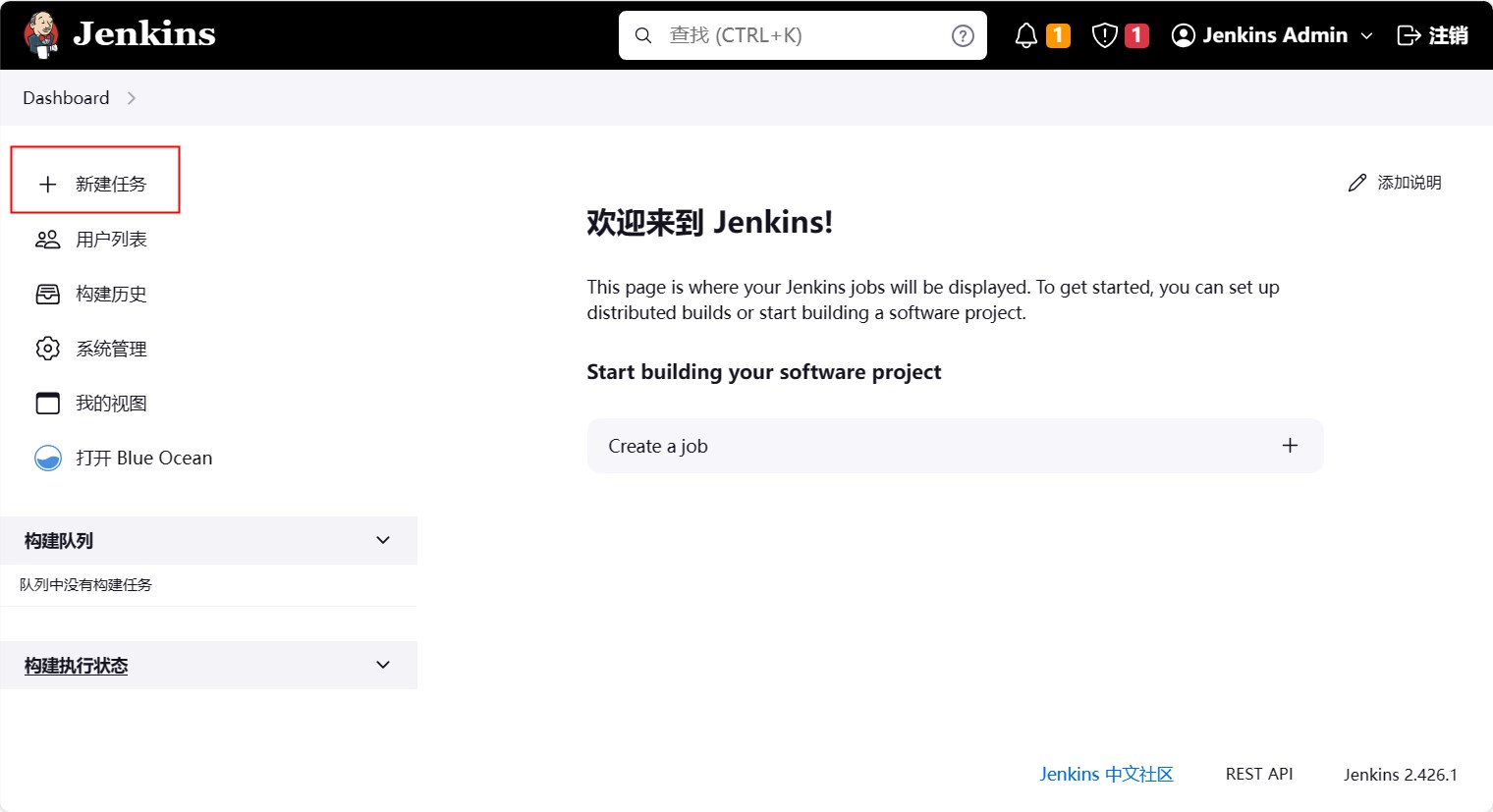
然后选择自由风格的软件项目,名字叫free-style-demo,然后点击确定。
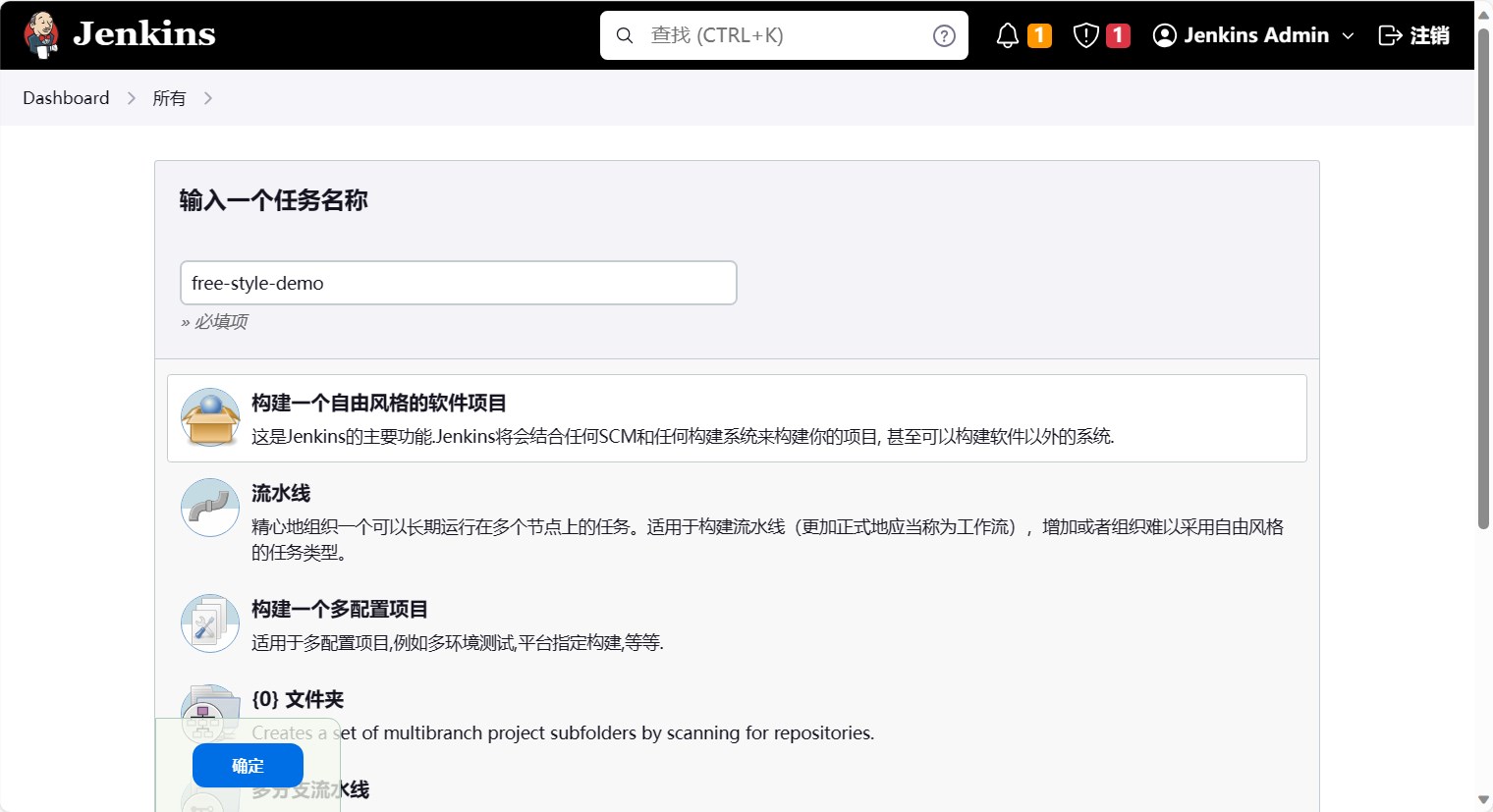
然后我们就可以配置流水线了。首先我们先配置源码管理。选择git,然后填写仓库地址,这里填写的是gogs的仓库地址。然后当焦点离开仓库地址的时候,会发现git报错了,提示指定一个git仓库。
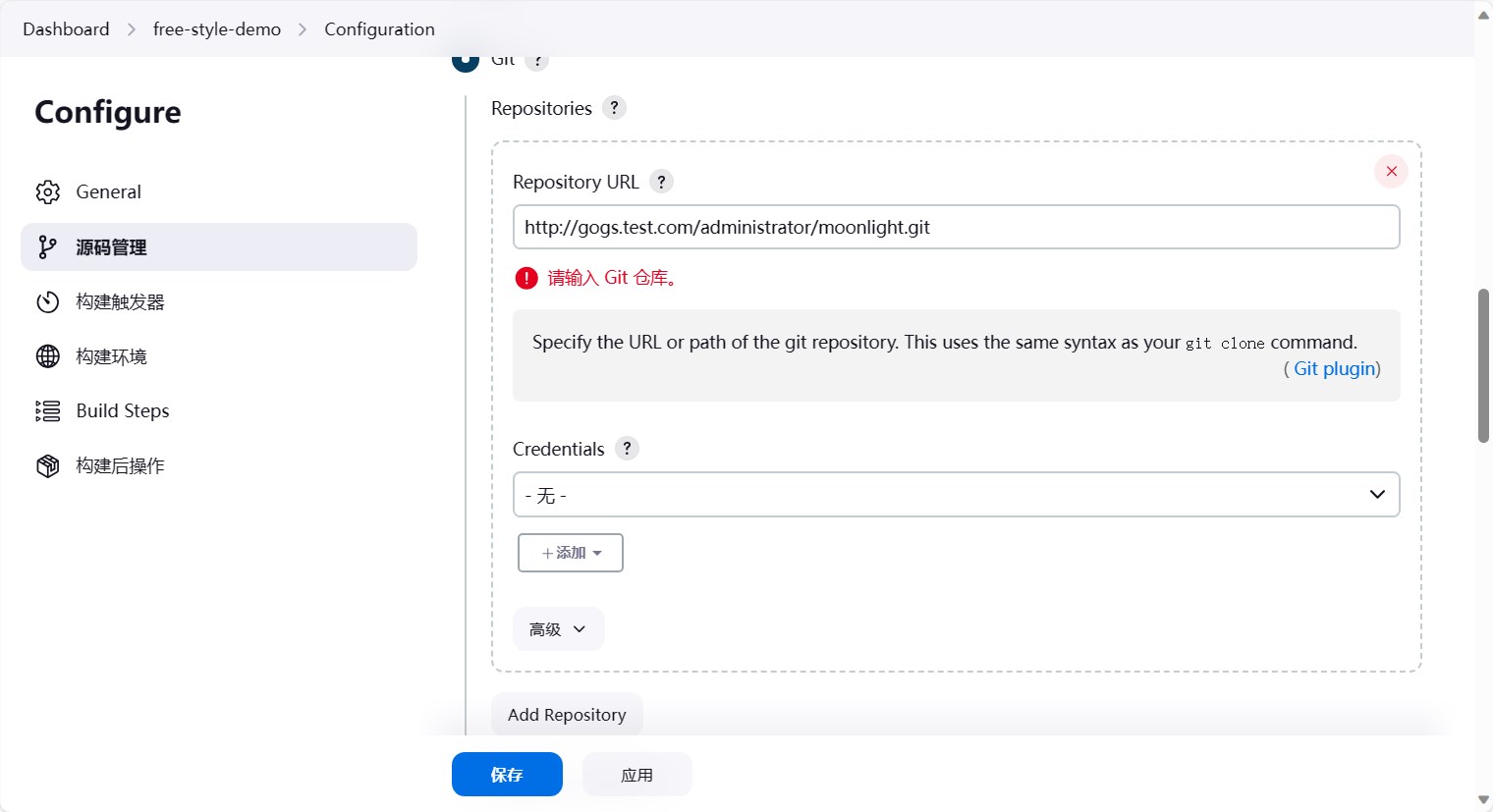
这是因为我们使用的是url地址,而k8s内部无法解析这个地址,要想解决这个问题,有两种方式:
1. 在容器内配置hosts2. 配置coredns的静态解析
这里我们使用第二种方式,配置coredns的静态解析。
1 | $ kubectl -n kube-system edit configmap coredns |
然后保存即可。保存后我们再回到jenkins的配置页面,重新刷新配置,发现git的报错已经消失了。
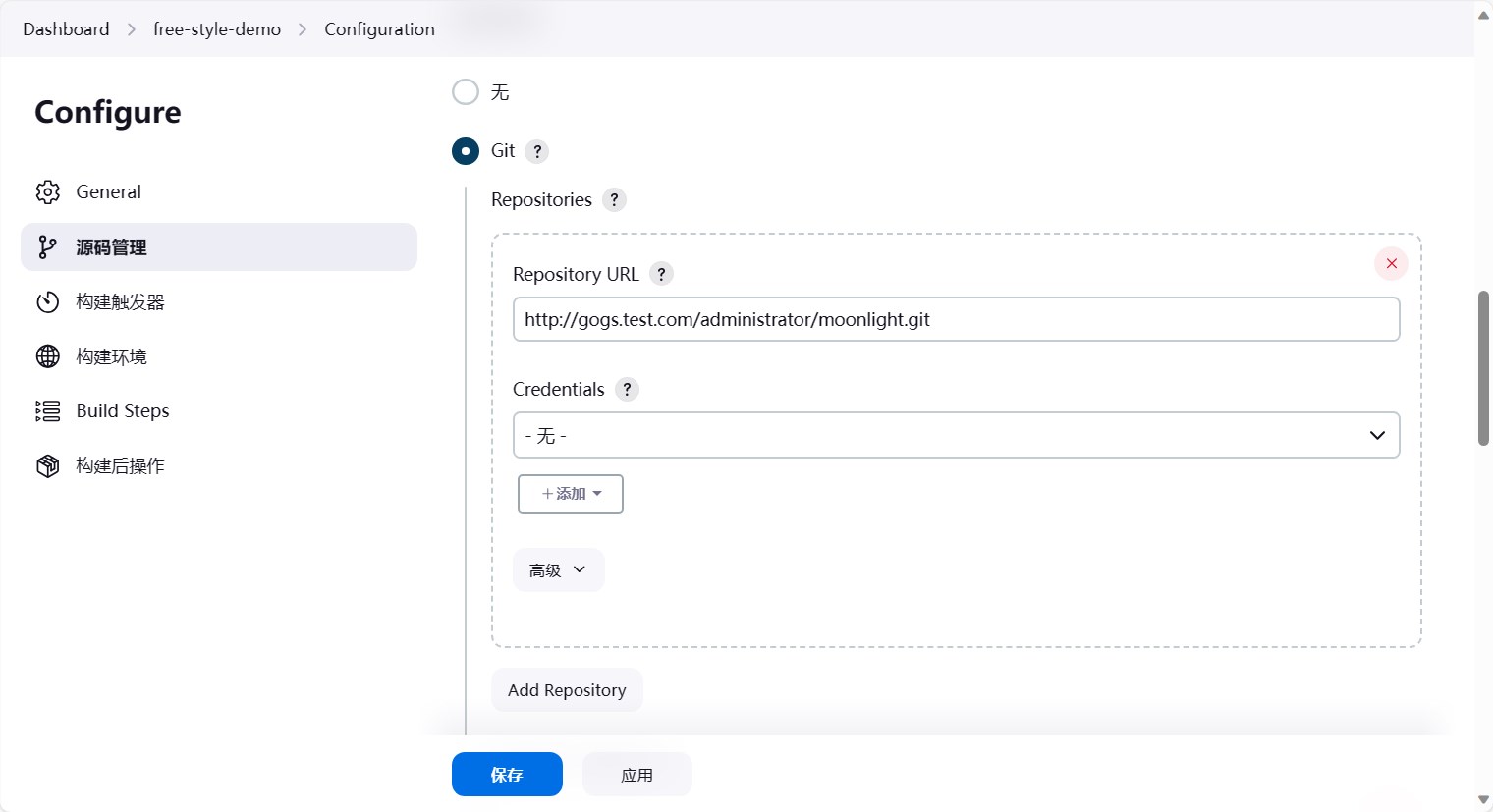
因为这里我们的仓库是公有的,因此不需要配置认证信息,如果是私有仓库,需要配置认证信息。
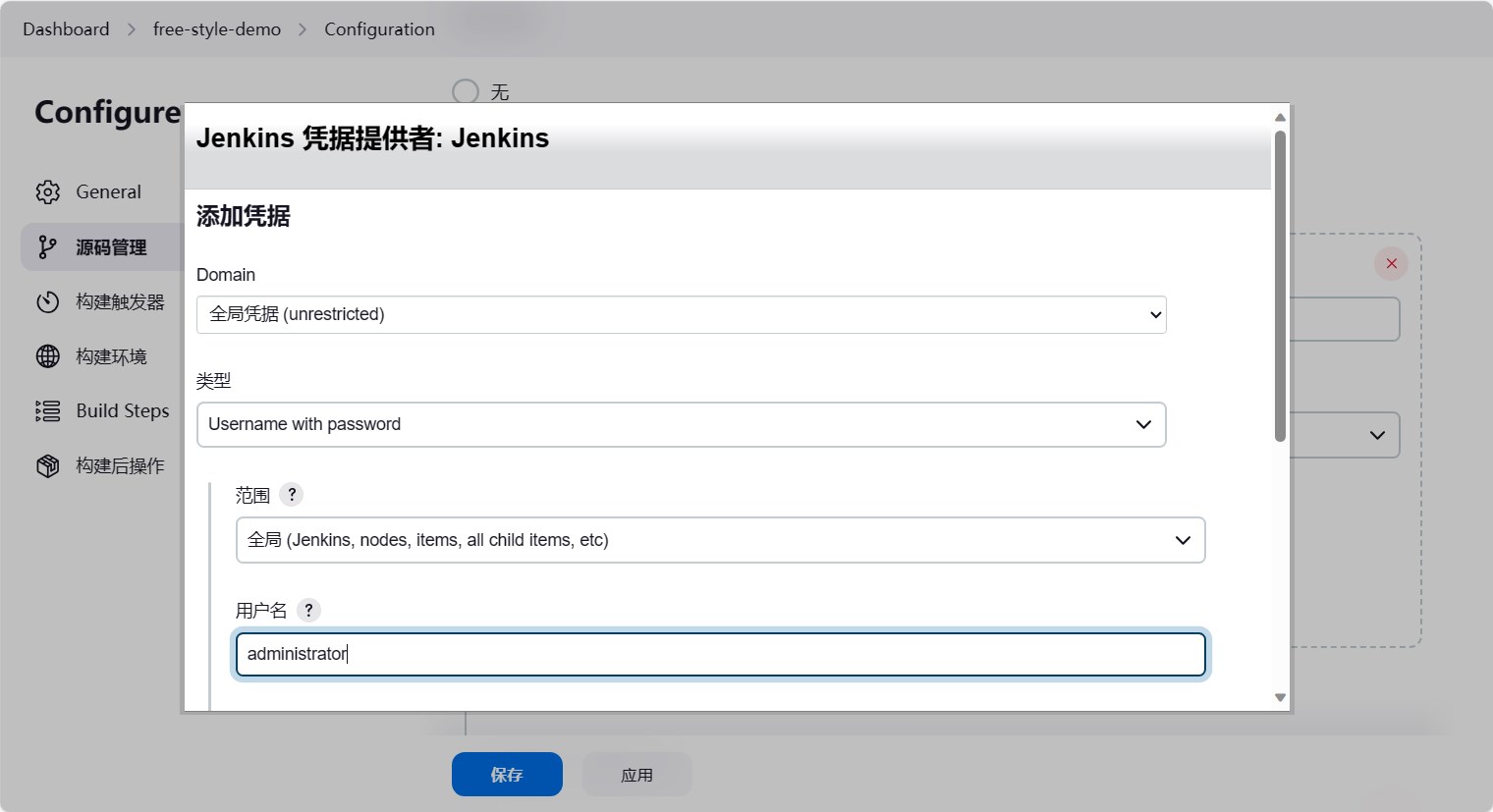
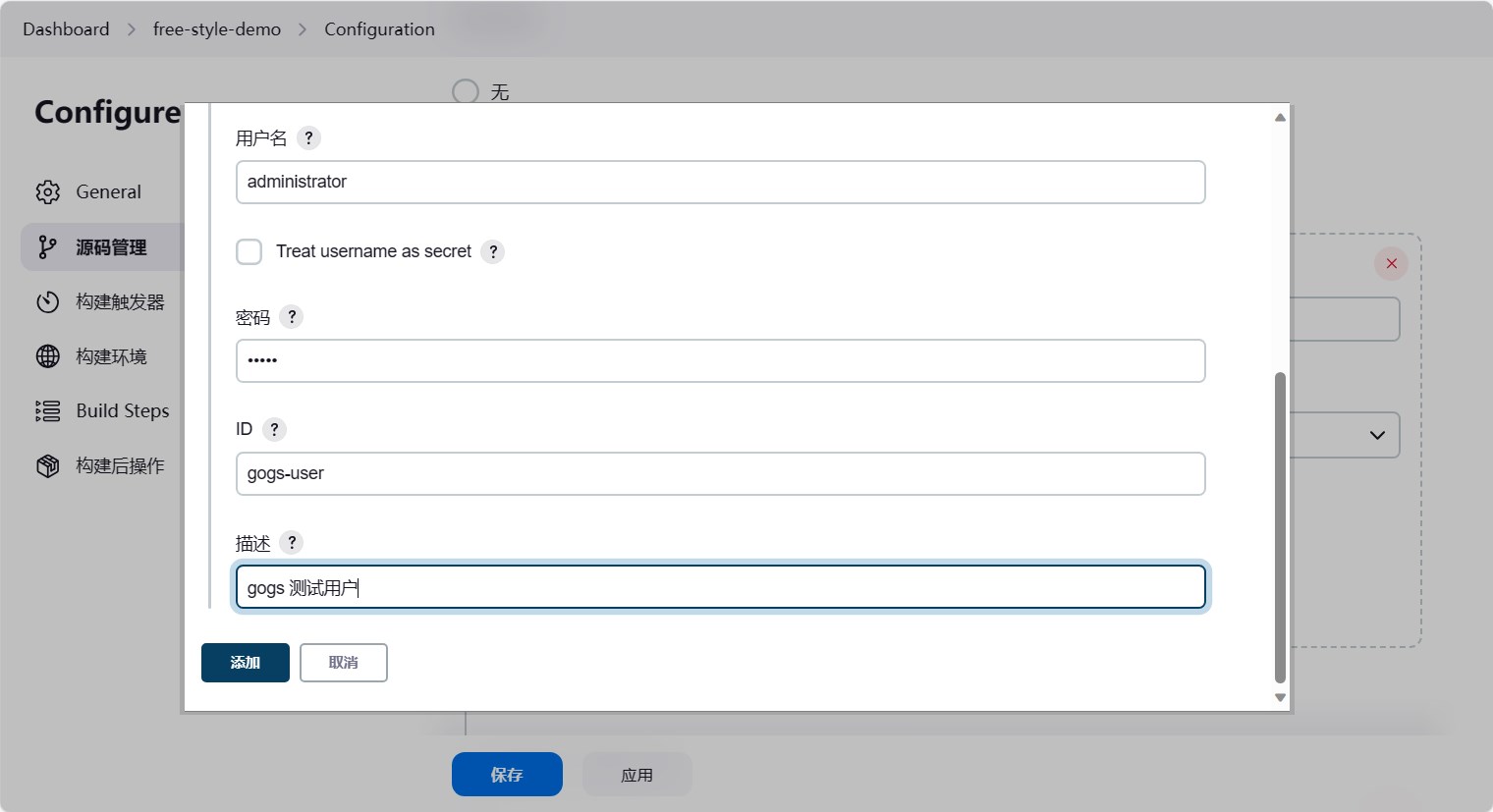
这里我们直接配置认证信息,做一个演示。点击添加,选择用户名密码,然后填写用户名密码,id保证内部唯一即可,然后点击添加。
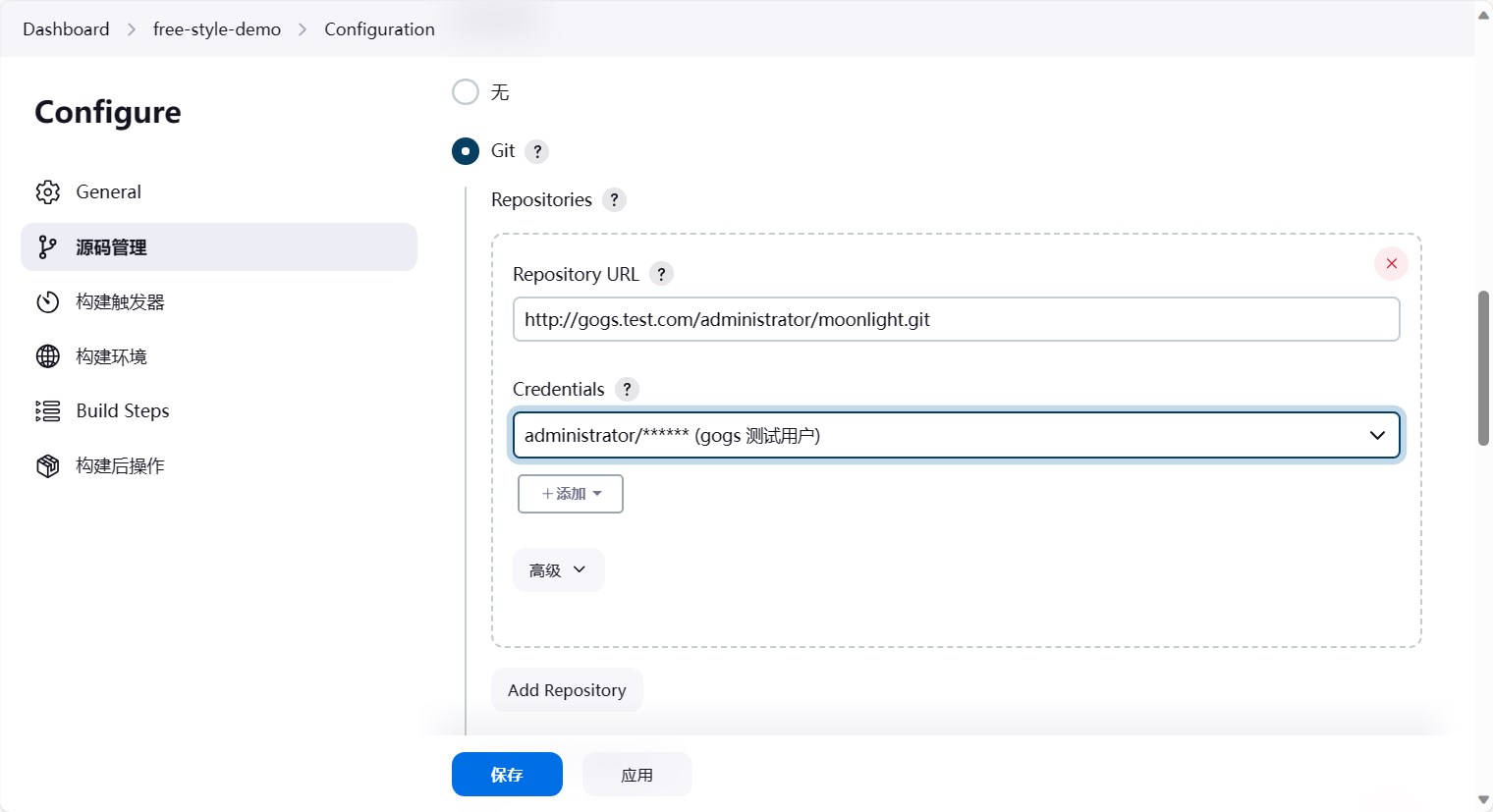
然后认证选择刚刚添加的认证信息。
往下走,构建触发器。这里我们选择”Build when a change is pushed to GoGS”,也就是当代码提交到gogs的时候,触发构建。
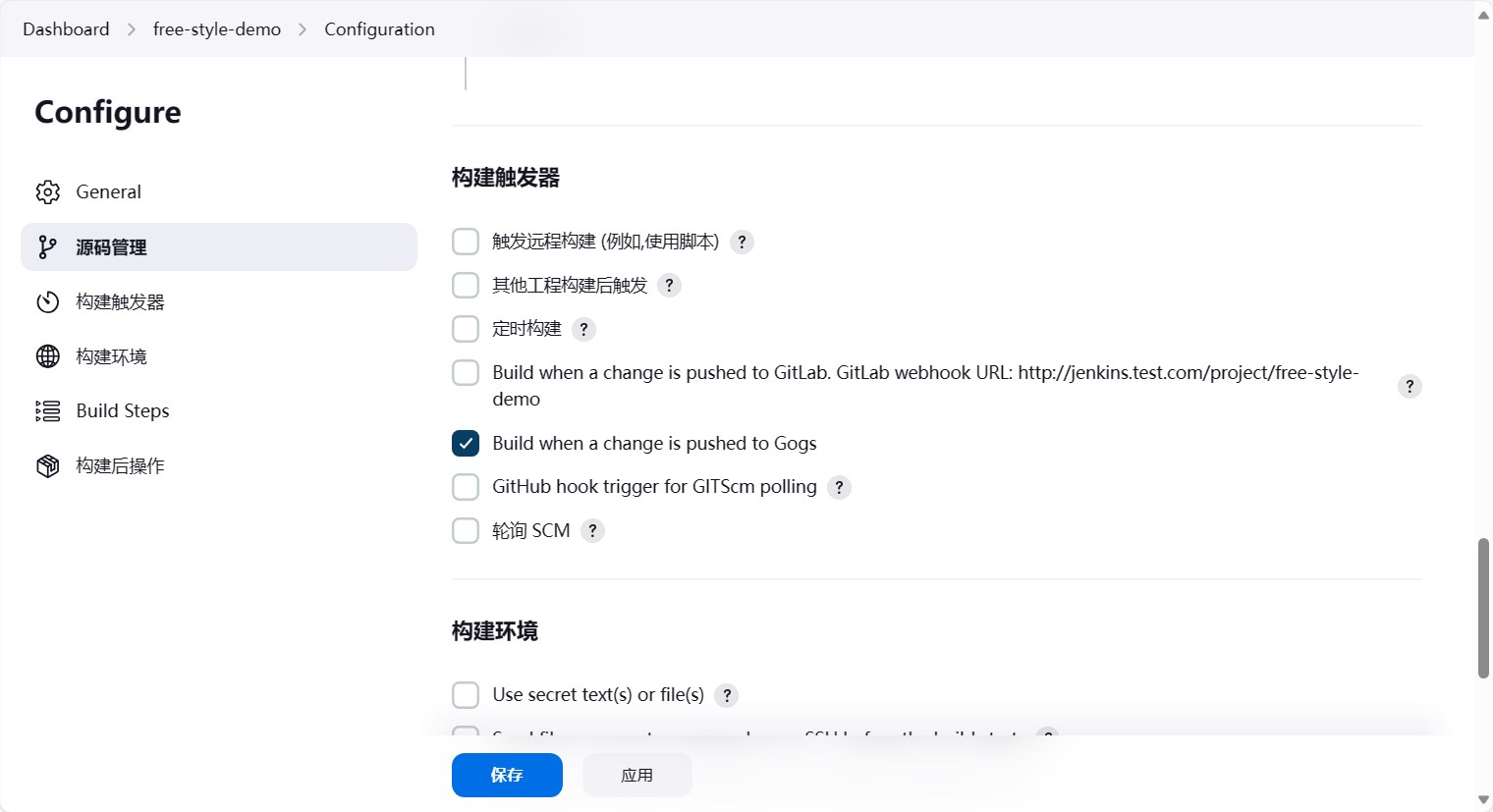
再往下,Build Steps,我们选择执行shell命令。这个就是说,当代码提交到gogs的时候,jenkins会下载代码,然后执行Buile Steps中的命令。
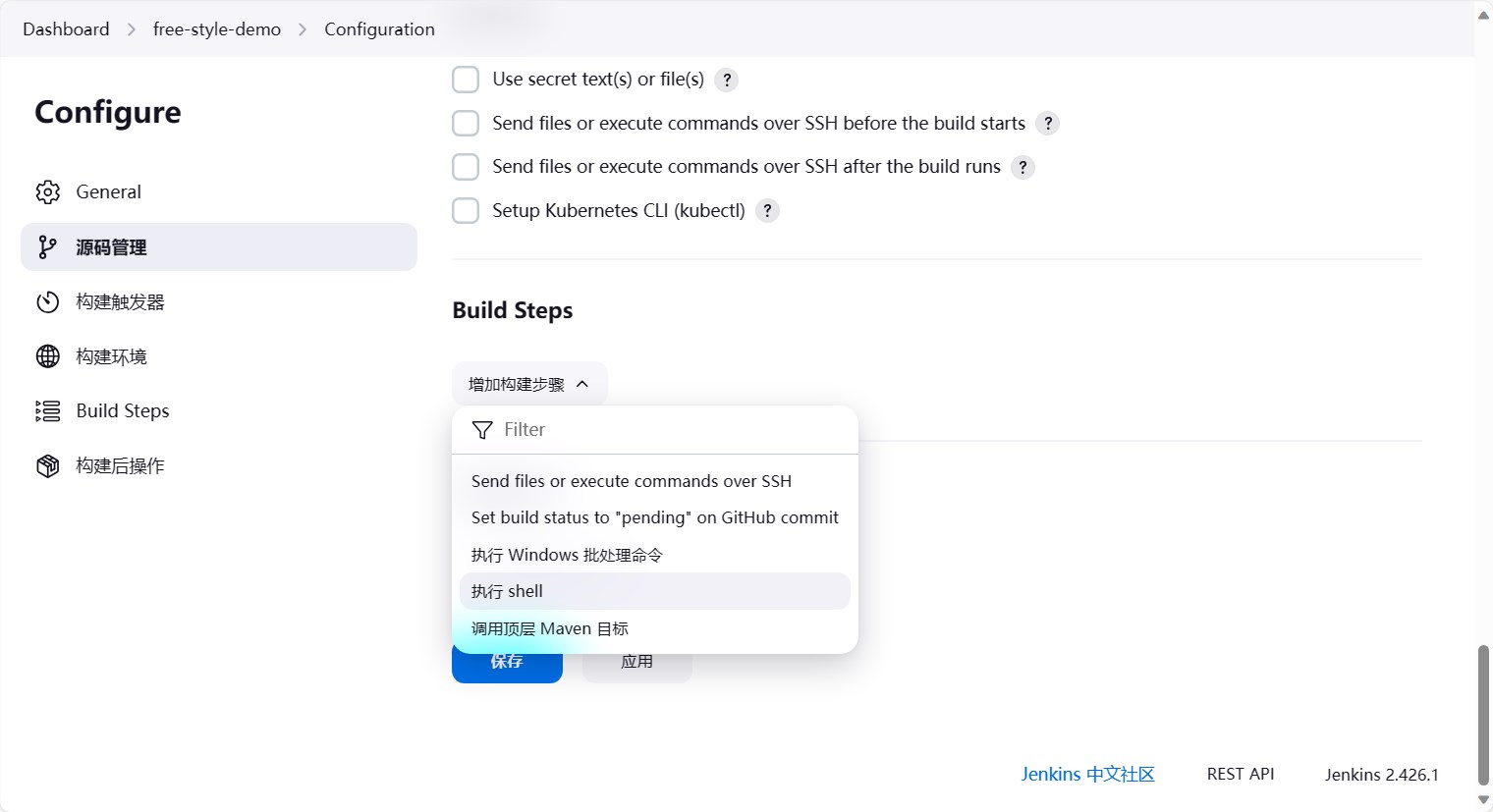
这里我们主要是测试,先写一个简单点的echo success,点击”可用的环境变量”,可以看到jenkins提供了很多环境变量,这些环境变量可以在shell中使用,这里也打印一个环境变量。
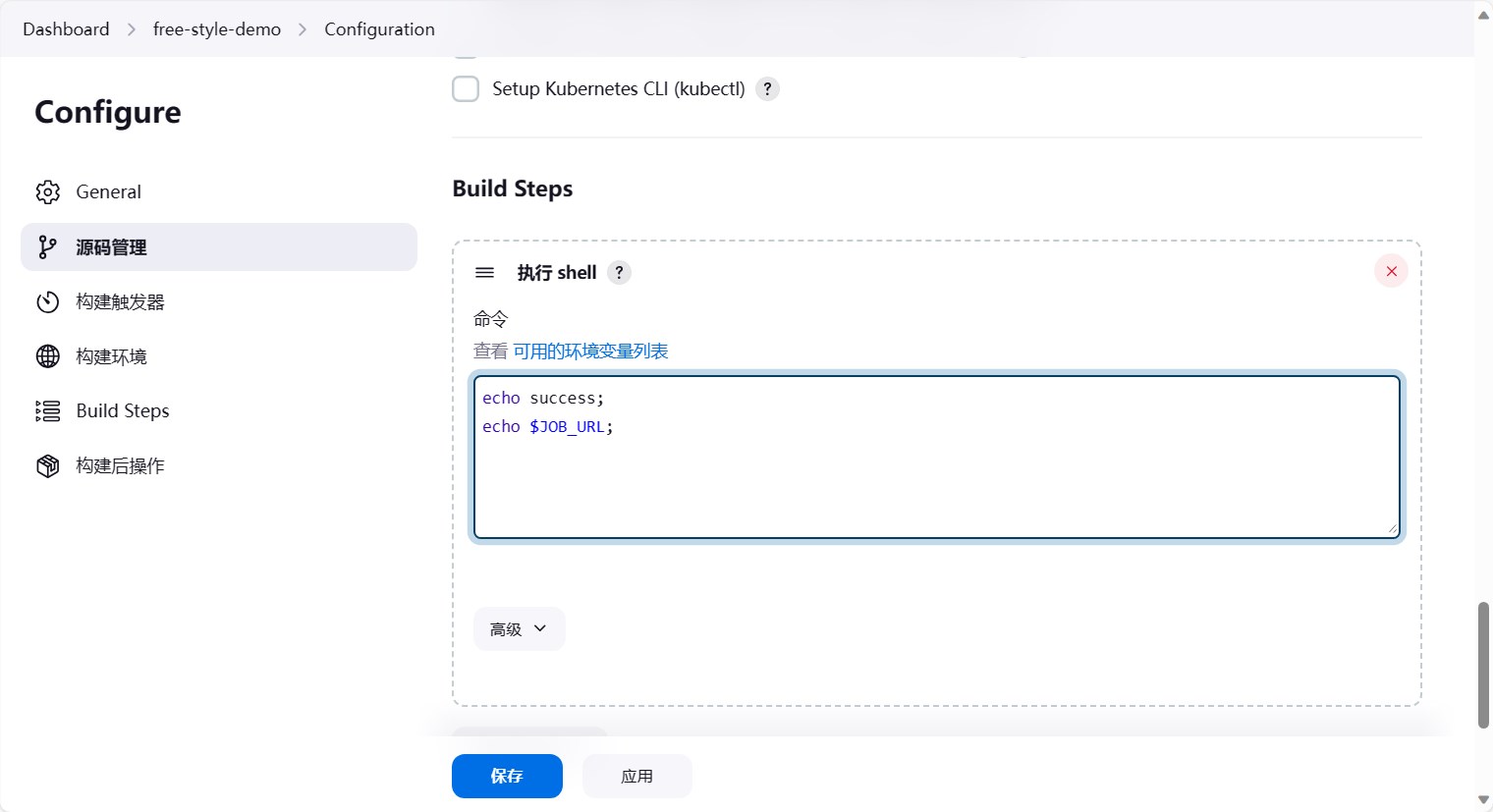
然后点击保存即可。
配置webhook
jenkins的流水线配置完成后,我们就可以配置webhook了。点击仓库的设置按钮,然后选择管理Web钩子,点击添加Web钩子,选择Gogs
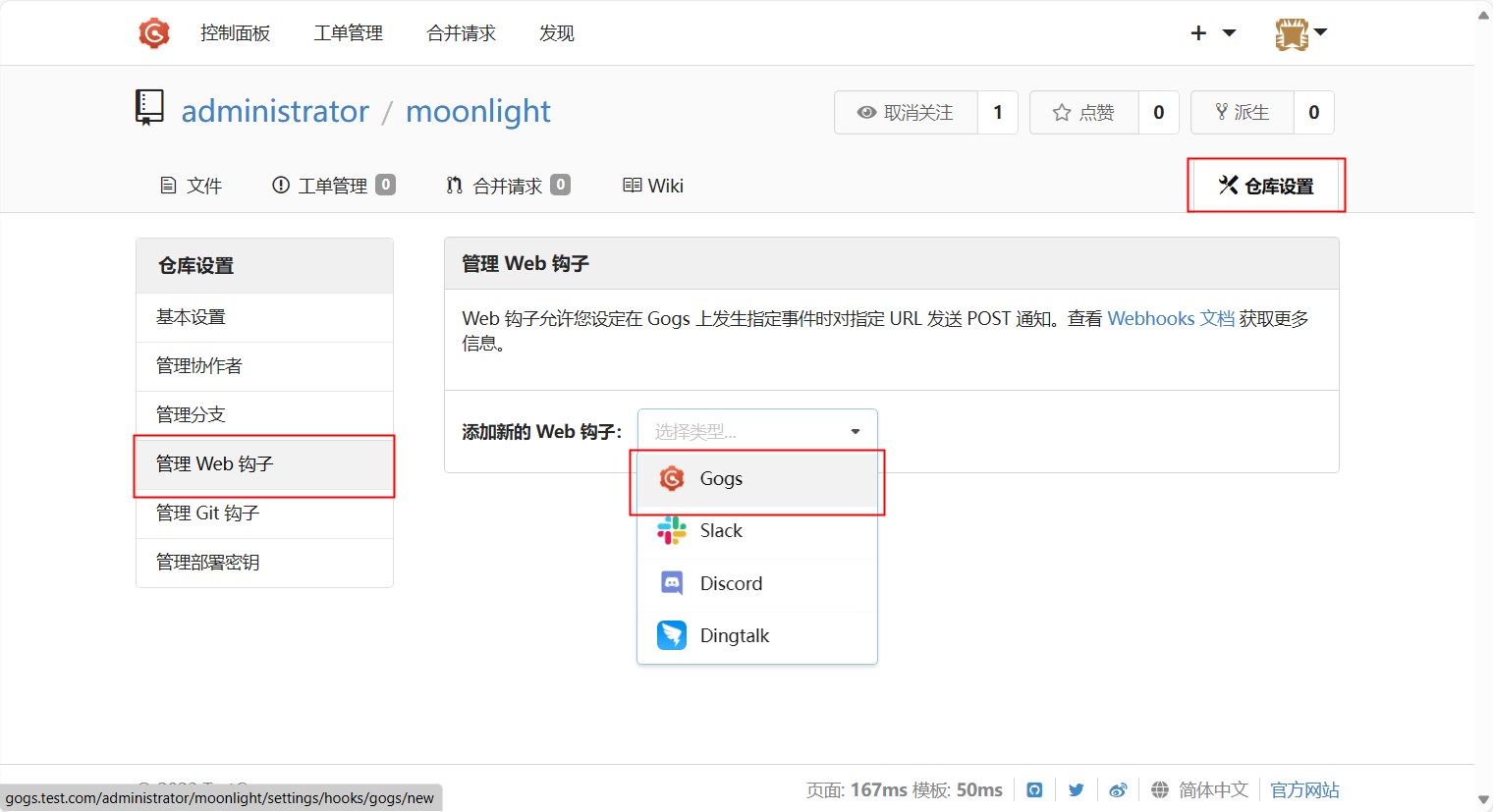
然后填写推送地址,推送地址为 http://jenkins.test.com/gogs-webhook/?job=free-style-demo ,这里的free-style-demo为jenkins的流水线名称。
gogs 配置的推送地址格式为
http(s)://<Jenkins地址>/gogs-webhook/?job=<Jenkins任务名>
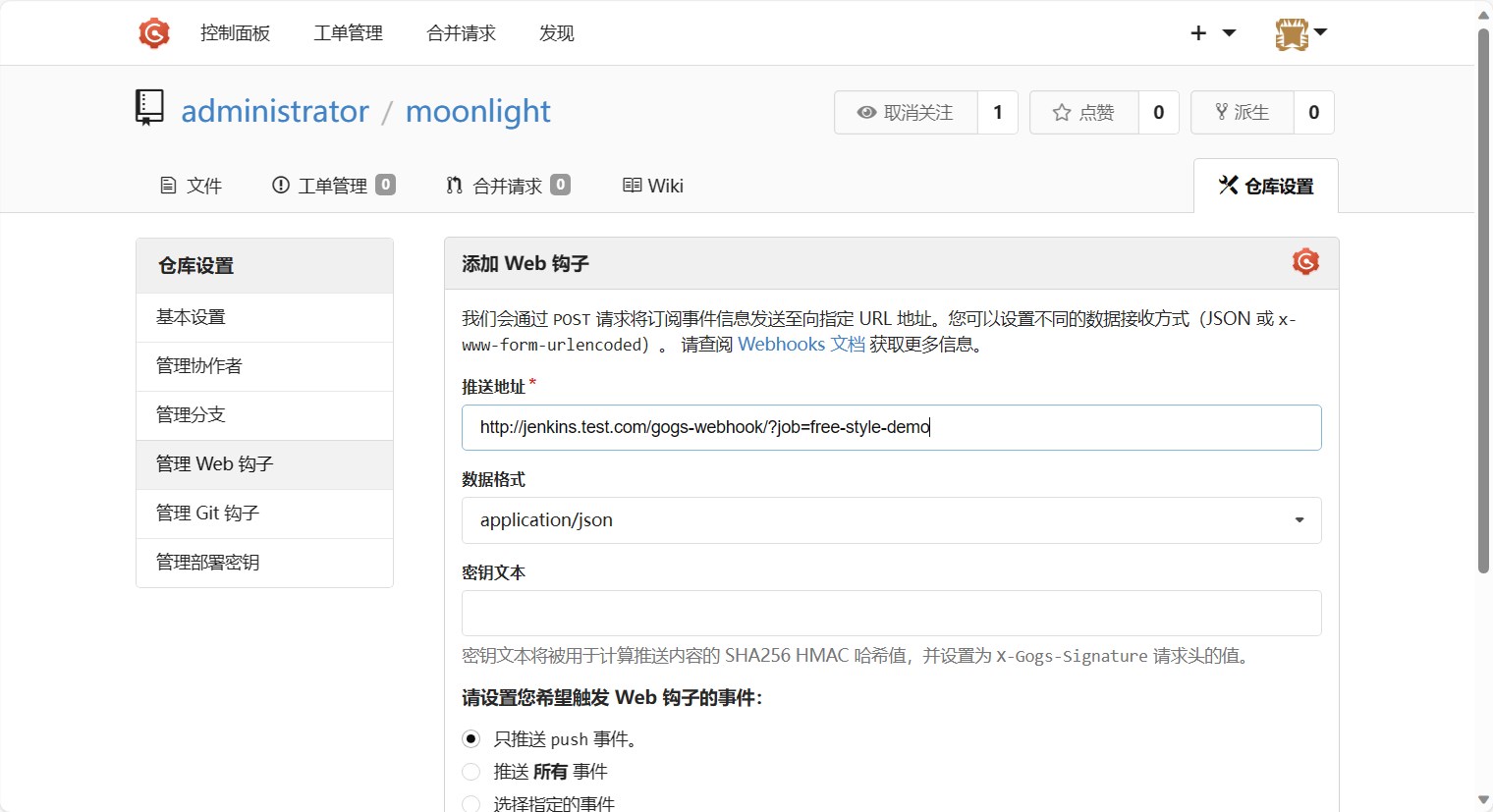
然后点击添加Web钩子即可。
添加成功后能看到Web钩子列表中多了一个Web钩子。
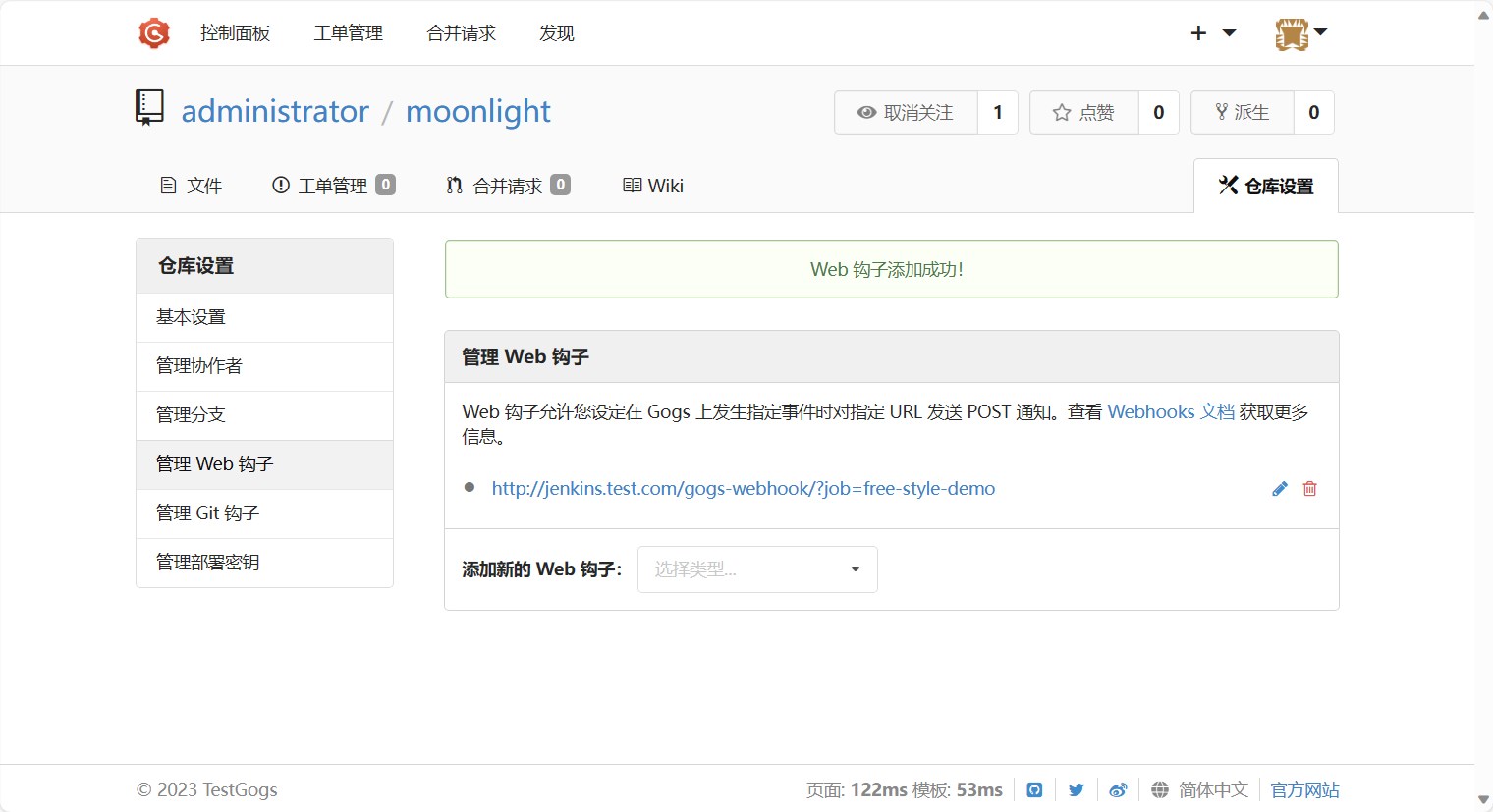
然后我们点进去,点击测试按钮,测试一下是否能够触发jenkins的流水线。然后就能看到测试已经推送了。
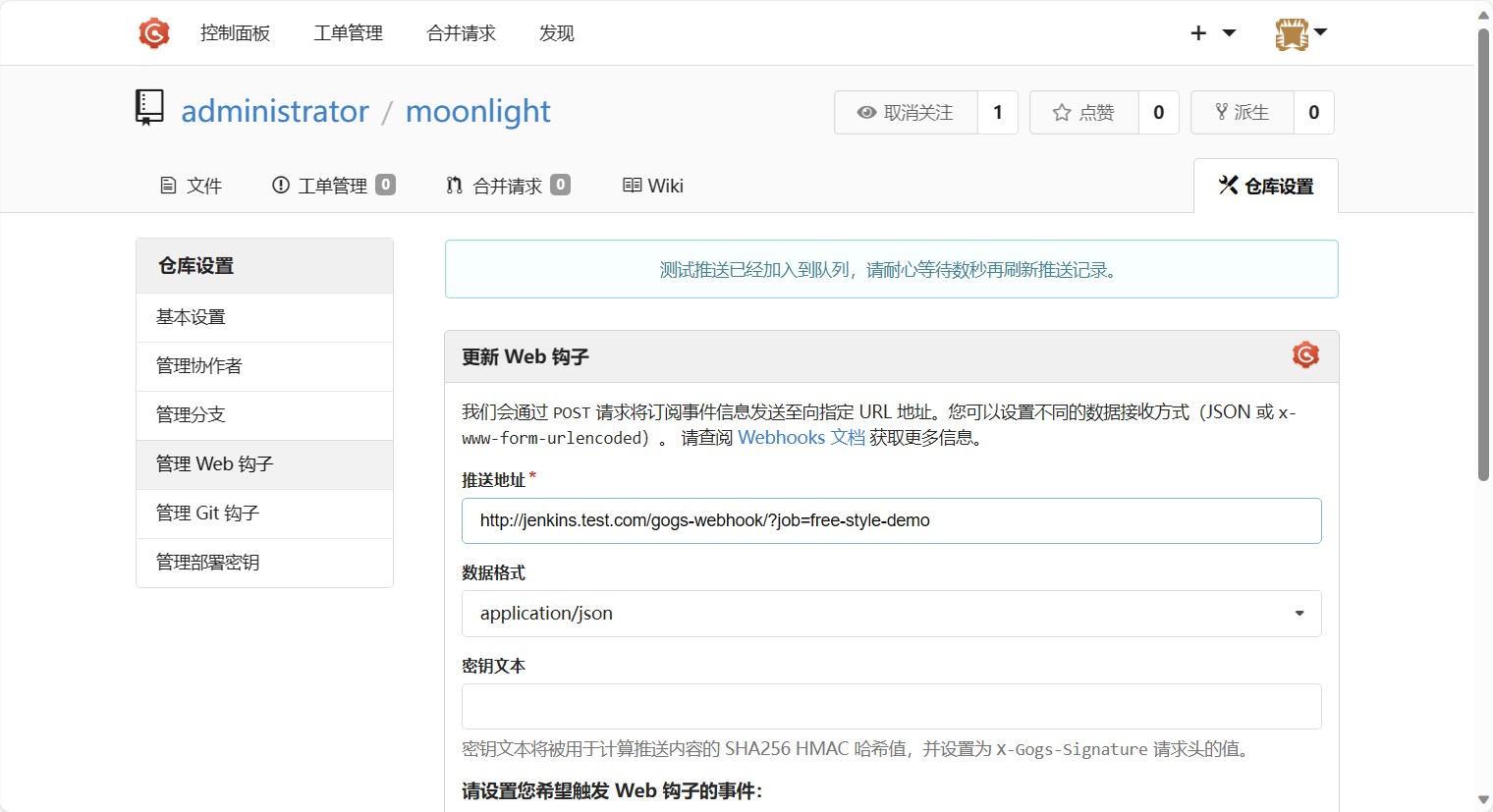
测试按钮底下也有一个成功的推送记录。
此时,去jenkins的流水线页面,可以看到流水线已经触发了。
触发构建
在moonlight项目中,创建一个test.md文件,然后提交到远程仓库,触发jenkins的流水线。
1 | $ echo "test" > test.md |
然后我们可以看到jenkins的流水线已经触发了。
等待build完成后,点击序号,可以看到build的日志。
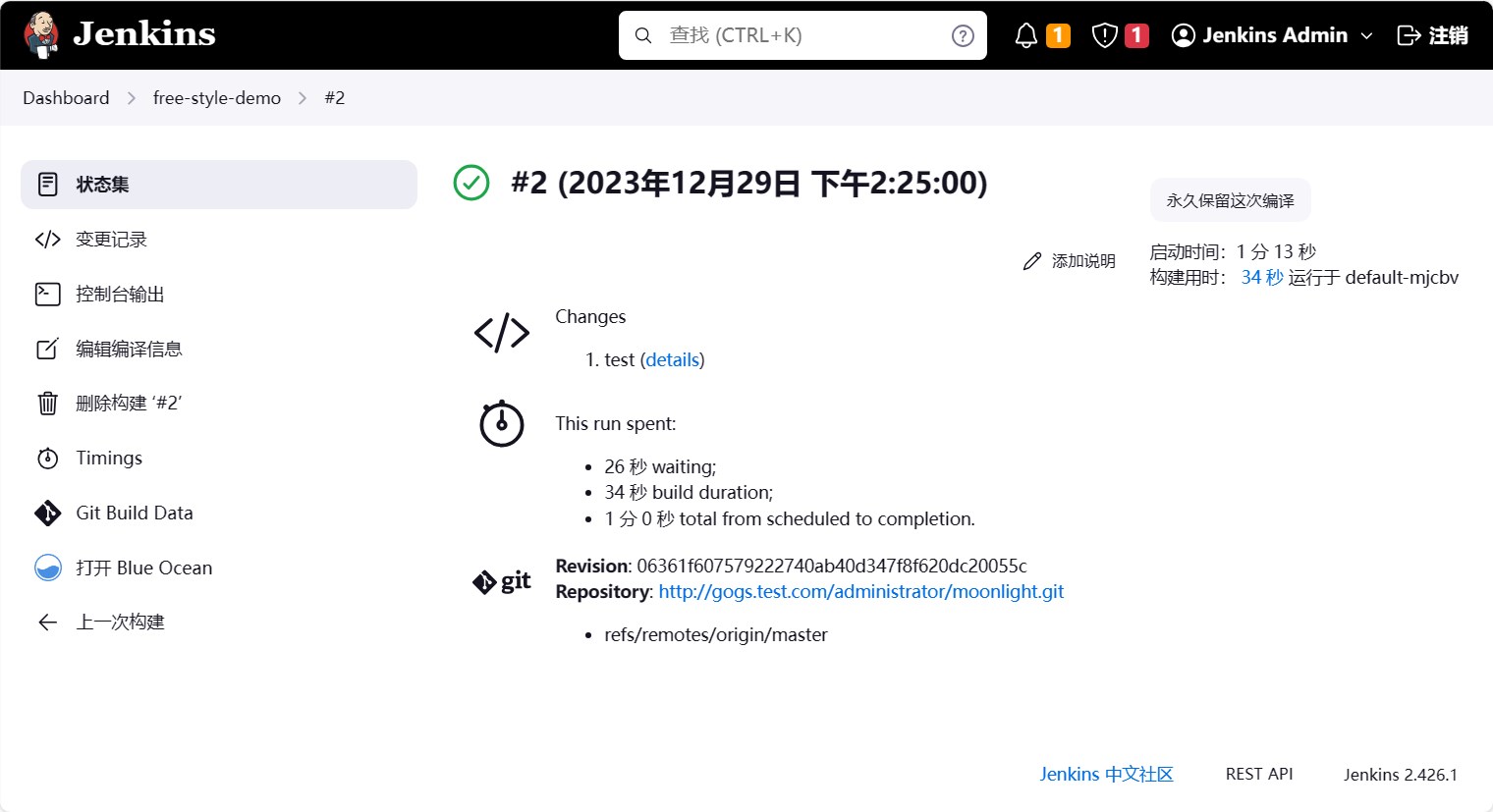
点击控制台输出,可以看到整个流水线的执行过程以及日志。
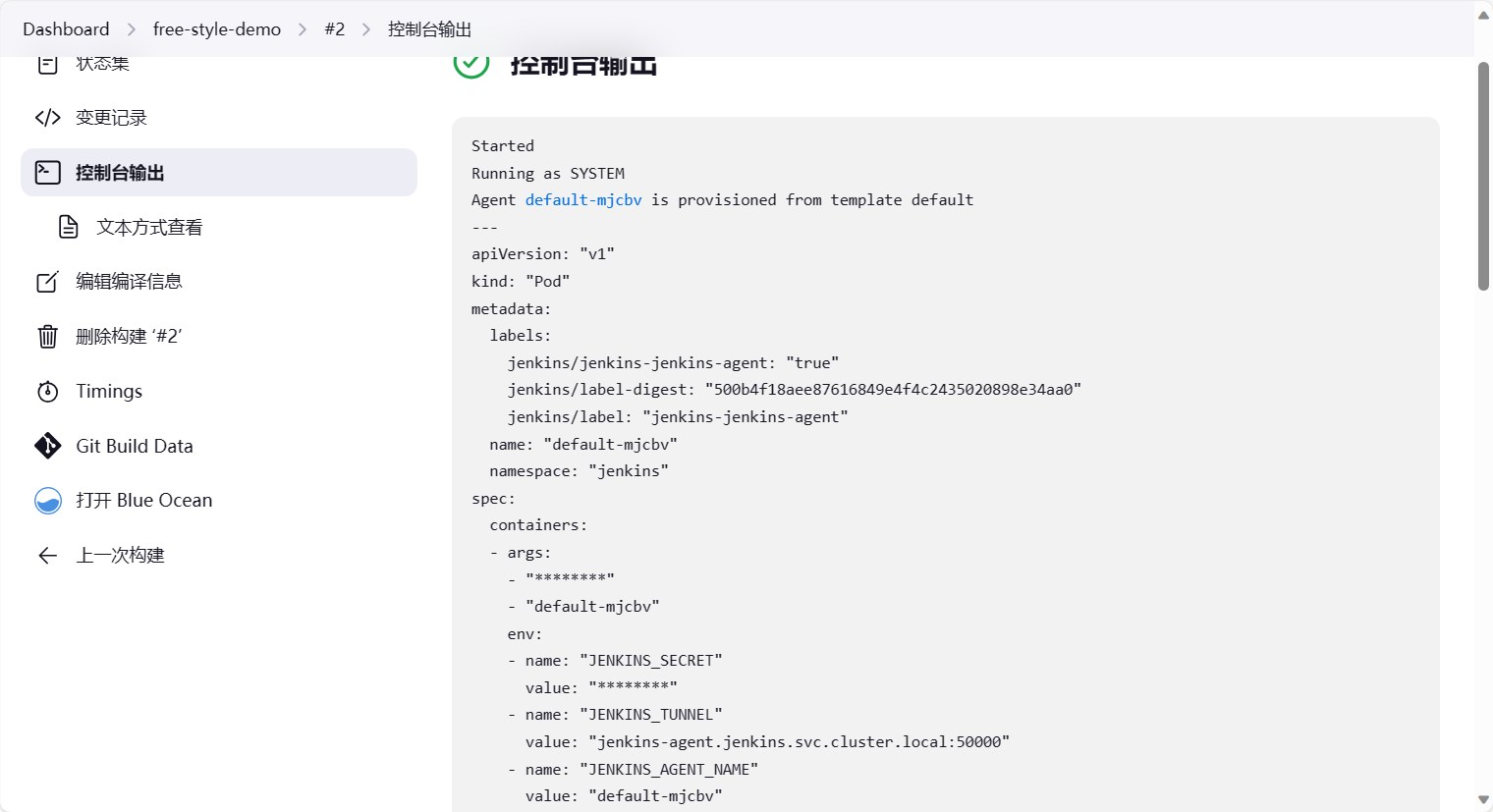
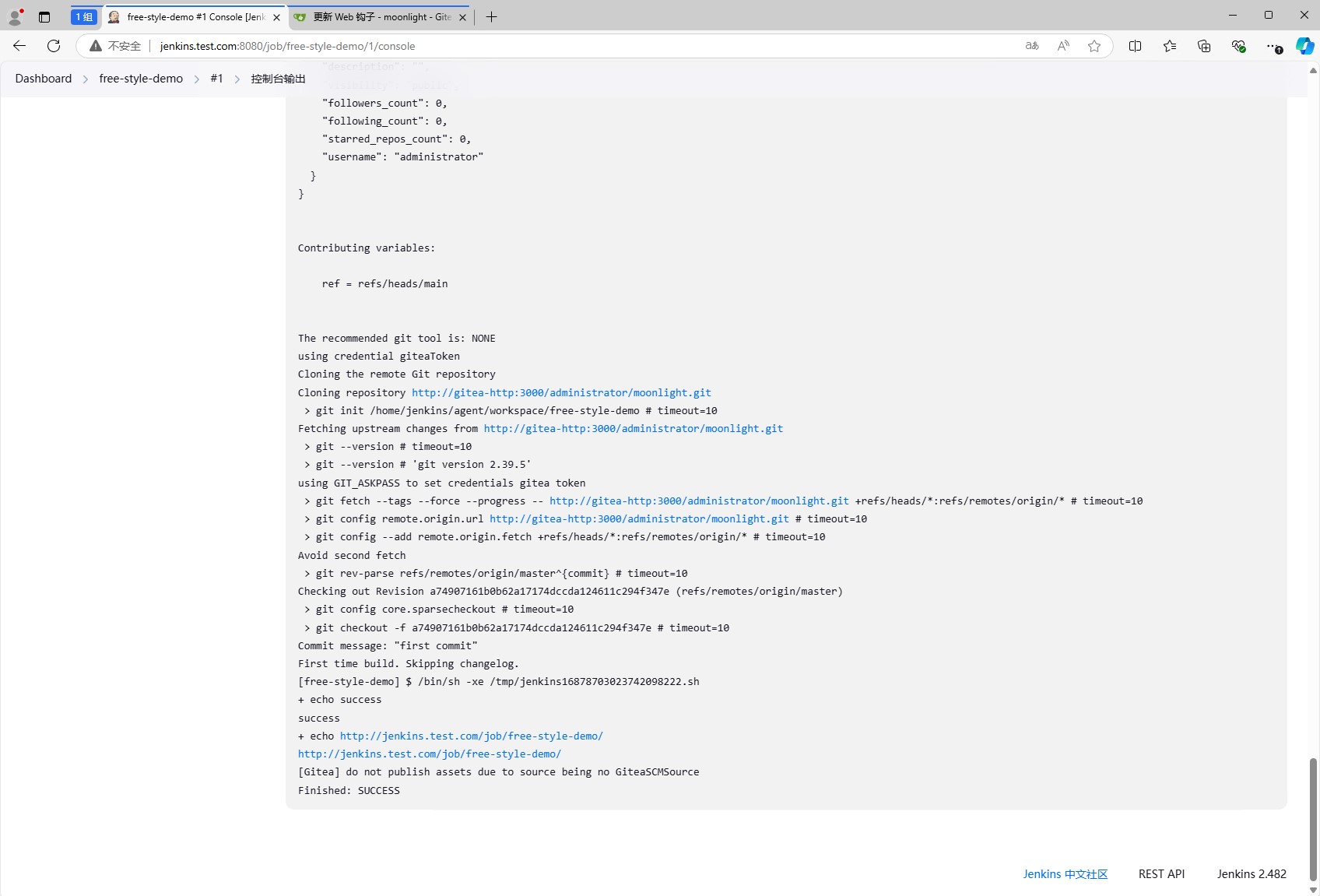
拉倒最后可以看到整体是先把git仓库拉取到本地,然后执行了我们配置的shell命令。

使用 helm 部署 gitea
Gitea 是一款轻量级的自托管Git服务,它提供了与Github、Gitlab、Gitee等类似的功能,可以在你自己的服务器上部署和运行,且占用资源较低。同时它提供了代码仓库管理、问题跟踪、团队协作、持续集成等功能,适用于小型团队和个人开发者,具有简单的界面和丰富的定制选项。 更重要的是它是开源的,允许你完全掌握自己的代码和数据。
他的文档地址是:https://docs.gitea.cn/,功能及安装方式都有详细的介绍。
安装 gitea
安装步骤参考官方文档
1 | # 添加gitea的helm仓库 |
编辑完成后,我们就可以安装gitea了。
1 | # 创建命名空间 |
安装完成后,我们就可以配置host通过浏览器访问gitea了。
此时我们可以点击右上角的注册按钮,注册一个账户,在gitea中id=0,也就是第一个注册的账户,是管理员账户,可以创建组织、创建仓库等操作。
注册完成后,我们就可以使用这个账户登录gitea了。
创建仓库
安装完成gitea我们就可以创建一个仓库了。这里创建一个django项目的仓库,仓库名称为moonlight。创建方法这里就不再赘述。
创建完成后的仓库如下图所示:
然后就可以创建django项目了,然后将远程仓库地址添加到django项目中,合并后提交到远程仓库。
1 | $ django-admin startproject moonlight |
通过gitea的网页,可以看到代码已经提交到了仓库中。
生成访问令牌
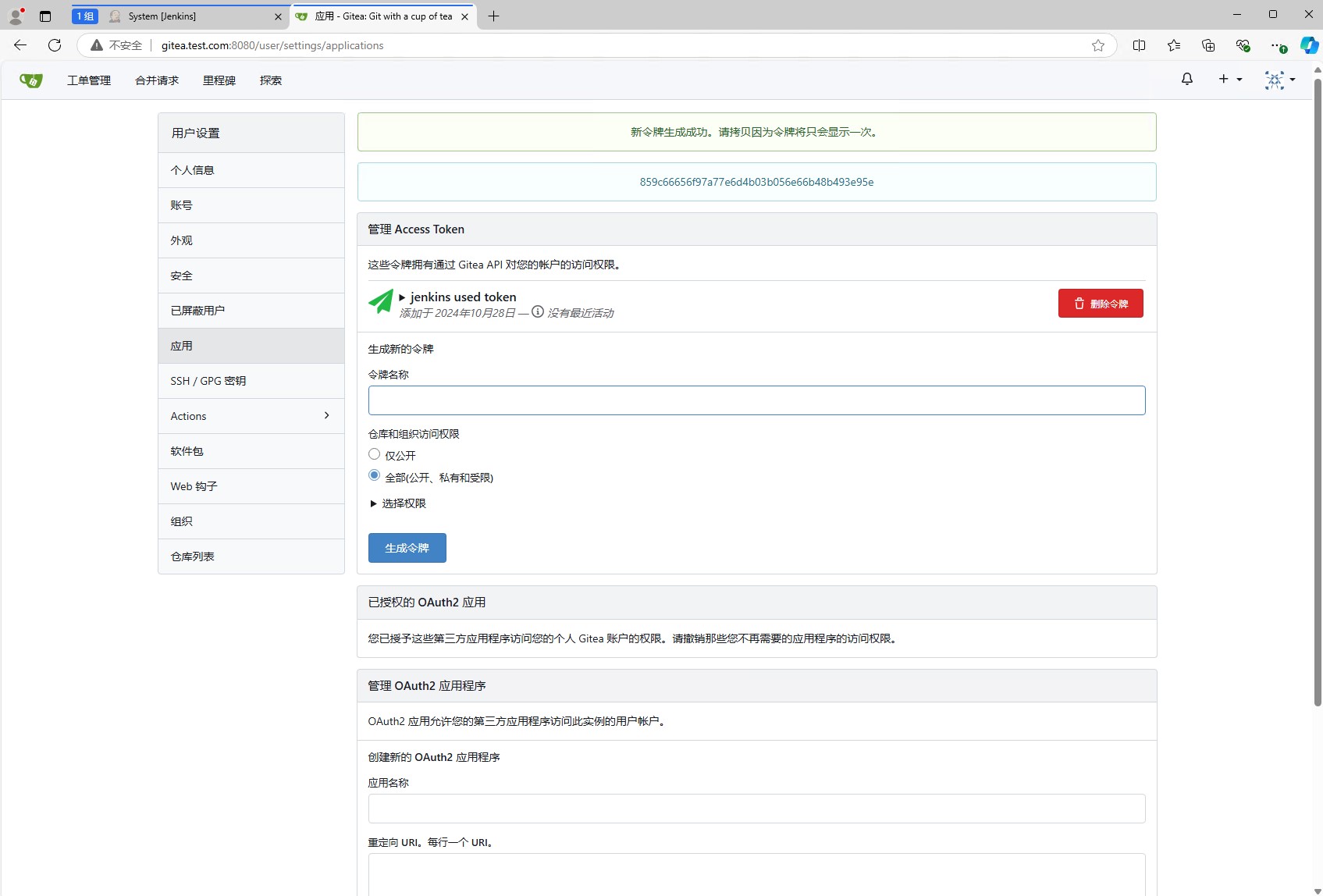
为了能让jenkins访问gitea,我们需要生成一个访问令牌。点击右上角的头像,然后选择设置,然后选择应用,然后点击生成新的访问令牌。
点击之后就会生成一个访问令牌,这个访问令牌是用来让jenkins访问gitea的。注意:这个访问令牌只会显示一次,所以一定要保存好。
配置jenkins
在gitea中,我们可以配置webhook,当代码提交到仓库后,会触发webhook,然后调用jenkins的接口,从而触发jenkins的流水线。
webhook触发的是jenkins的流水线,因此我们需要先创建一个流水线,然后再配置webhook。
配置访问令牌及gitea地址
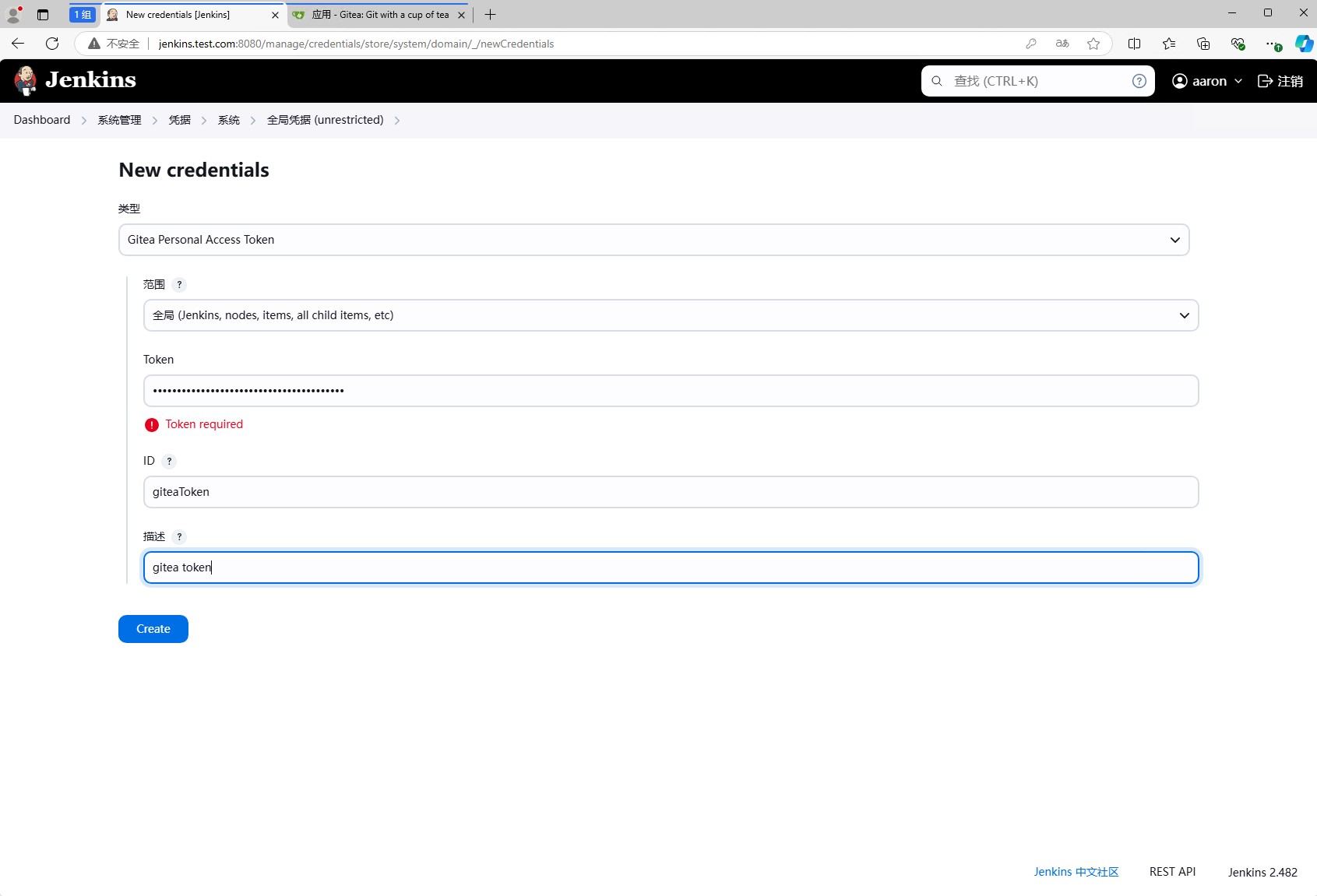
但是创建流水线之前,我们需要先配置jenkins访问gitea的访问令牌。点击系统管理,然后点击凭据,在凭据页面点击系统,然后点击全局凭据,然后点击添加凭据。
类型选择Gitea Personal Access Token,然后填写访问令牌,id保证内部唯一即可,然后点击添加。
然后打开系统管理,点击系统设置,然后找到Gitea,然后填写Gitea的地址,然后选择刚刚添加的凭据,然后点击保存。
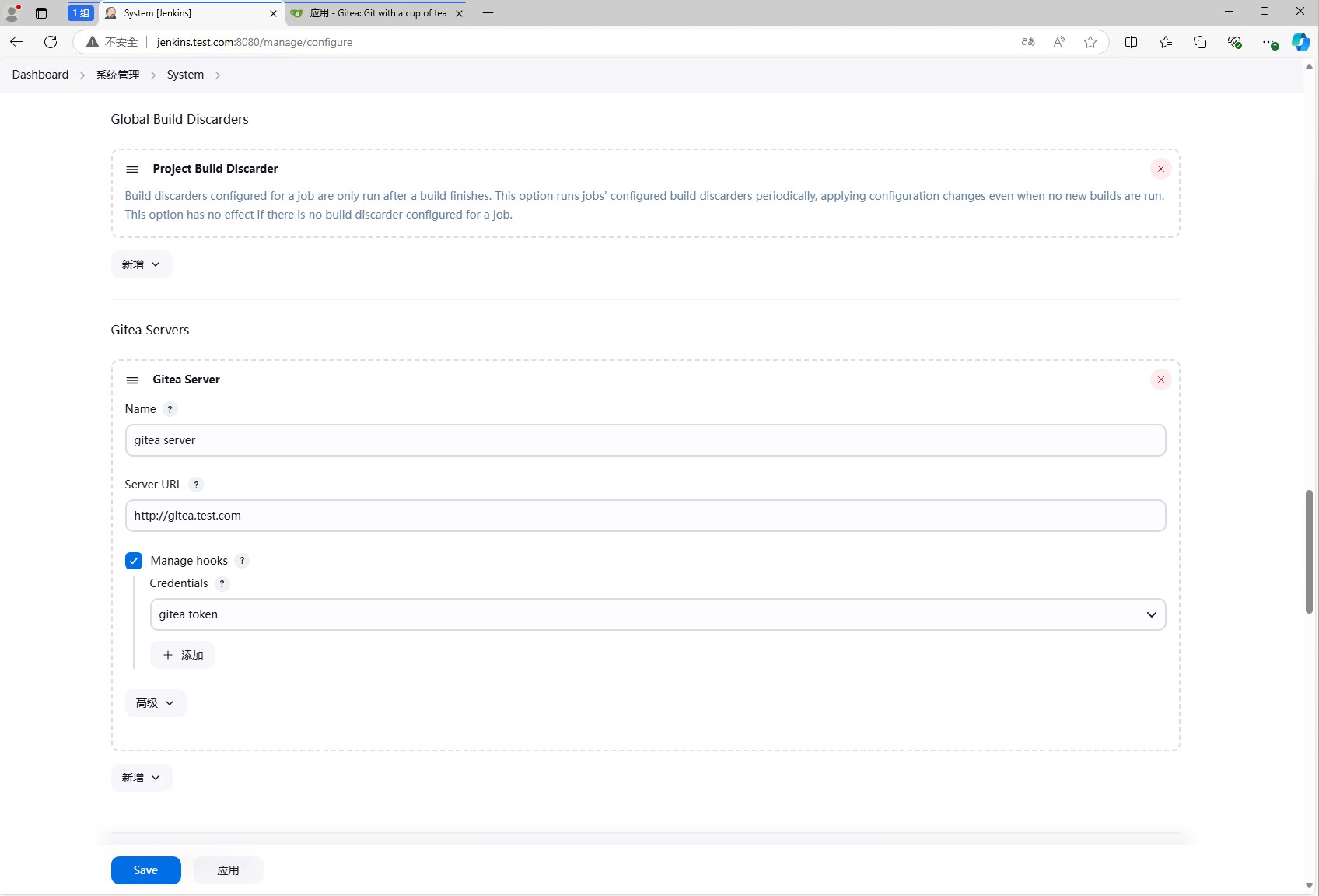
上面图里配置的Server URL是http://gitea-http:3000,这个是因为我们使用的是k8s集群,因此使用的是k8s集群内部的服务地址,gitea-http是gitea的service名称,3000是gitea的端口。
如果是外部地址,可以填写http://gitea.test.com,对gitea.test.com做解析即可。
填写完成后,jenkins会主动去gitea中获取信息,如果获取成功,会显示gitea版本,如果获取失败,会显示错误信息。因此需要我们最好等jenkins获取成功后再保存。
创建简单任务
这样前置的准备工作就完成了,接下来我们就可以创建一个最简单的任务了。
然后选择自由风格的软件项目,名字叫free-style-demo,然后点击确定。
然后我们就可以配置流水线了。首先我们先配置源码管理。选择git,然后填写仓库地址,这里填写的是gitea的仓库地址。
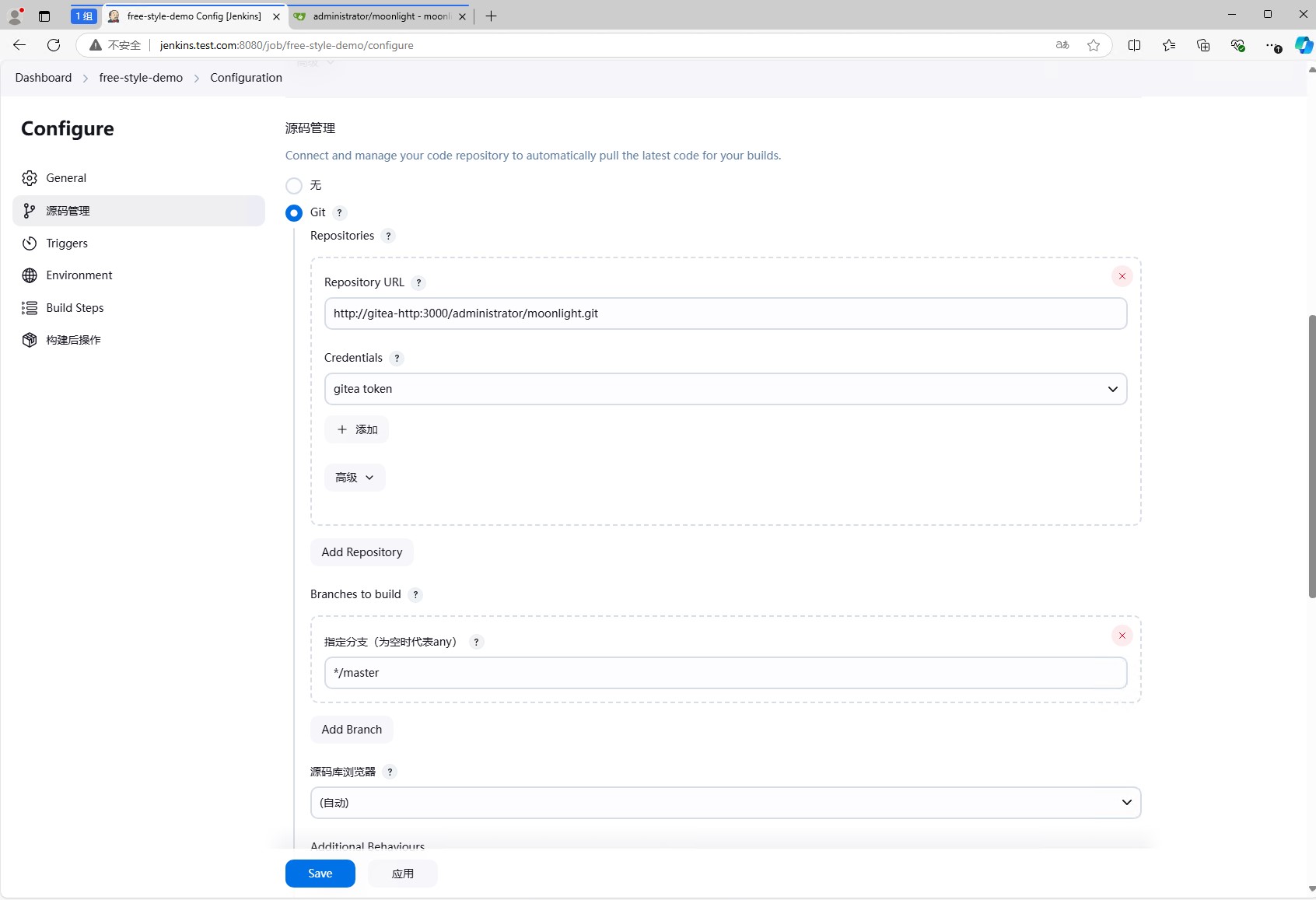
再往下走,构建触发器。这里我们选择”Generic Webhook Trigger”,这个是插件Generic Webhook Trigger提供的,可以通过webhook触发jenkins的流水线。
首先需要记下来http的请求url http://JENKINS_URL/generic-webhook-trigger/invoke, 这个是jenkins的webhook触发地址,一会儿需要填写到gitea的webhook中,这样当代码提交到gitea的时候,gitea会调用这个地址,从而触发jenkins的流水线。
同时配置提取git结构中的ref值。
一个大概的结构体如下:
1 | { |
此时,ref的值为refs/heads/main,这个值就是分支名,我们将他提取出来,然后就可以在接下来的任务中使用了。
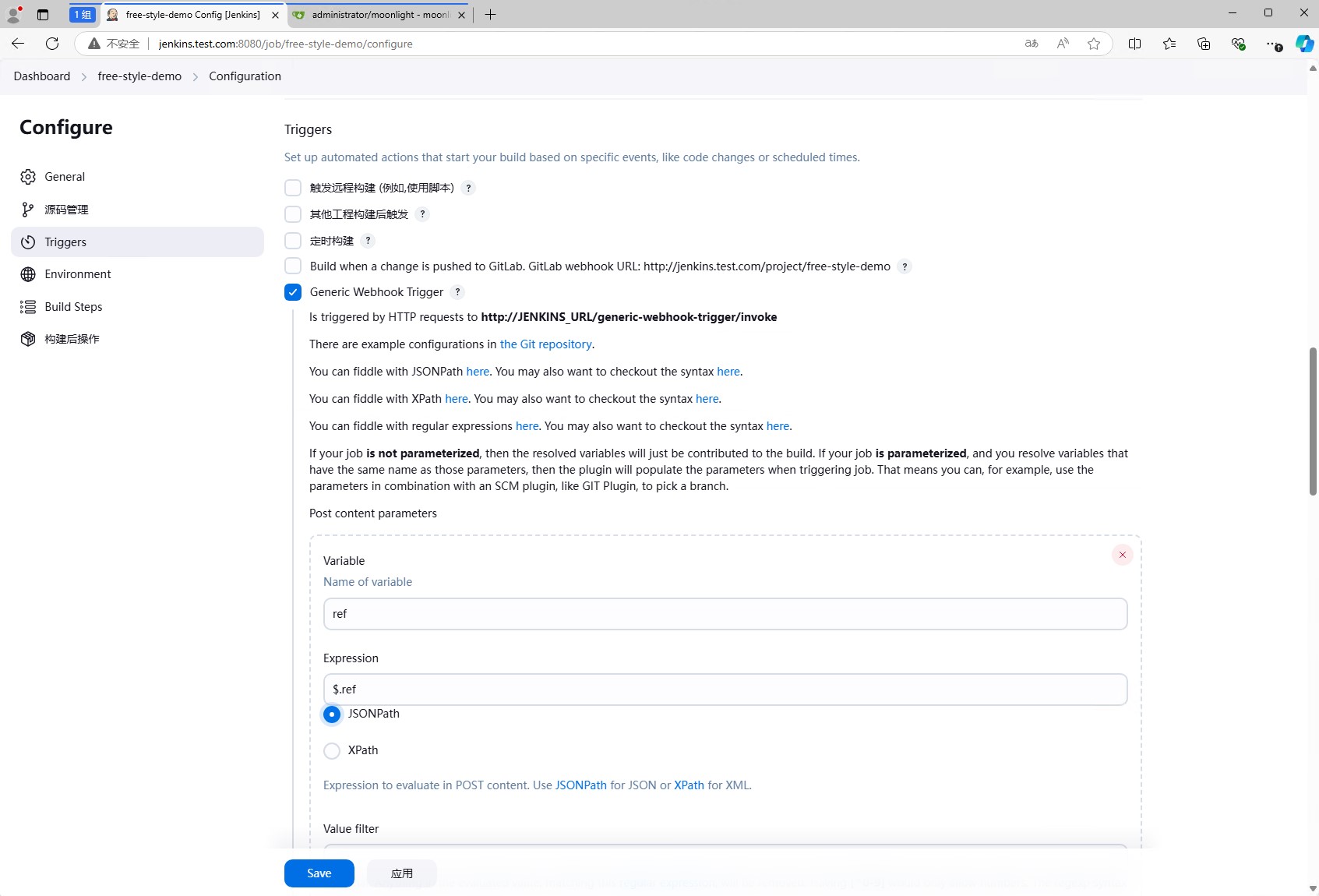
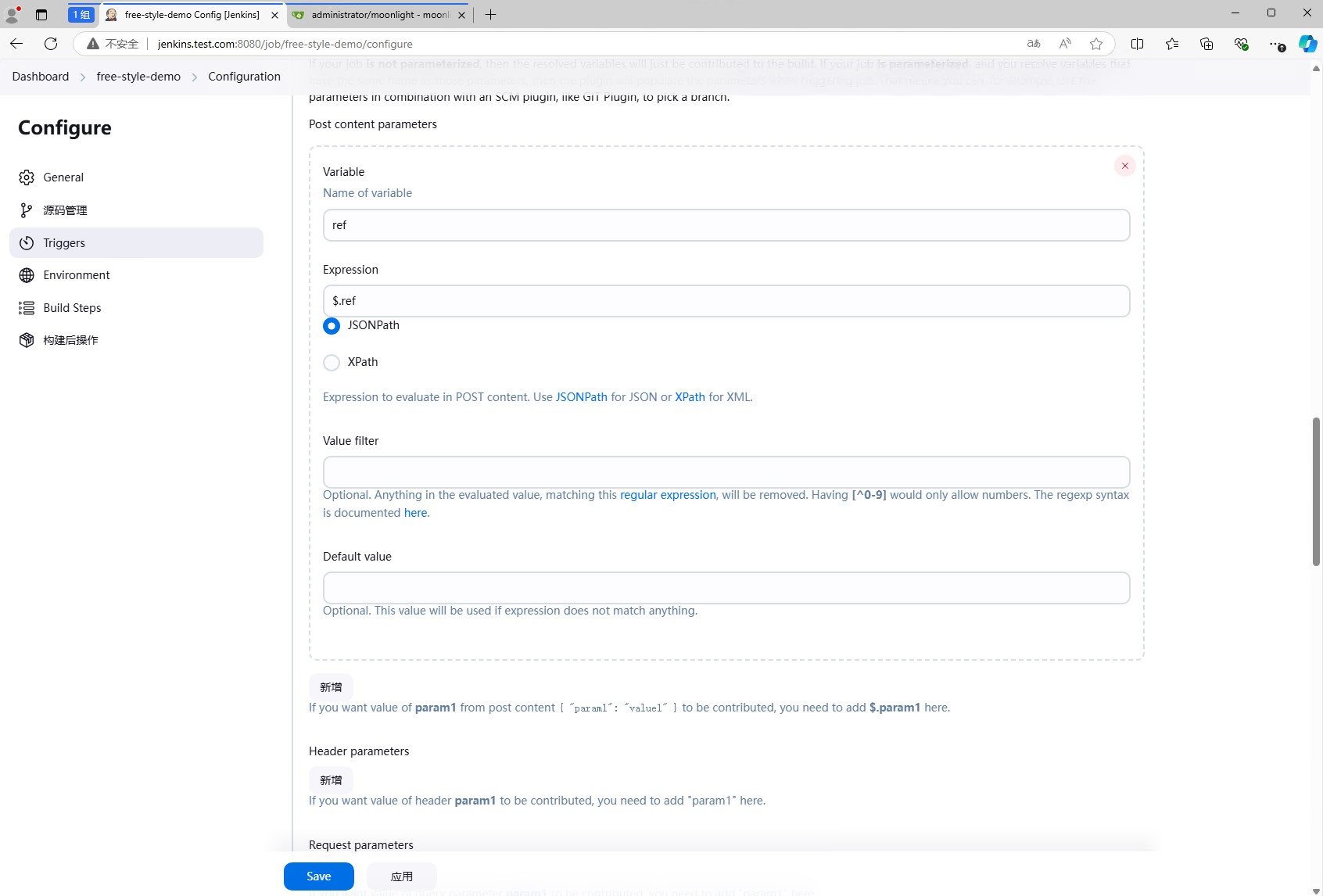
在trigger中,我们还需要配置Token,这个Token是用来验证webhook请求的,只有带有这个Token的请求才会触发jenkins的流水线,这个是选填的。
因为我们已经获取到了分支信息,所有这里嗯Cause中填写Triggered by ${ref},这样就可以看到触发的分支。
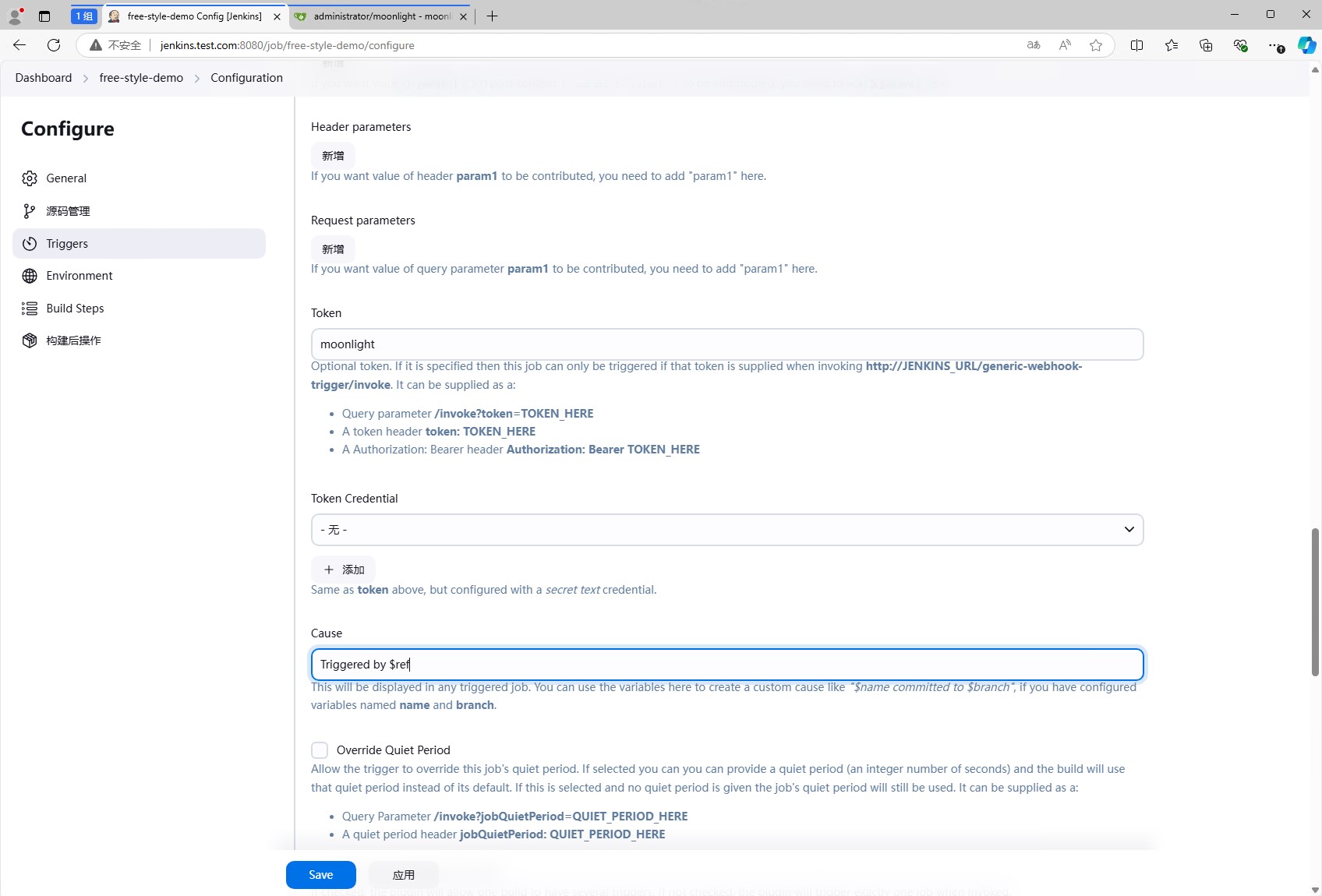
将Print post content勾选上,这样可以在jenkins的日志中看到post的内容,同时勾上Print contributed variables,这样可以在jenkins的日志中看到所有的变量。
如果只想对特定的分支进行触发,可以在Optional Filter中填写Text和Expression,这样只有符合条件的请求才会触发jenkins的流水线。
图中的含义是匹配Text(也就是$ref分支名),然后匹配Expression中的正则表达式(^refs/heads/develop$,也就是develop分支),如果匹配成功,才会触发jenkins的流水线。
这里只是举个例子,Optional Filter实验时是不填写的。
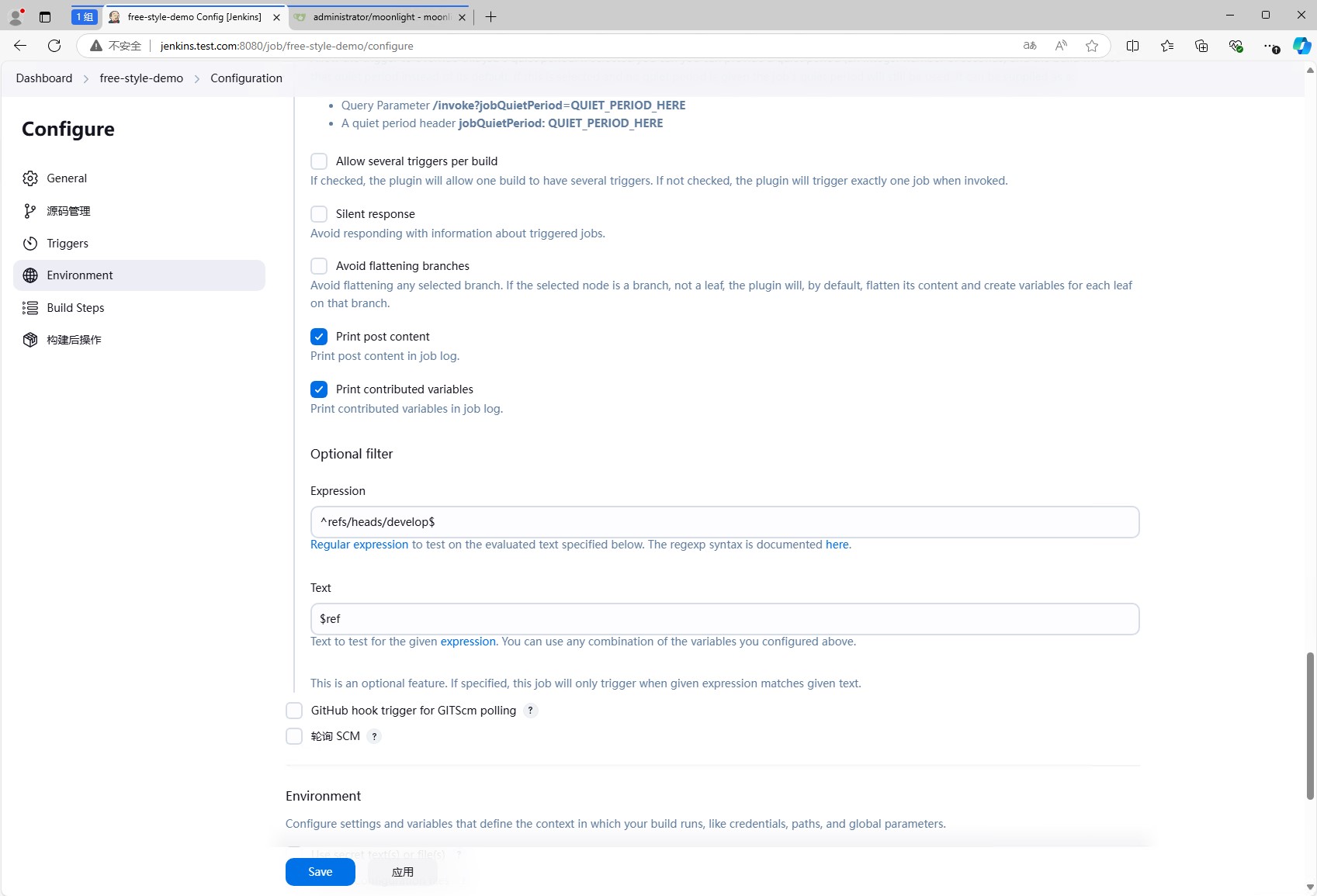
然后我们主要是测试,点击执行shell,然后填写一个简单点的echo success,点击”可用的环境变量”,可以看到jenkins提供了很多环境变量,这些环境变量可以在shell中使用,这里也打印了一个环境变量$JOB_URL。
然后点击保存即可。
配置webhook
jenkins的job配置完成后,我们就可以配置gitea的webhook了。进入代码仓库,点击设置。
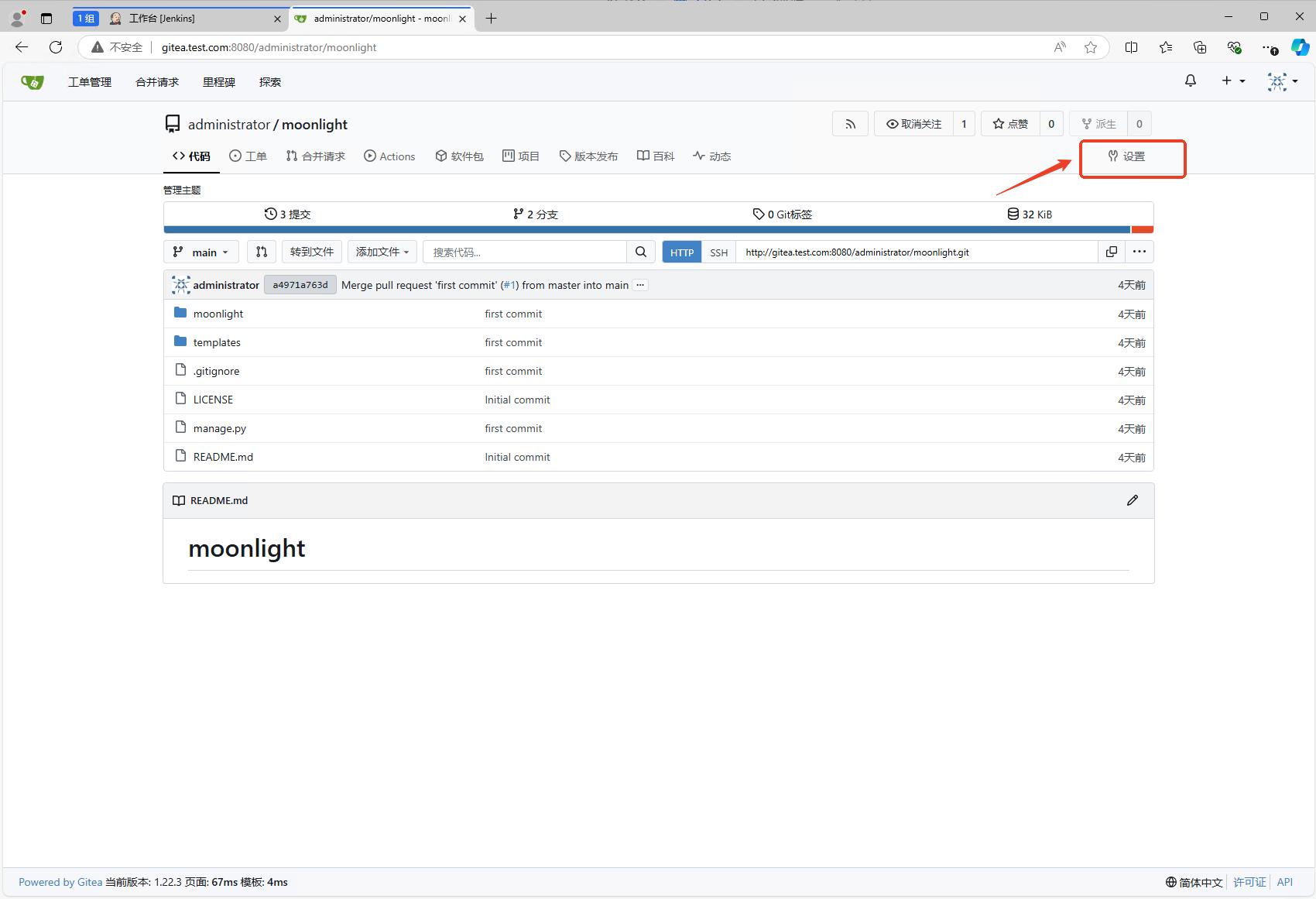
在设置中选择”Web Hooks”(Web钩子),然后点击”添加web钩子”按钮,选择”Gitea”选项。
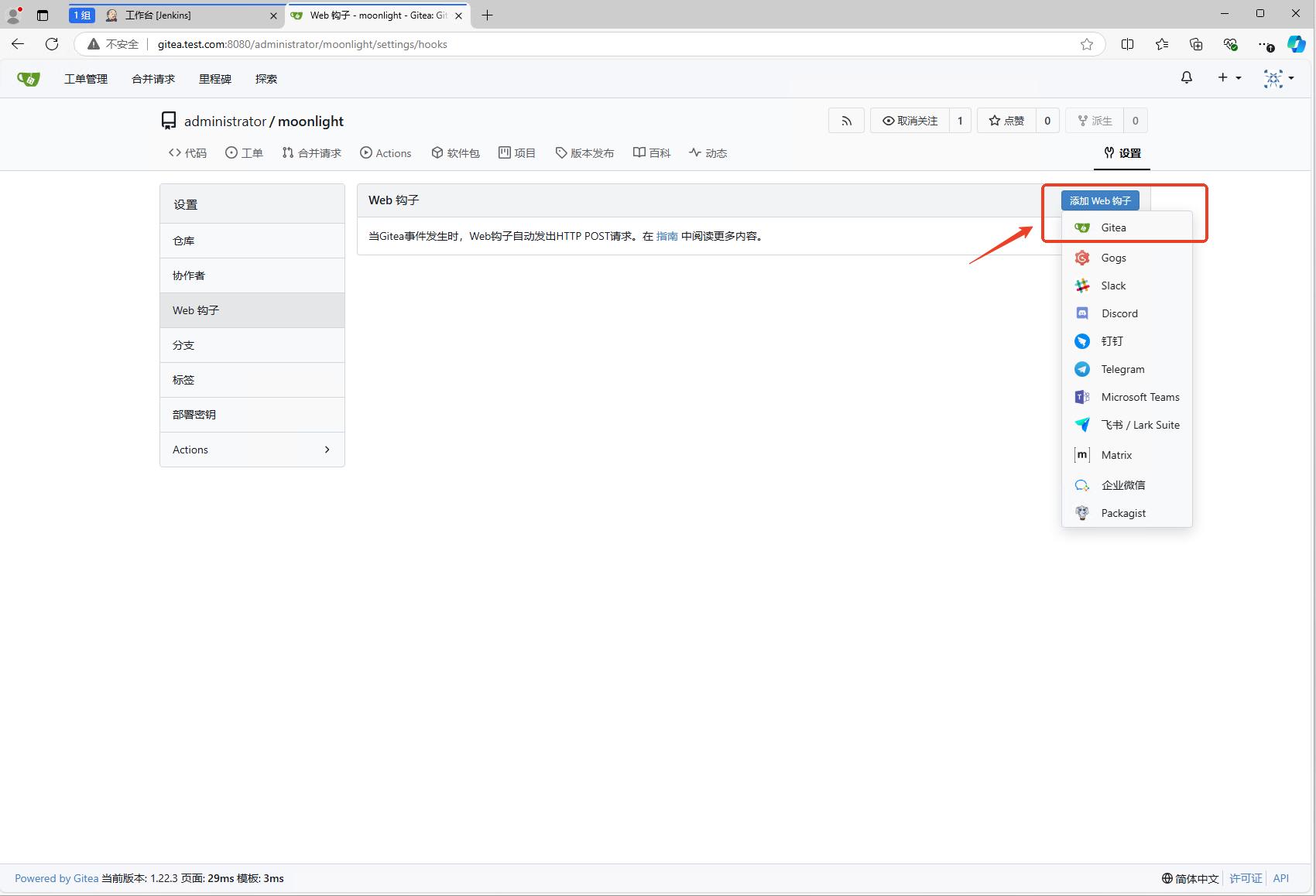
然后输入添加钩子所需要的信息。
- URL:这个是jenkins的webhook触发地址,也就是jenkins触发器中的URL,这里填写
http://jenkins:8080/generic-webhook-trigger/invoke?token=moonlight,注意token的填写,token已经在jenkins的触发器中填写了,这里需要保持一致。 - 触发条件:这个是指什么时候触发webhook,这里使用默认项。如果有特殊需求,可以选择
自定义事件,然后选择需要的事件。 - 激活:这个是指是否激活webhook,这里选择激活。添加完成后就能立即使用。
添加成功后能看到Web钩子列表中多了一个Web钩子。
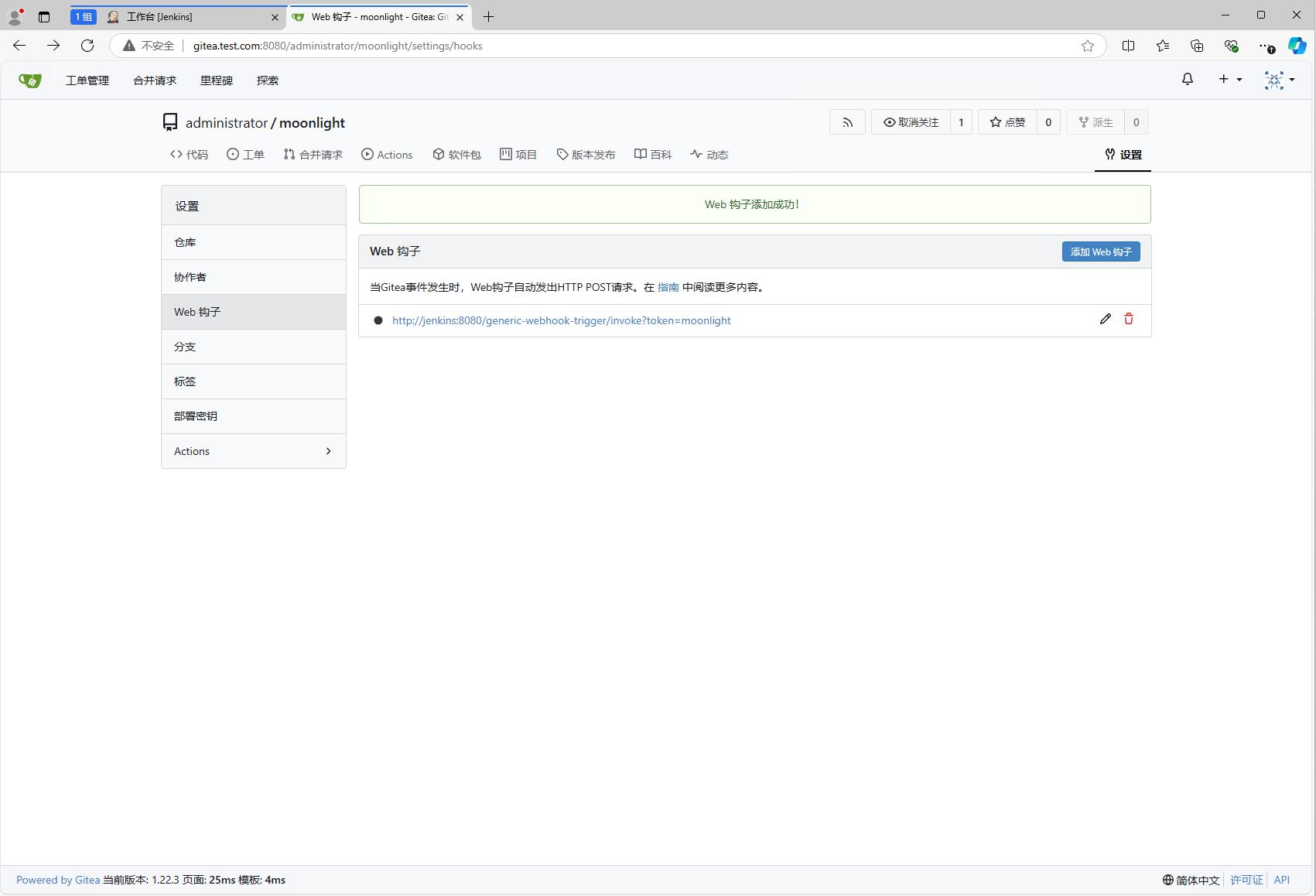
再次点击进去,就可以发现多出了一个测试按钮,此时还不能点击测试,如果点击测试,会报错,因为gitea对于webhook的地址有限制。
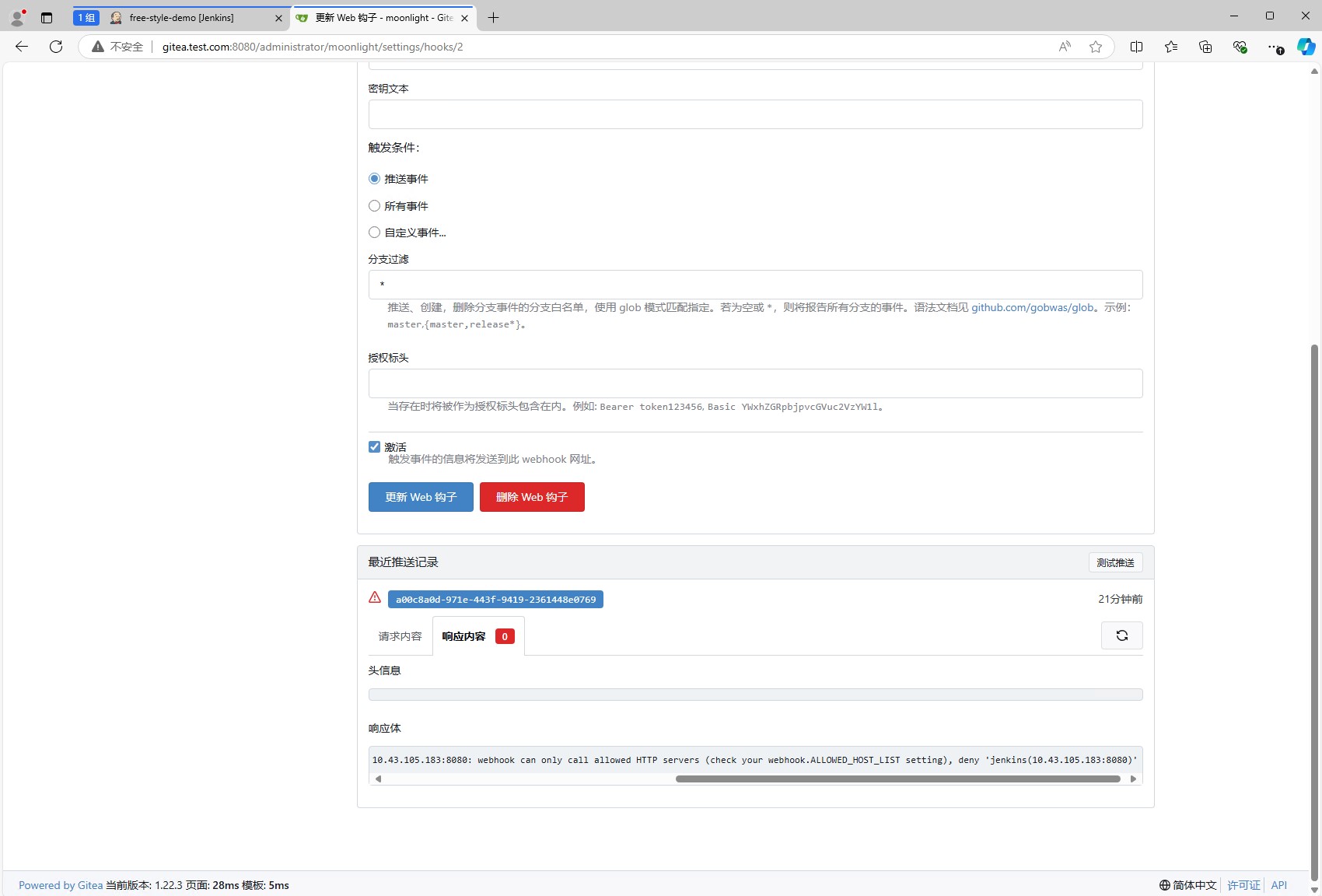
此时,我们进入gitea的容器中,修改/data/gitea/conf/app.ini文件。添加如下内容(如果有的话,修改即可):
1 | ...... |
然后重启gitea的容器,重新测试webhook,就可以看到测试成功了。
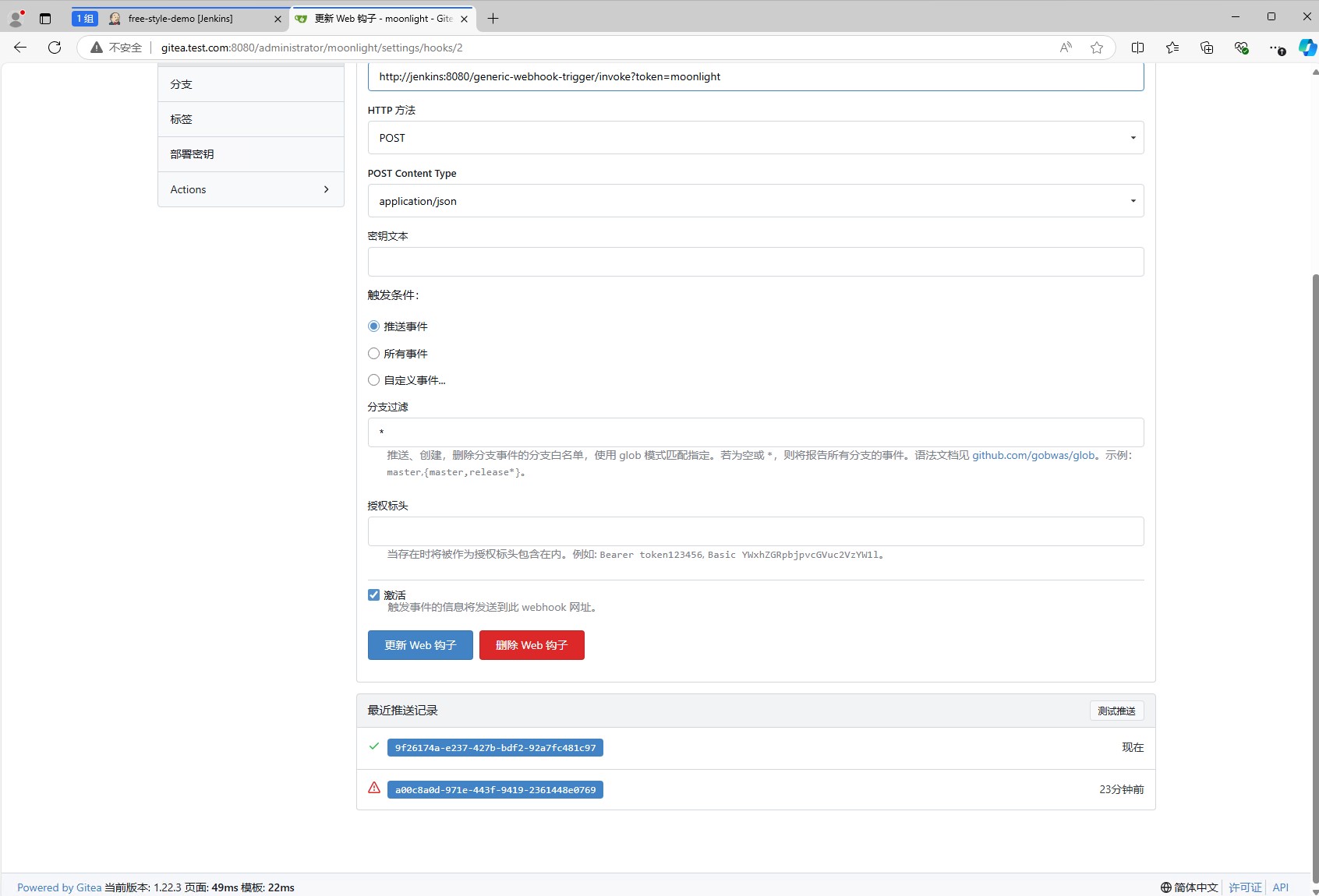
从jenkins的中,我们也可以看到任务已经触发了。
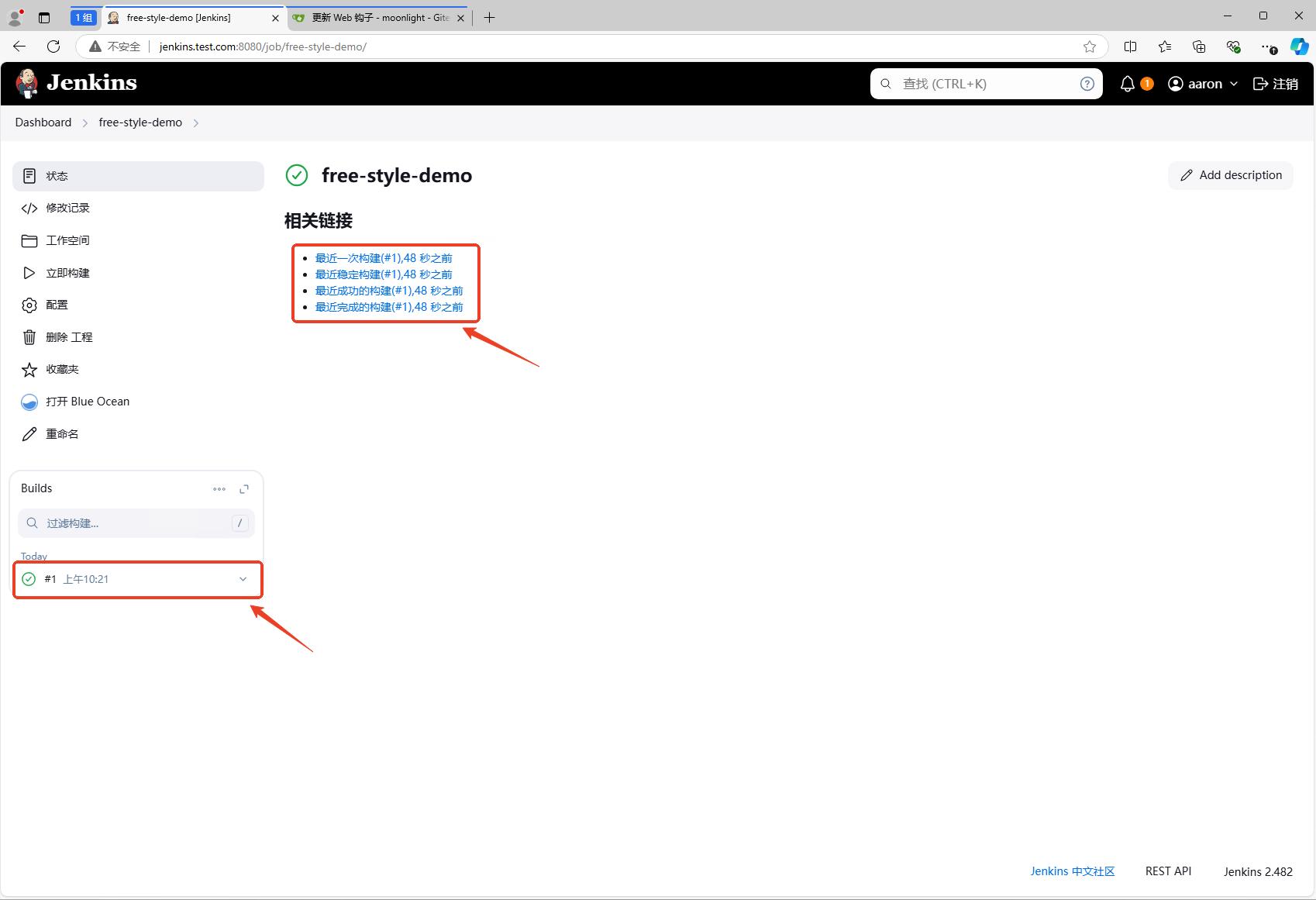
点击#1,进入任务详情页面,选择控制台输出,可以看到任务的执行过程。
开头就是我们配置的输出信息Triggered by refs/heads/main,然后是基本信息,然后是工作pod的配置。
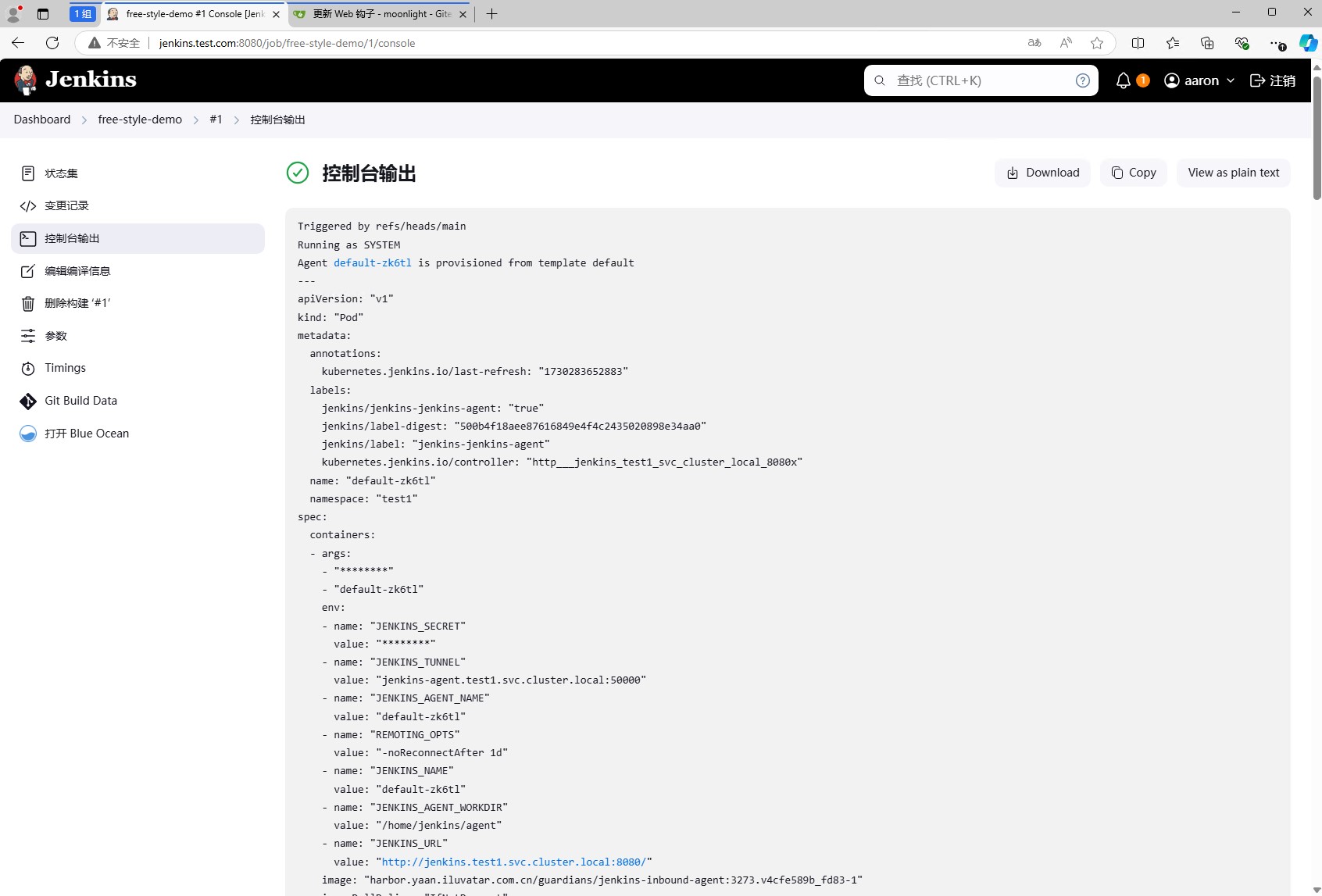
后面就是打印数据,变量信息,拉取代码过程以及执行shell的过程。
Jenkins 的 Master-Slave 模式
工作节点
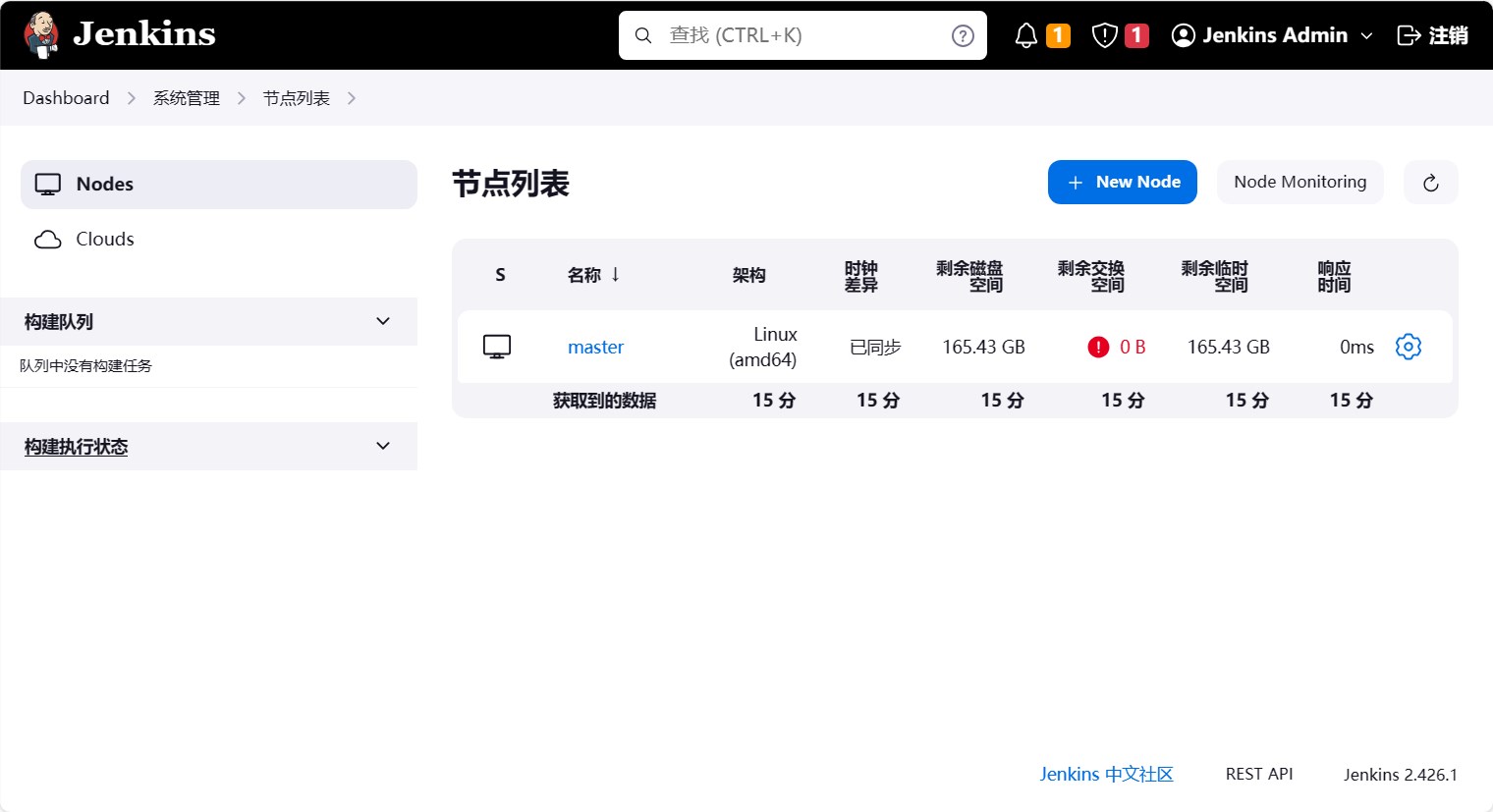
在 Jenkins 页面中,点击系统管理, 然后点击节点和云管理,可以看到 Jenkins 的工作节点列表。
可以看到在 Jenkins 中,只有一个节点,这个节点就是 Jenkins 的 Master 节点,也就是 Jenkins 的主节点。
刚才的任务都是在master节点执行的,为了验证我们可以登录到master节点上查看任务的执行情况。
1 | $ kubectl -n jenkins exec -it jenkins-0 -- /bin/bash |
默认jenkens的工作目录是/var/jenkins_home,一般任务的执行日志都在/var/jenkins_home/jobs/任务名称/builds/任务编号/log中,而工作目录是/var/jenkins_home/workspace/任务名称 。
但是不同的是,我们的jenkins是通过helm安装的,因此jenkins的默认会添加云配置,而有云配置的话jenkins就会通过建立pod来执行任务,pod中的工作目录默认是/home/jenkins/agent/workspace/任务名称,导致不会留下工作目录内容,当然这个可以配置,这个后面再说。
可以看到如果只是几个任务,直接在节点上执行是没有问题的,但是如果有多个任务都在master节点执行,对master节点的性能就会造成一定影响。因此我们可以添加多个工作节点,让工作节点来执行任务,这样就可以减轻master节点的压力。
当然,我们有集群配置,可以直接使用k8s集群中的节点作为jenkins的工作节点,这样就可以更好的利用资源。
Jenkins 的 Master-Slave 模式是指 Jenkins 的 Master 节点负责分发任务,Slave 节点负责执行任务。这样做的好处是可以将任务分发到不同的节点上执行,从而提高任务的执行效率。
添加工作节点
因为目前这个环境已经接入了k8s集群,因此我们使用k8s集群中的节点作为jenkins的工作节点。以下内容仅作为演示,最后还是会切换回k8s集群中的节点。
多个k8s管理和多个slave节点的添加方式大致相同,这里不再赘述,可以尝试添加基本就会了。
以下内容是旧的截图,但是方法是一样的,只是界面有所不同,可以参考。
点击新建节点,进入新建节点页面。
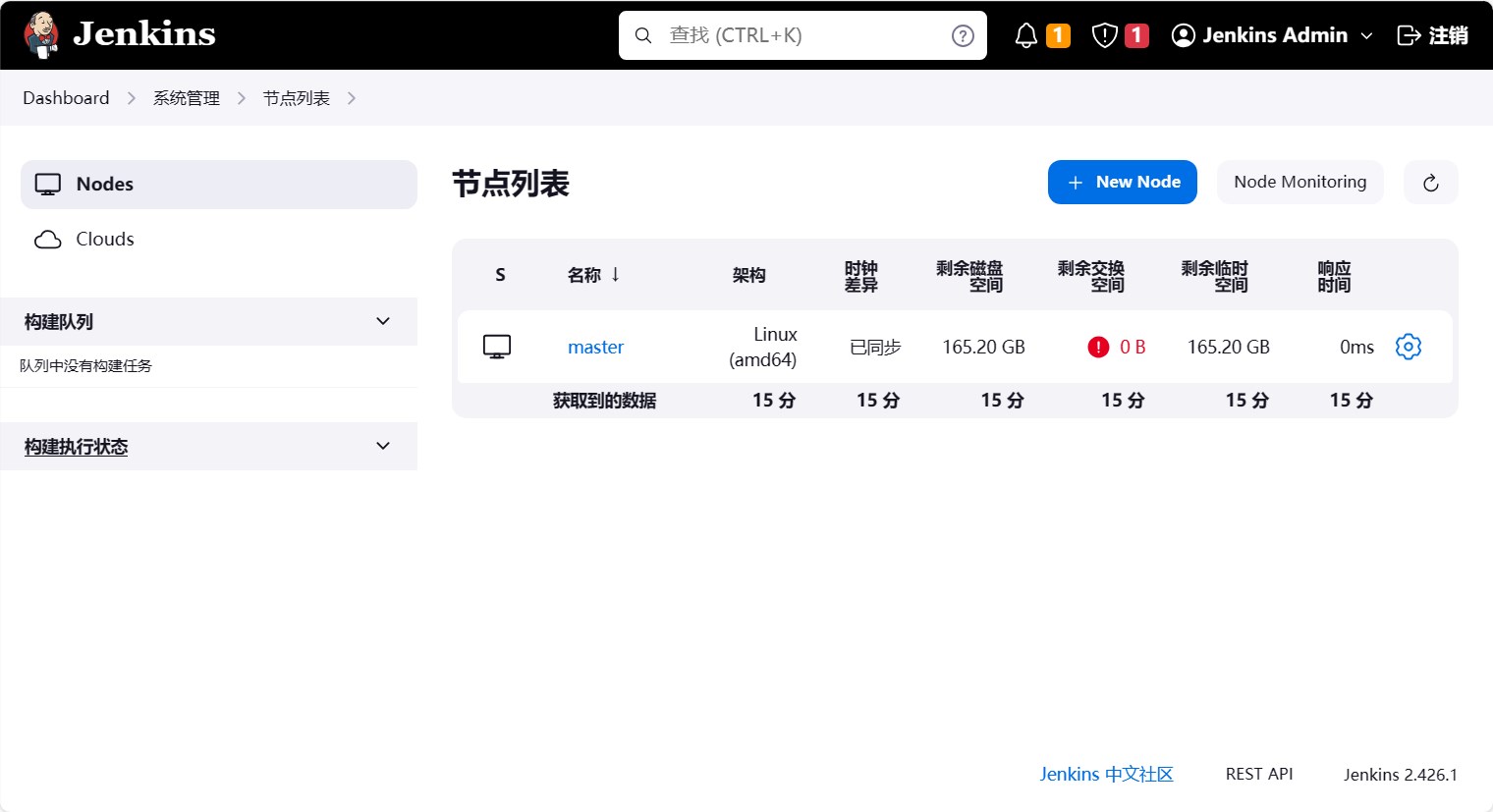
定义一个节点名称,这里我们定义为slave,然后选择固定节点,然后点击确定。
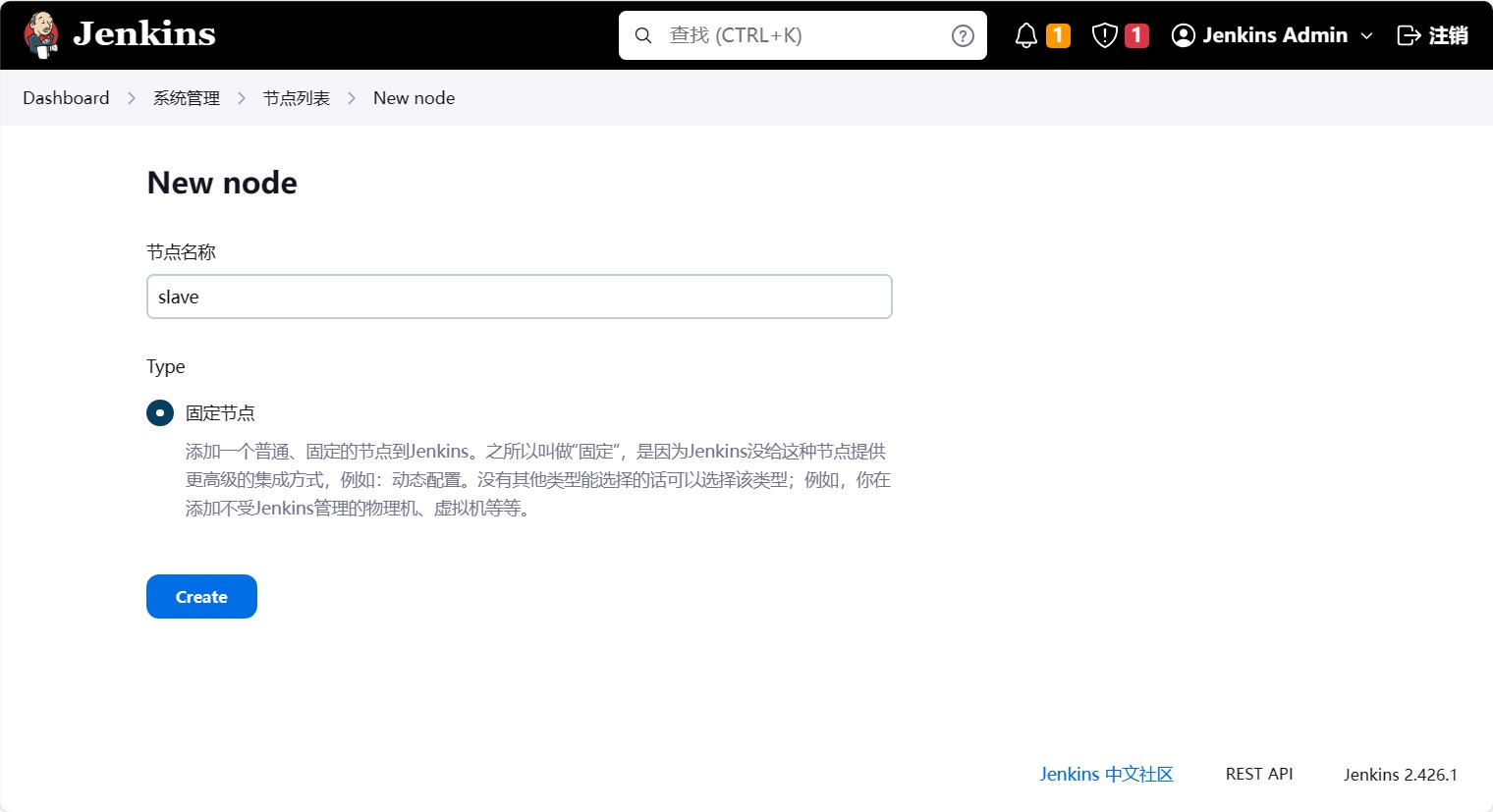
之后是填写更详细的信息
- Number of executors:这个是指这个节点可以同时执行多少个任务,这里我们填写5,也就是这个节点可以同时执行5个任务。
- 远程工作目录:这个是指这个节点的工作目录,这里我们填写
/home/jenkins,也就是这个节点的工作目录为/home/jenkins。 - 标签:这个是指这个节点的标签,这里我们填写
slave,也就是这个节点的标签为slave。之后我们可以在任务中指定任务执行在哪个节点上,就是通过标签来进行控制。 - 启动方法:这个是指这个节点的启动方式,也就是通过什么方式实现Master-Slave的通信。这里我们选择
通过Java Web启动代理,也就是通过Java Web启动代理的方式来实现Master-Slave的通信。- 自定义工作目录:这个是指这个节点的工作目录,这里我们填写
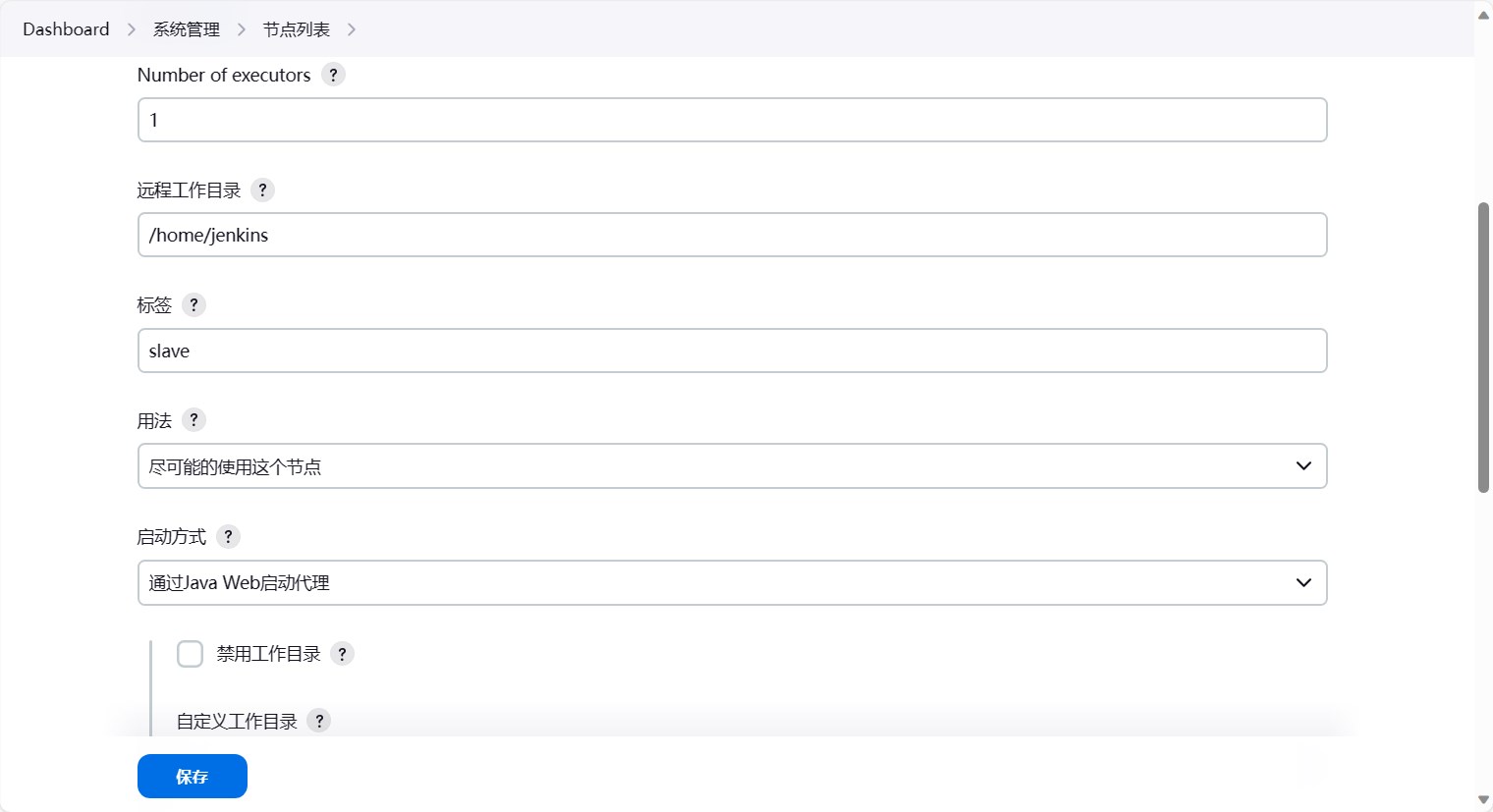
/home/jenkins,也就是和上面的远程工作目录一样。 - Tunnel连接位置:点开”高级”按钮就可以看到了。
- 这个是指这个节点连接到Master节点的时候,通过什么方式来连接。这里我们填入
10.99.223.156:50000。 - Jenkins 默认就会开放50000端口供Slave节点连接、通信。
- 因为我们使用的node节点,因此ClusterIP就可以在集群内部访问,因此填写Jenkins的ClusterIP即可。
- 这个是指这个节点连接到Master节点的时候,通过什么方式来连接。这里我们填入
- 自定义工作目录:这个是指这个节点的工作目录,这里我们填写
填写完成后,点击保存即可。
保存后,我们可以看到节点列表中多了一个节点。但是节点的状态是离线的,因为我们还没有启动这个节点。
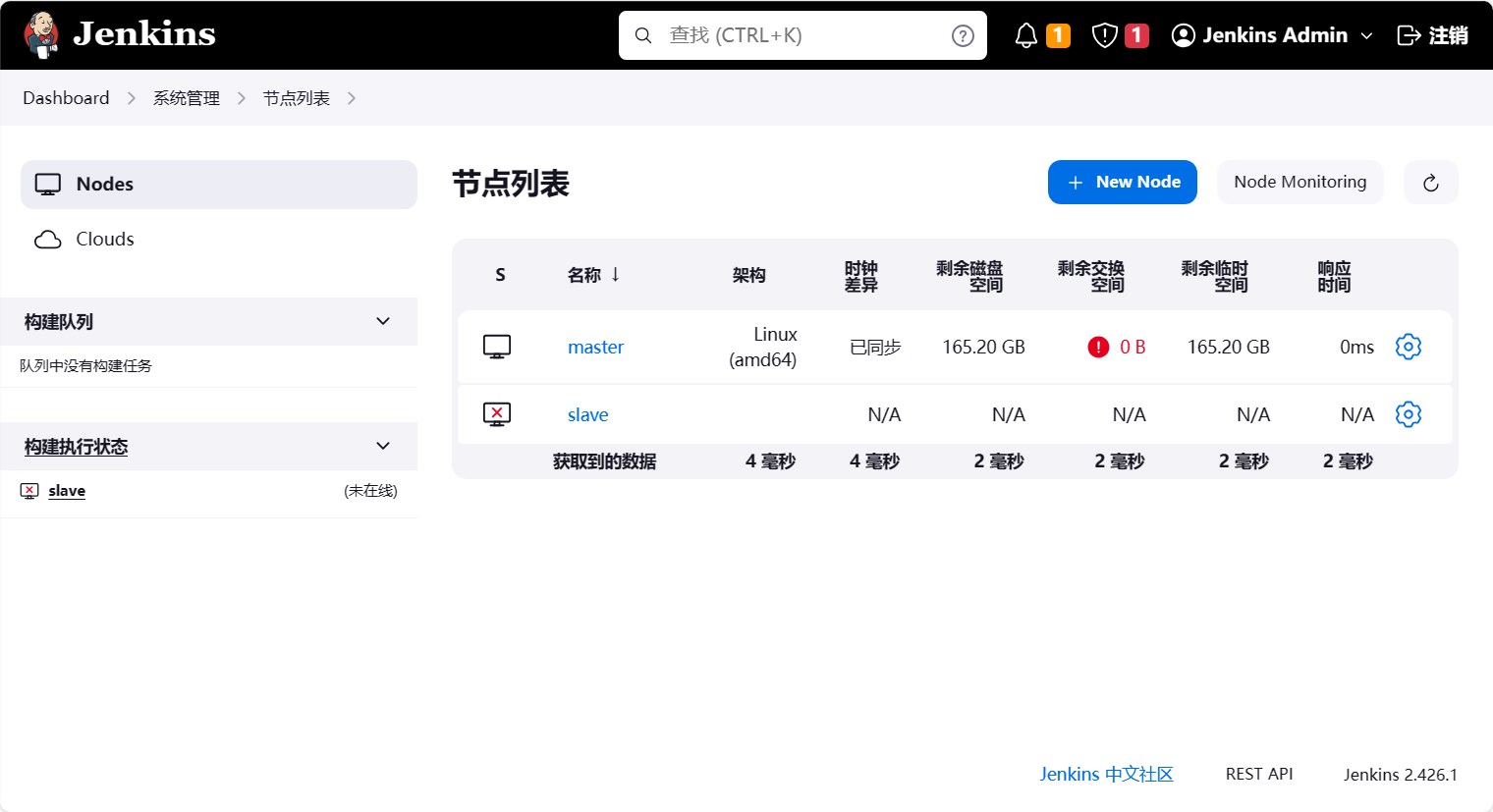
启动工作节点
点击节点列表中的节点名称,进入节点详情页面。可以看到连接节点的命令,这个命令就是启动节点的命令。
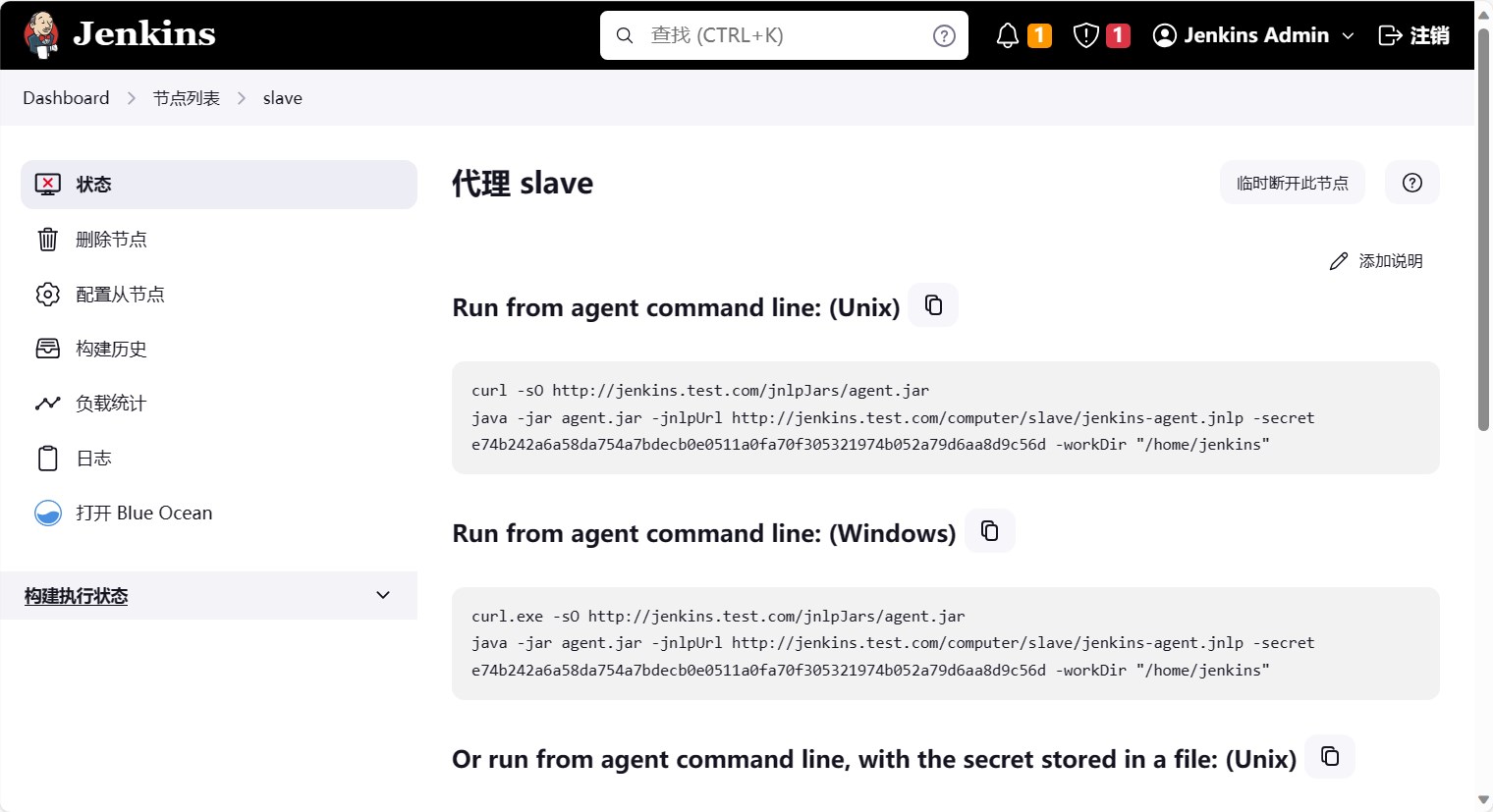
我们在node节点上执行这个命令,启动节点。
1 | # 首先配置hosts确保能够解析jenkins的地址 |
此时我们再回到jenkins的节点列表中,可以看到节点的状态已经变成在线了。
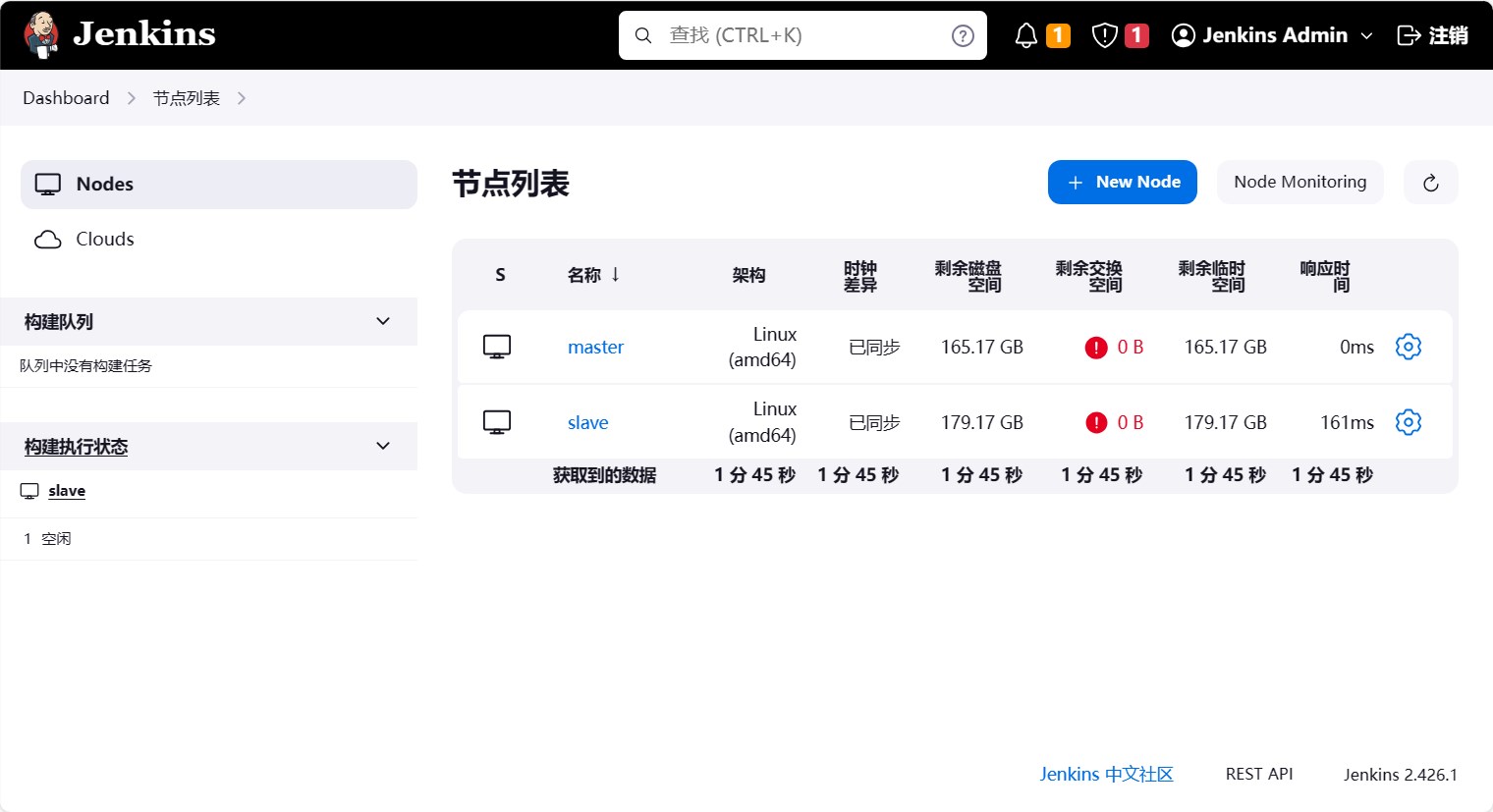
测试工作节点
此时我们进入到free-style-demo任务中,然后点击配置,在Gogs Webhook中,选择限制项目的运行节点,然后填入slave,也就是这个任务只能在slave节点上执行。
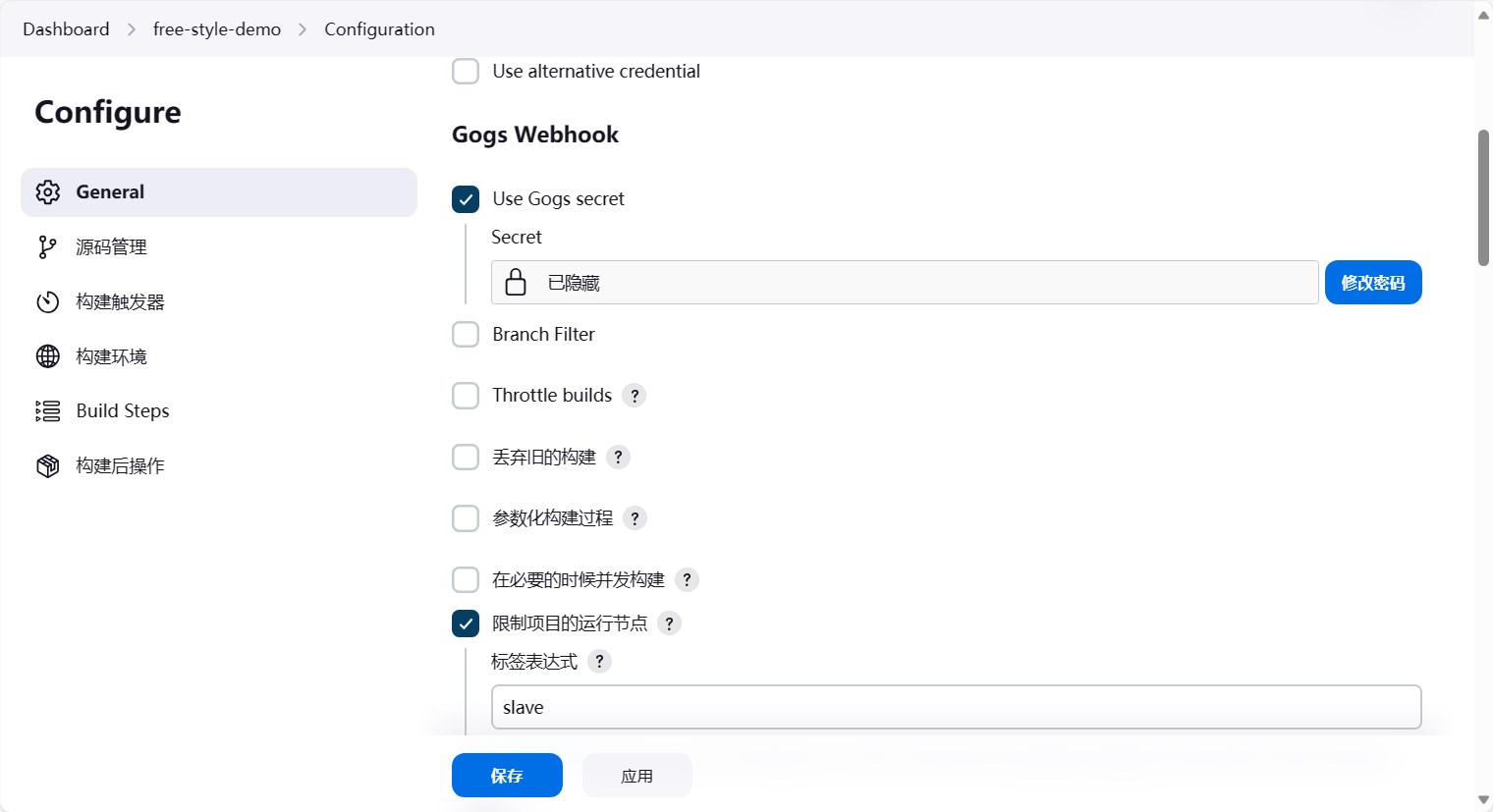
然后点击保存,保存成功后,我们再次提交代码,触发jenkins的流水线。
1 | $ echo "test again" > test.md |
然后我们可以看到jenkins的流水线已经触发了。
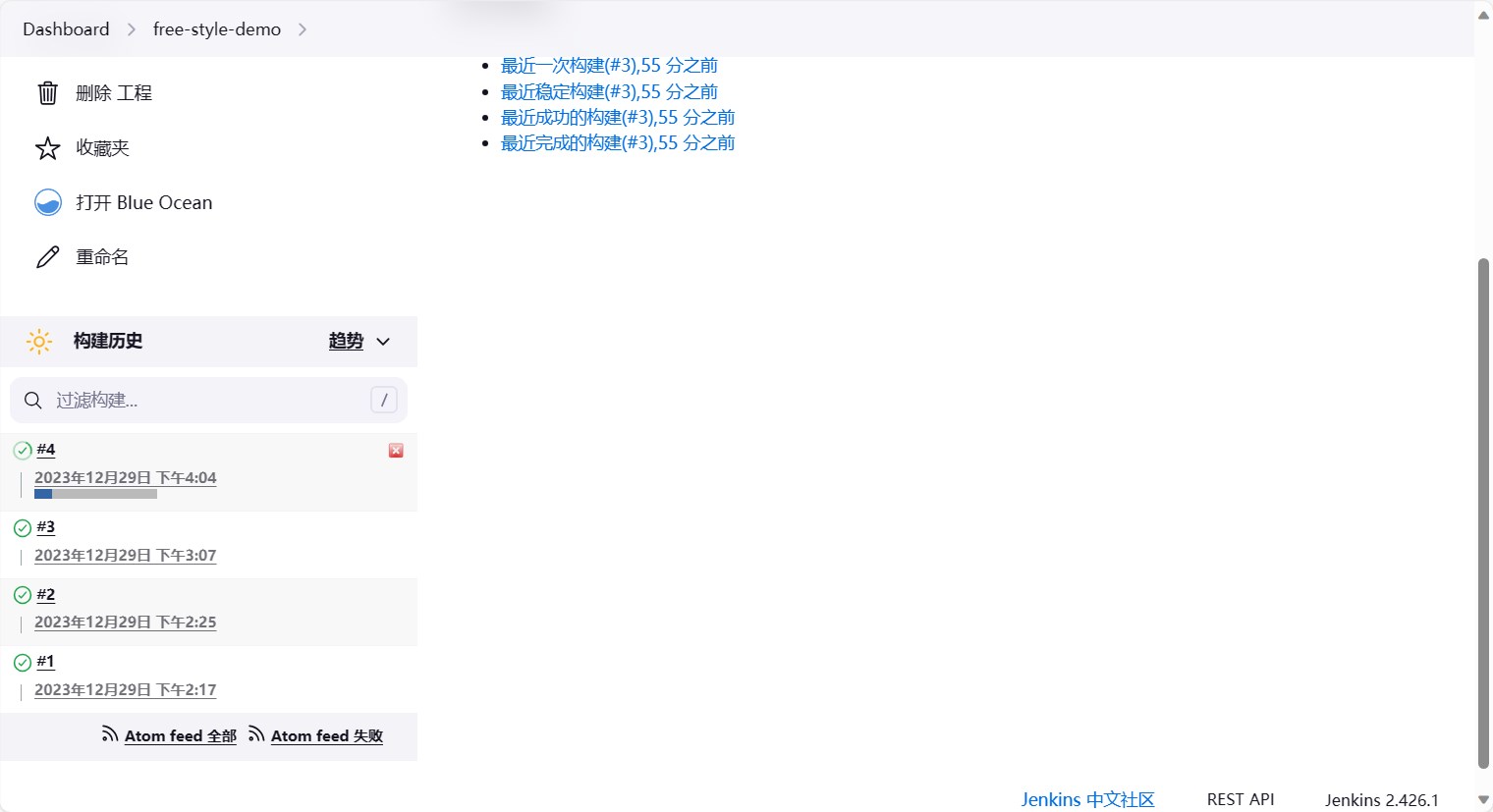
等待build完成后,点击序号,查看build的日志。可以看到build的时候,是在slave节点上执行的。
登录到slave节点上,可以看到slave节点上已经有了我们的代码。
1 | ls /home/jenkins/workspace/free-style-demo |
Jenkins定制化容器
由于每次新部署Jenkins环境,都需要安装很多必要的插件,因此考虑把插件提前做到镜像中,这样再部署的时候就不需要再在线安装插件了。
首先得知道插件都有哪些,我们可以访问Jenkins的url,然后生成插件列表文件。
1 | # admin:admin@jenkins.test.com 需要替换成Jenkins的用户名、密码及访问地址 |
插件列表文件大致格式如下,这个文件中包含了我们需要安装的插件。
1 | ace-editor:1.1 |
下面是一个定制化的Jenkins镜像的Dockerfile文件,主要为了构建一个包含插件的镜像。
1 | FROM jenkinsci/blueocean:1.25.2 |
执行构建,定制jenkins容器
1 | $ docker build . -t harbor.test.com/jenkins:v1 -f Dockerfile |
至此,我们已经有了定制化的Jenkins镜像,接下来我们就可以使用这个镜像来部署Jenkins了。
1 | # 编辑现有jenkins的statefulset,将镜像替换成我们定制化的镜像,保存即可 |
Jenkins 流水线
之前我们已经创建了一个简单的任务,这个任务是通过webhook触发的,这个任务是一个自由风格的任务,也就是我们可以在任务中执行任何命令。
但是这种一步一步选择的方式十分麻烦,而且不利于维护与移植,因此我们可以使用流水线的方式来执行任务。
在 Jenkins 中,流水线就是将任务的执行过程写成一个脚本,然后通过这个脚本来执行任务。
比如下面就是一段流水线脚本。
1 | pipeline { |
pipeline:定义流水线,固定写法,这个是必须的。agent any:指定流水线的执行环境,这里是任意节点,也就是可以在任意节点上执行。如果想要指定节点,可以写成agent { label 'slave' },也就是指定在slave节点上执行。主要有以下几种:any:可以在任意可用的 agent上执行pipelinenone:pipeline将不分配全局agent,每个 stage分配自己的agentlabel:指定运行节点agent的 Labelnode:自定义运行节点配置,- 指定 label
- 指定 customWorkspace
docker:使用给定的容器执行流水线。1
2
3
4
5
6
7agent {
docker {
image 'node:7-alpine'
args '-v /tmp:/tmp'
label 'my-defined-label'
}
}dockerfile:使用源码库中包含的Dockerfile构建的容器来执行Pipeline。kubernetes:在kubernetes集群执行Pipeline
environment:定义流水线的环境变量,这里定义了一个BUILD_VERSION的环境变量,只在流水线中有效,一个构建周期内有效。stages:定义流水线的阶段,这里定义了三个阶段,分别是Build、Test、Deploy,他们是按顺序执行的。agent的参数也可以用在这里。steps:定义阶段的执行步骤,这里定义了每个阶段的执行步骤,这里只是简单的打印了一句话,可以是一个或多个steps,顺序执行。post:定义流水线的后置条件,支持 post-condition 块中的其中之一:always,changed,failure,success,unstable, 和aborted。always, 无论流水线或阶段的完成状态如何,都允许在post部分运行该步骤changed, 当前流水线或阶段的完成状态与它之前的运行不同时,才允许在post部分运行该步骤failure, 当前流水线或阶段的完成状态为”failure”,才允许在post部分运行该步骤, 通常web UI是红色success, 当前流水线或阶段的完成状态为”success”,才允许在post部分运行该步骤, 通常web UI是蓝色或绿色unstable, 当前流水线或阶段的完成状态为”unstable”,才允许在post部分运行该步骤, 通常由于测试失败,代码违规等造成。通常web UI是黄色aborted, 只有当前流水线或阶段的完成状态为”aborted”,才允许在post部分运行该步骤, 通常由于流水线被手动的aborted。通常web UI是灰色
options:定义流水线的选项,这里没有列出,可以定义很多选项,比如超时时间等。timeout:定义流水线的超时时间,如果超过这个时间,流水线就会被终止。如options { timeout(time: 1, unit: 'HOURS') },这个是定义流水线的超时时间为1小时。retry:定义流水线的重试次数,如果流水线执行失败,会重试这个次数。如options { retry(3) },这个是定义流水线的重试次数为3次。buildDiscarder:定义流水线的构建丢弃策略,这个是定义流水线的构建丢弃策略,比如保留构建的天数等。比如options { buildDiscarder(logRotator(numToKeepStr: '10', artifactNumToKeepStr: '1')) },这个是定义流水线的构建丢弃策略,保留构建的天数为10天,保留构建的数量为1个。disableConcurrentBuilds:定义流水线的不能同时执行,防止同时访问共享资源。如options { disableConcurrentBuilds() },这个是定义流水线的不能同时执行。
创建流水线任务
点击新建任务,进入新建任务页面。
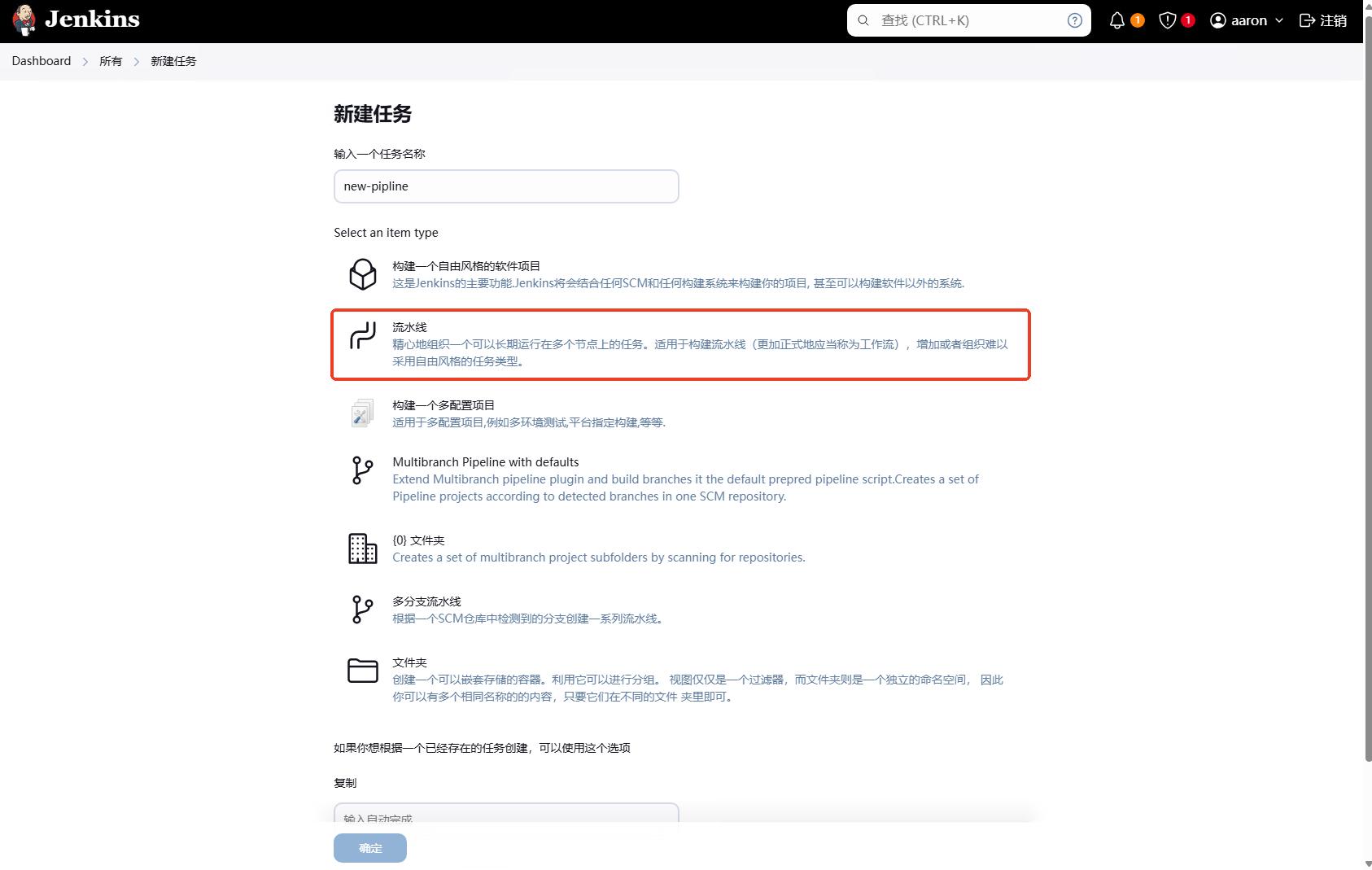
然后选择流水线,然后填写任务名称,这里我们填写new-pipeline,然后点击确定。
然后我们就可以配置流水线了,基本配置和之前的任务是一样的,下面的四张图只是再展示一遍。
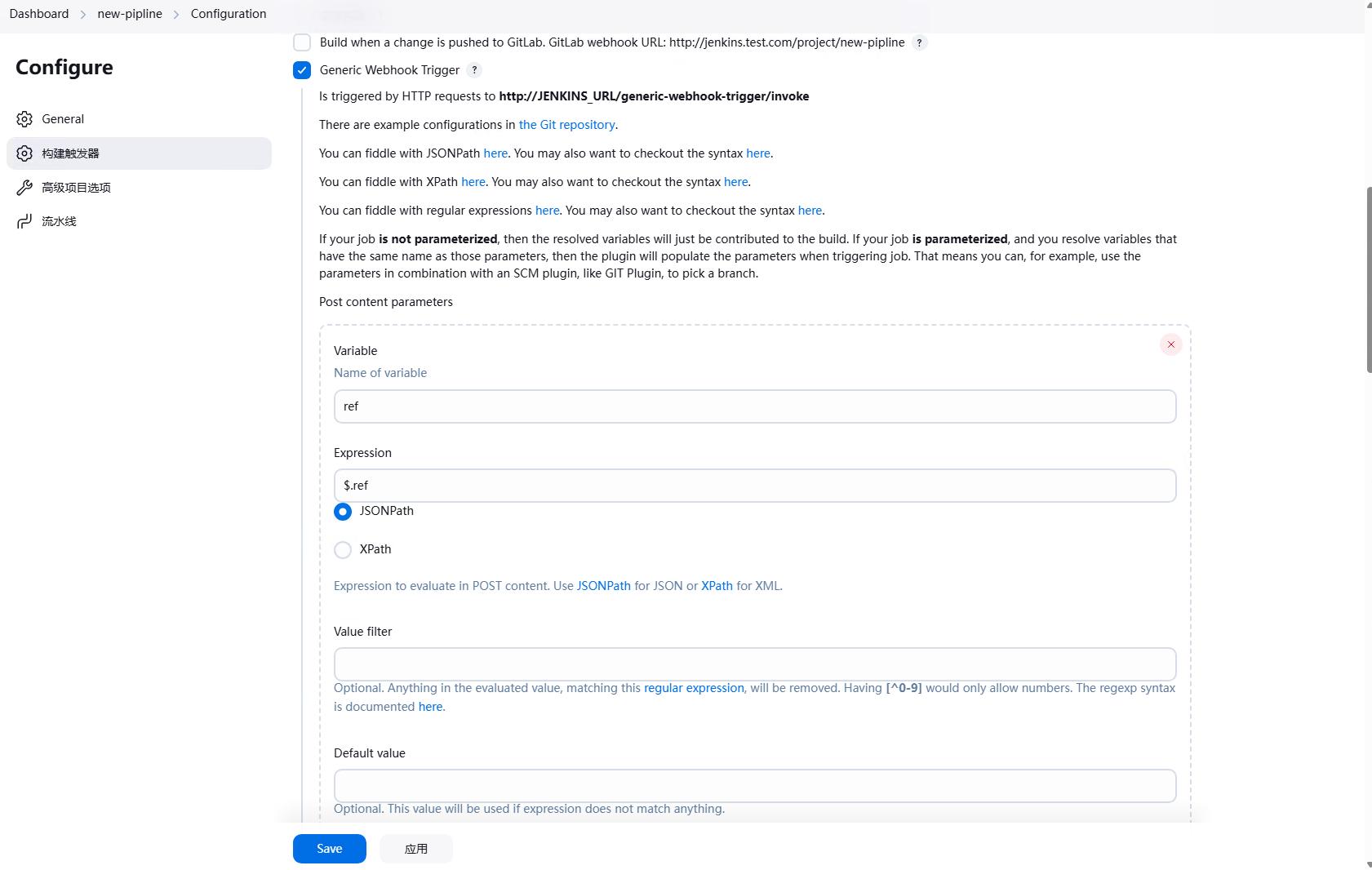
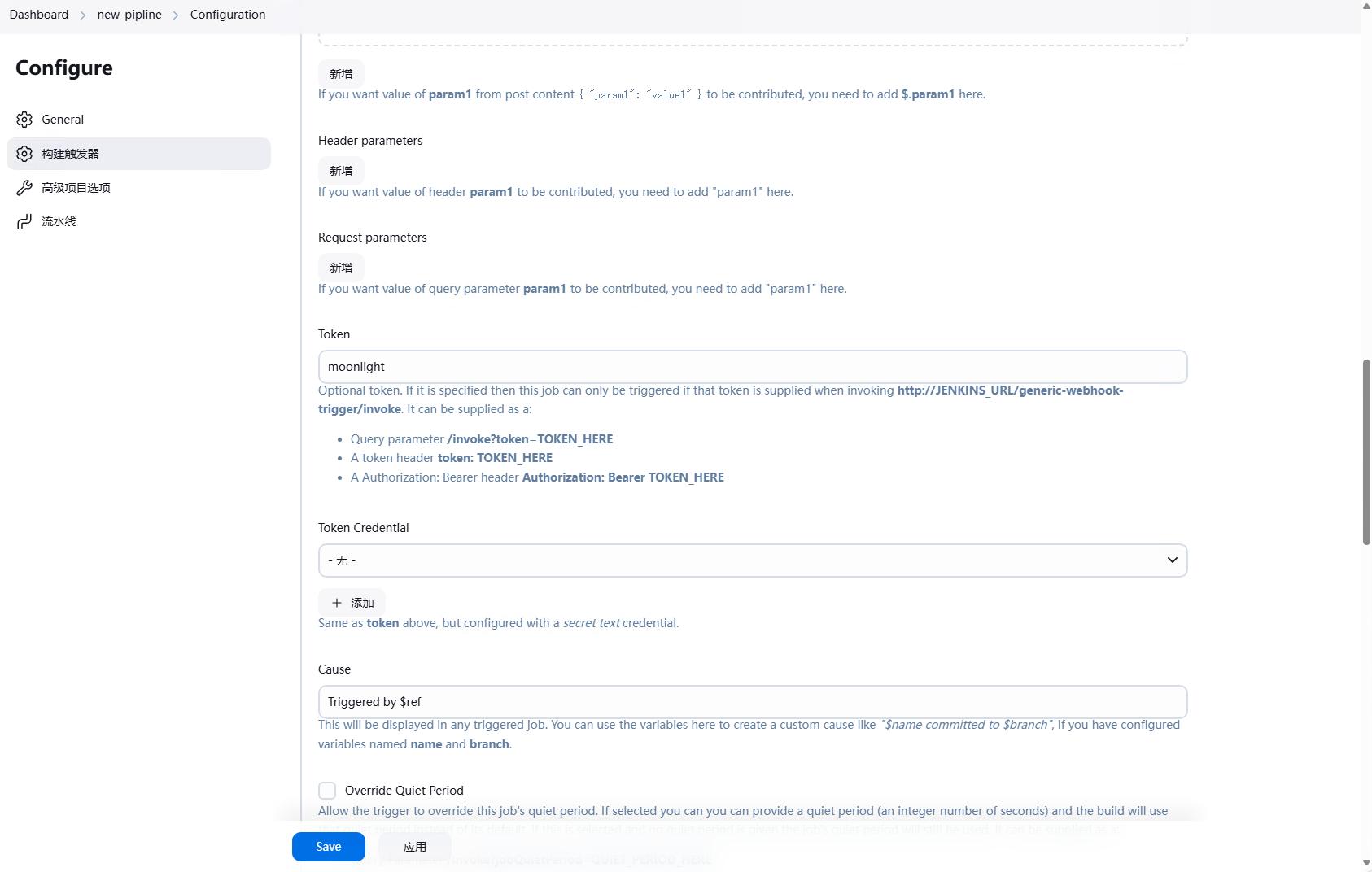
然后我们就可以在定义流水线中填写我们的流水线脚本。
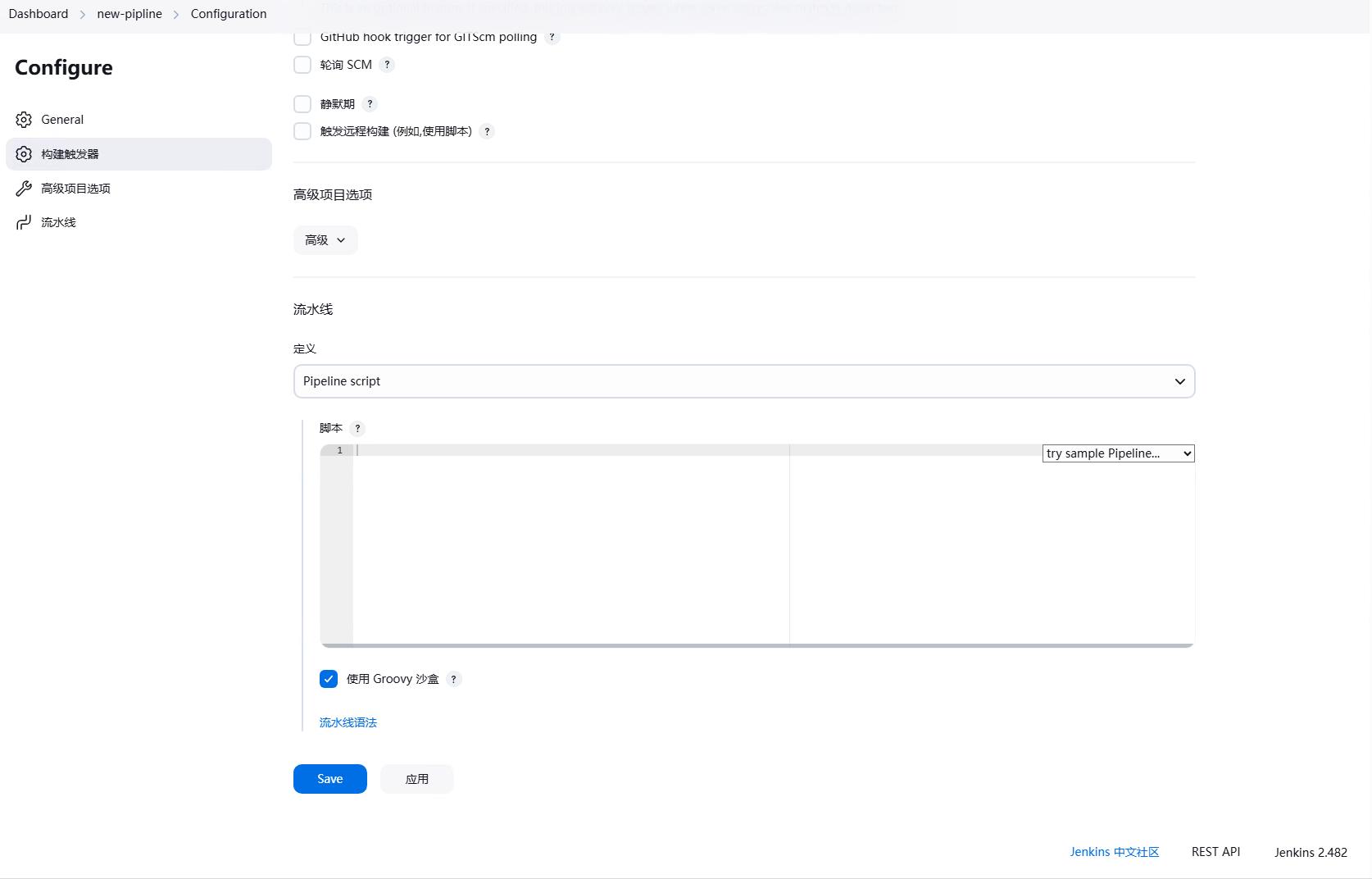
如果我们不会流水线的语法怎么办呢?我们可以点击流水线语法,然后就会跳转到流水线语法的页面。
我们先看片段生成器,这里提供了很多流水线的片段,我们可以根据自己的需求选择片段,然后生成流水线的语法。
比如我们想要对git进行checkout的操作,我们可以选择checkout,然后填写git的地址,分支等信息,然后点击生成流水线语法,就会生成流水线的语法。
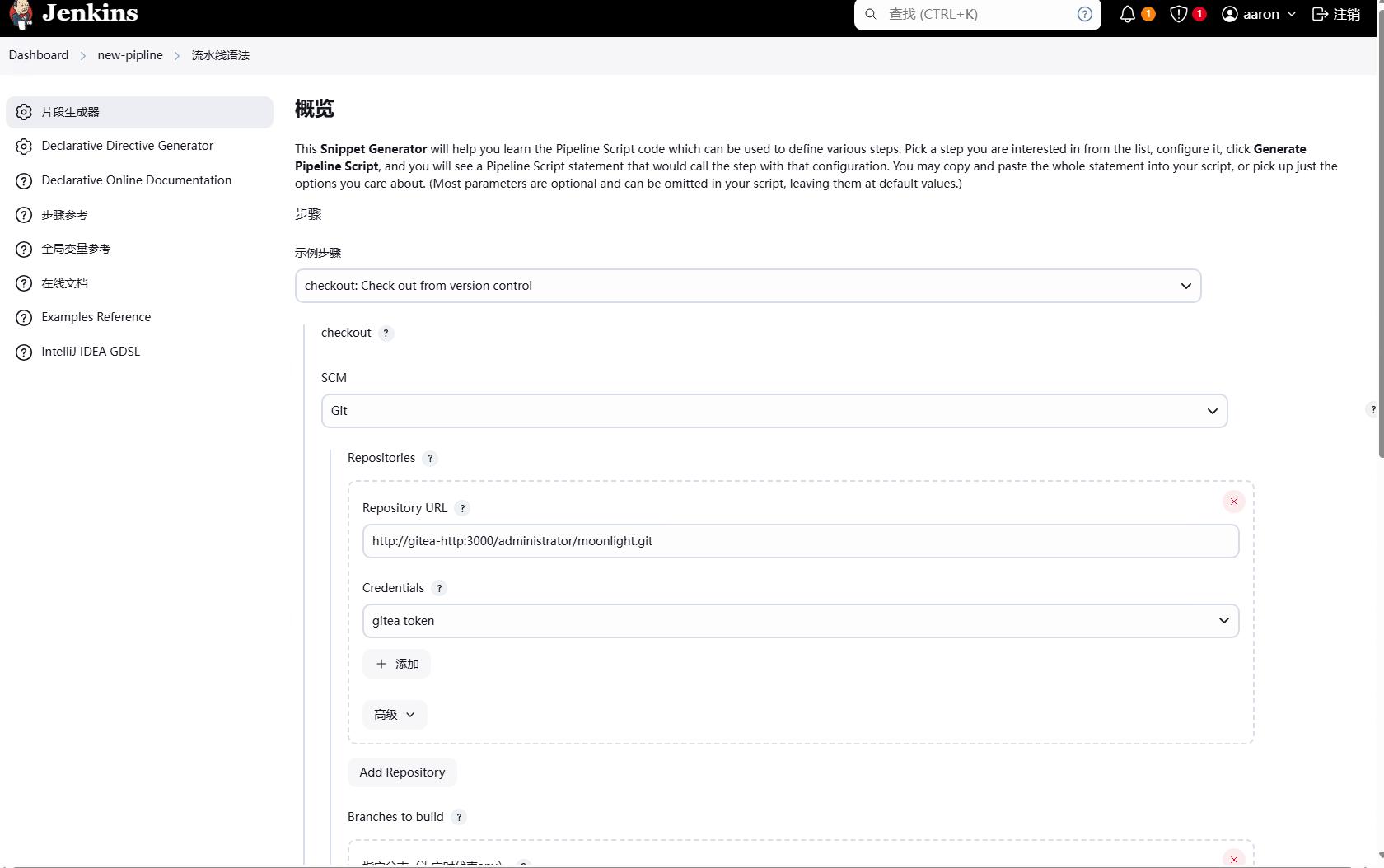
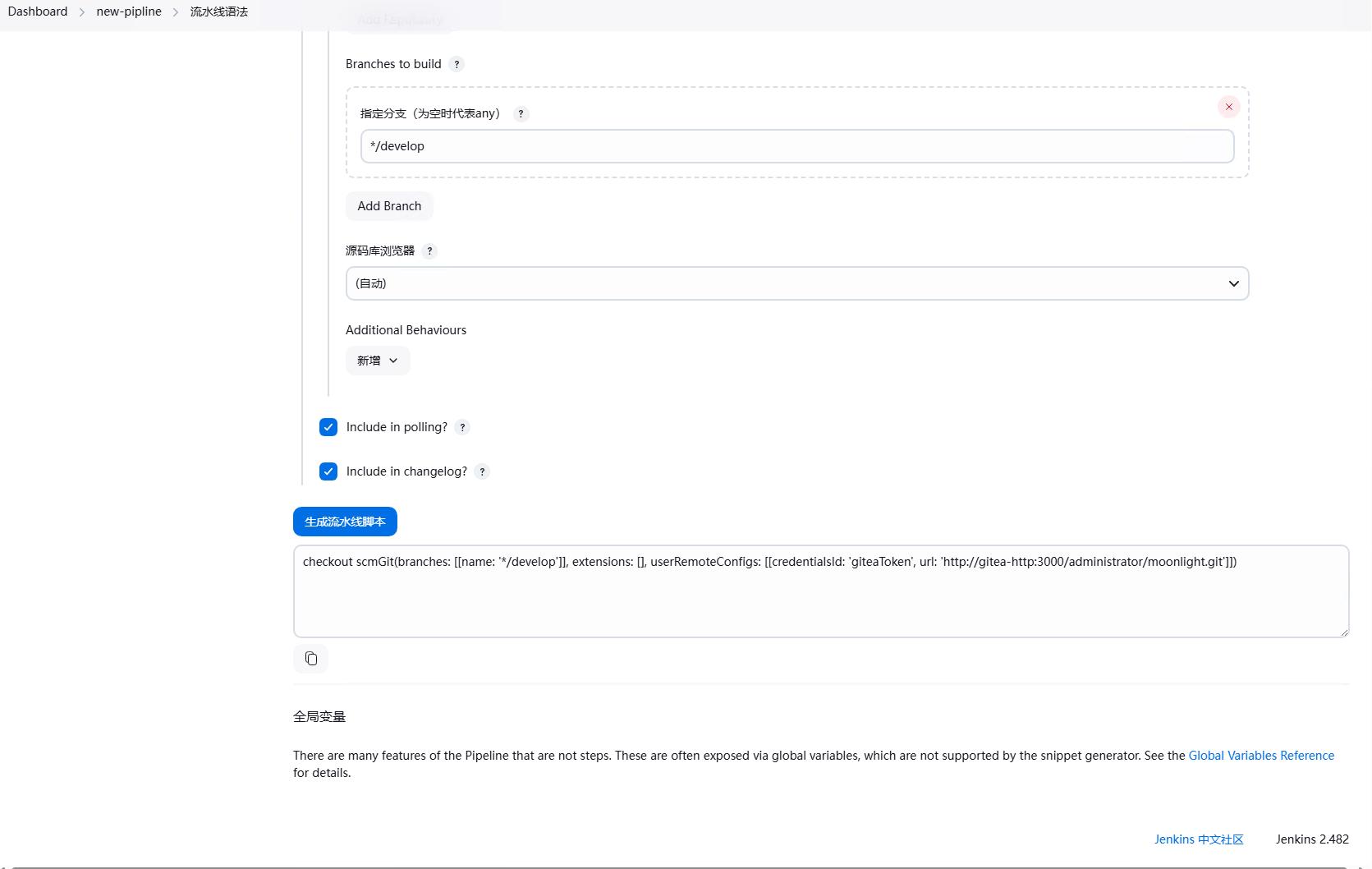
注意,这里生成的只是流水线的语法,并不会实际执行任务,生成的语法可以直接复制到流水线的脚本文件中。
下面是一个完整的流水线脚本,我们还是监听moonlight仓库的webhook,当有代码提交的时候,就会触发流水线,执行docker镜像的构建。
1 | pipeline { |
将他复制到流水线的脚本中,然后点击保存即可。
回到Dashboard,我们可以看到新创建的流水线任务。
然后我们提交代码,触发流水线,之后就能看到流水线的执行过程。
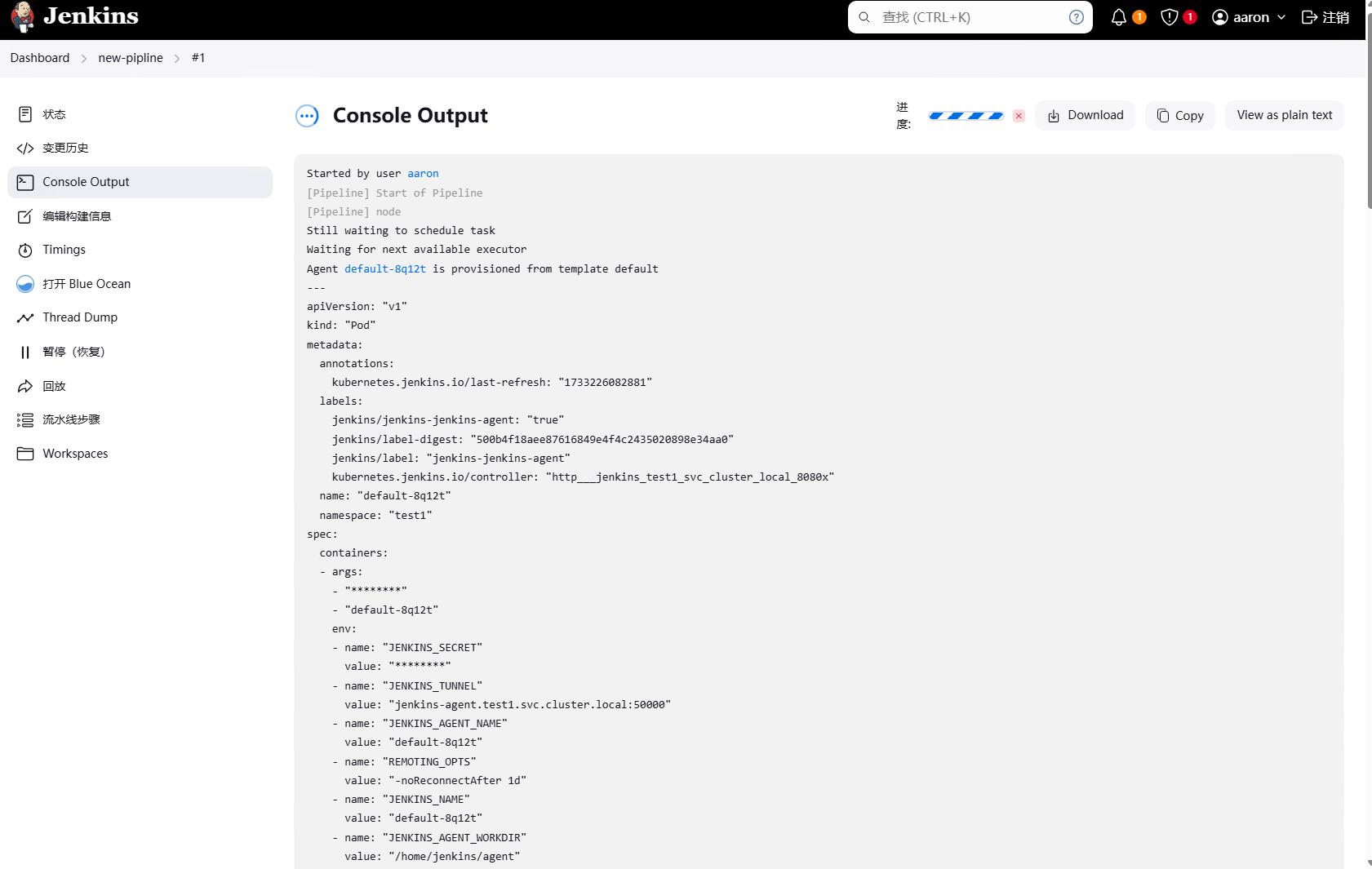
因为我们已经安装了插件 Blue Ocean,因此我们可以在Blue Ocean中看到流水线的执行过程。Blue Ocean是一个Jenkins的插件,提供了一个更好的UI界面,更好的展示流水线的执行过程。
注:这里我们只是演示了功能,具体错误可以进行忽略
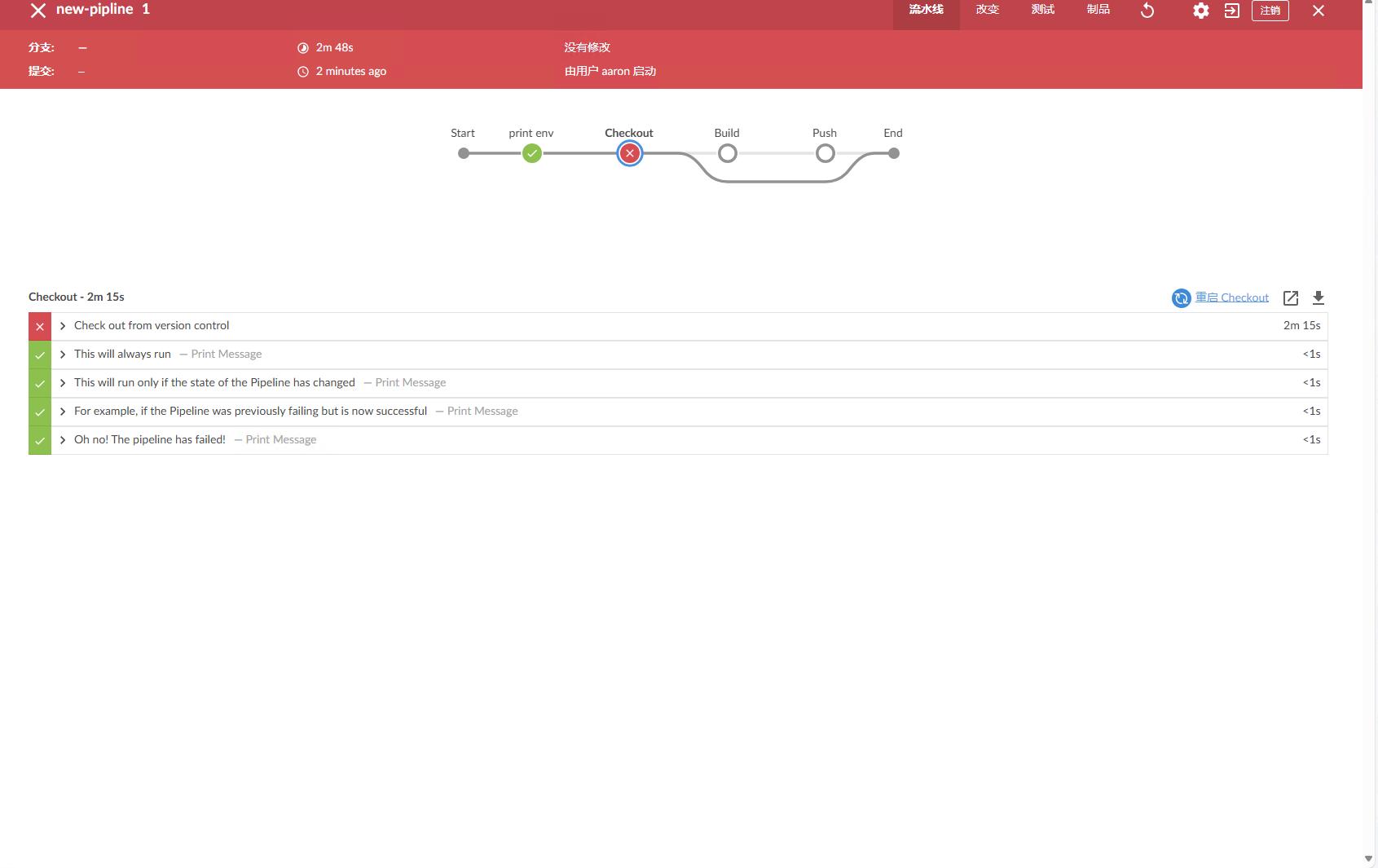
可以看到我们可以看到每个stage的执行过程,每个stage的执行时间,每个stage的执行结果等信息,每一步也有对应的日志输出,可以看到每一步的执行过程。
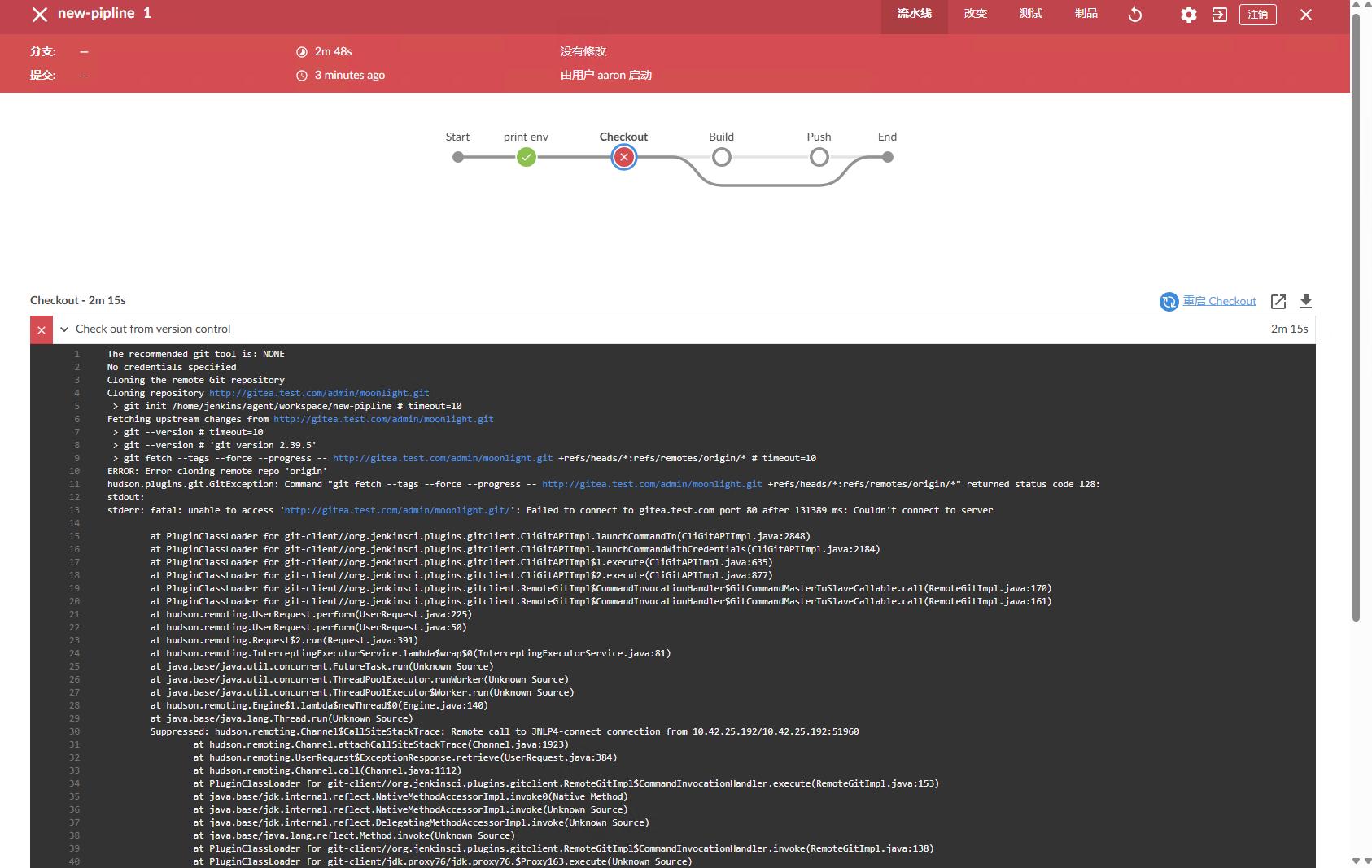
也可以点击其他节点查看其他节点的执行情况。
Jenkins 优化
可以看到,我们的Jenkins已经可以正常使用了,但是我们还可以对Jenkins进行一些优化。
Jenkinsfile
比如我们现在的脚本是直接配置在Jenkins中的,这样不利于维护,也不利于迁移。我们可以将脚本放到代码仓库中,然后通过Jenkinsfile来引用。
如果想要将脚本放到代码仓库中,首先要修改一下流水线的配置,选择Pipeline script from SCM,然后选择Git,然后填写仓库地址,分支等信息,然后点击保存。
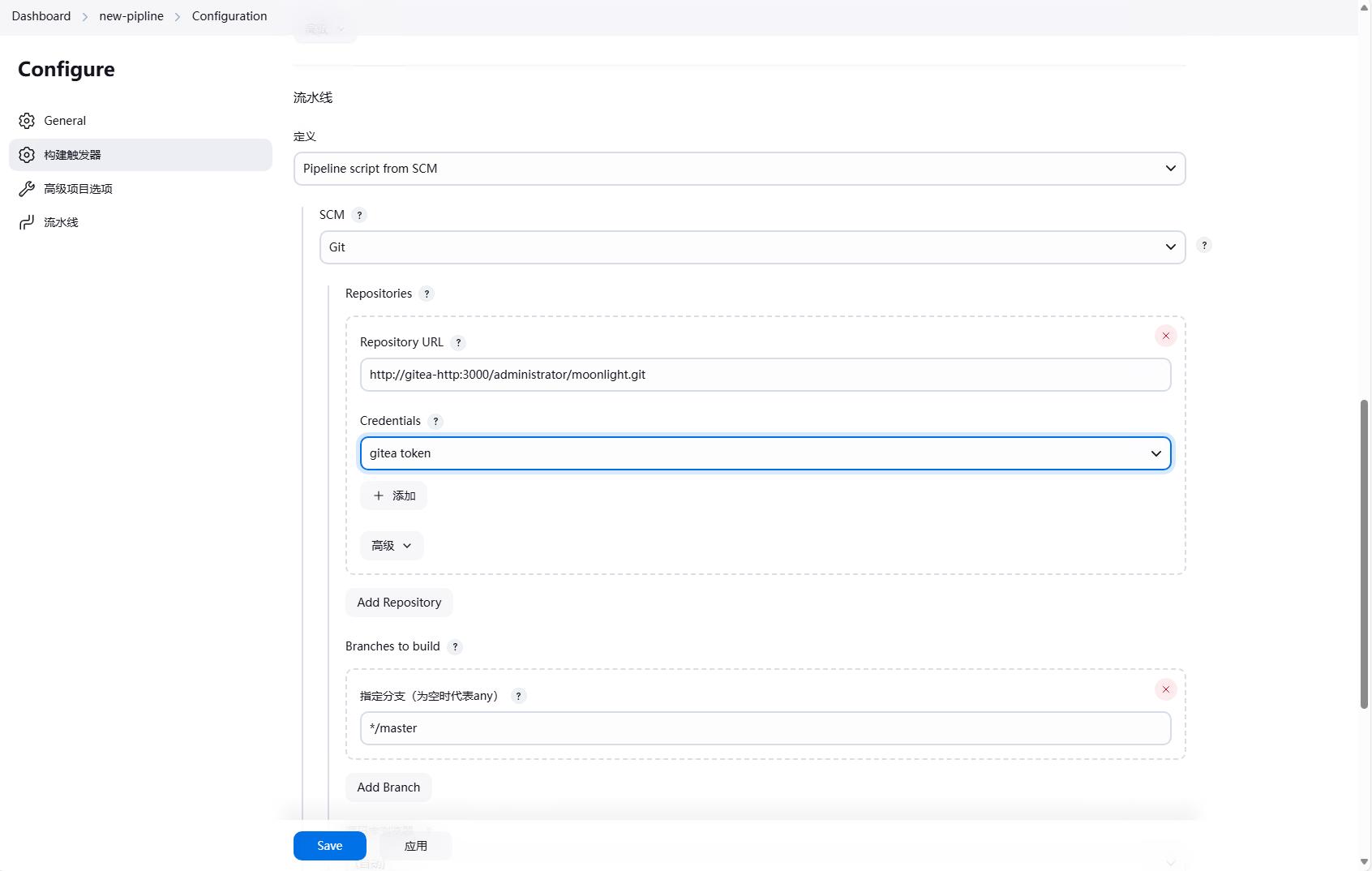
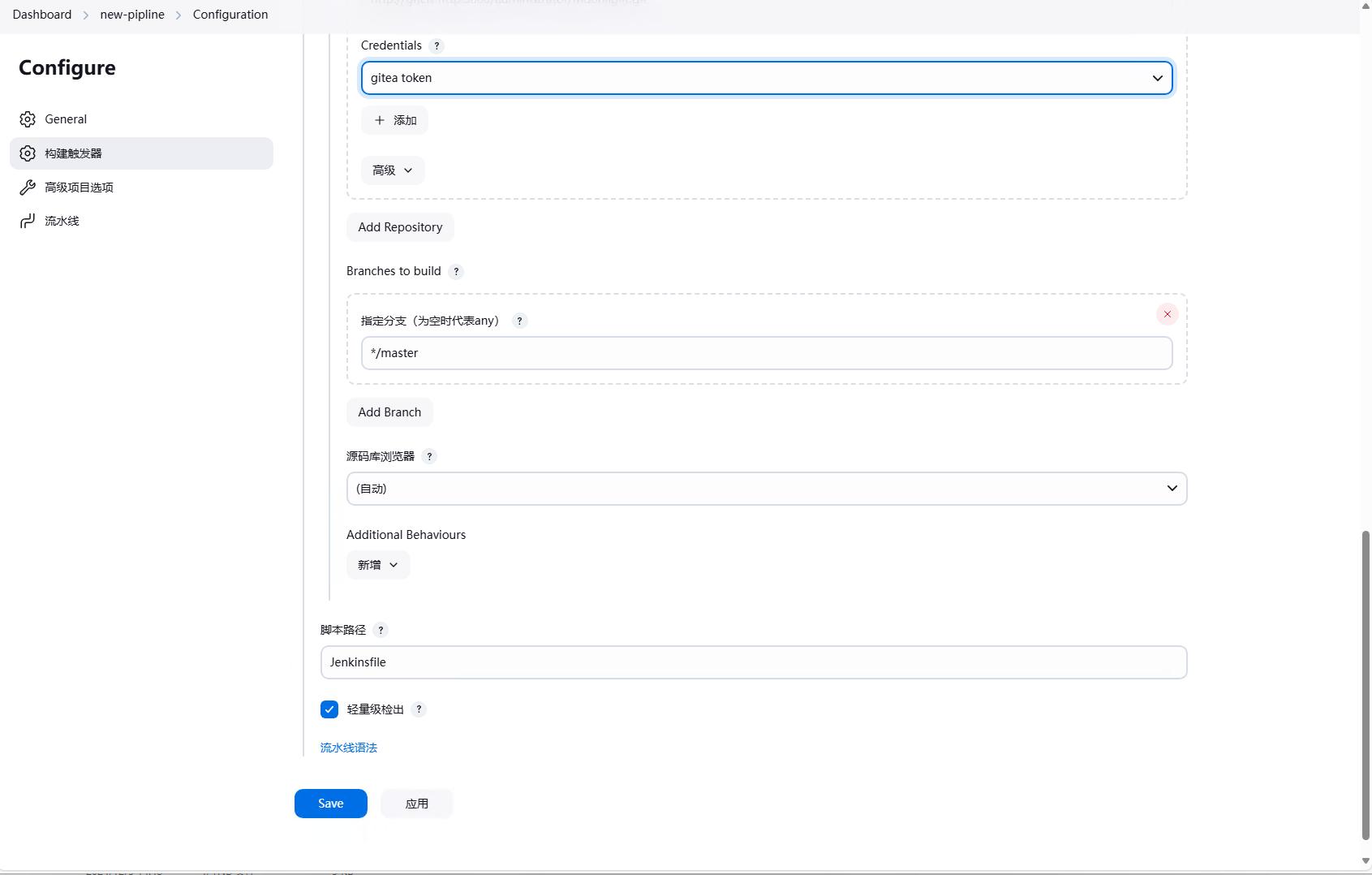
然后我们就可以在代码仓库中创建一个Jenkinsfile文件,然后将流水线的脚本复制到Jenkinsfile中,脚本内容和之前的一样。
checkout scm
在 Jenkinsfile 中,我们需要拉取代码,但是拉取的代码通常和 Jenkinsfile 在同一个仓库中,因此我们可以使用 checkout scm 来拉取代码,这样就不需要再配置拉取代码的步骤了。
这两个单词都是Jenkins的关键字,checkout 是拉取代码的命令,scm 是源码管理的缩写,这两个单词组合在一起就是拉取代码的命令。
1 | ... |
镜像版本
在流水线中,我们定义了一个环境变量 BUILD_VERSION,这个环境变量是用来定义镜像的版本的,这个版本是写死的,每次构建的时候都需要手动修改,这样不利于维护。
我们每次push代码的时候,都会生成一个commit id,这个commit id是唯一的,我们可以使用这个commit id 来定义镜像的版本。
下面是一种方法,这里直接配置环境变量 BUILD_VERSION。
1 | ... |
还有一种方法是直接使用jenkins提供的环墧变量 GIT_COMMIT。
1 | ... |
钉钉通知
在流水线执行完成后,我们可以通过钉钉通知来通知我们流水线的执行结果,这样我们就不需要一直在 Jenkins 中查看流水线的执行结果了。
首先我们需要在钉钉中创建一个机器人,然后获取机器人的 webhook 地址,比如我们这里假设机器人的 webhook 地址为 https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxx。
然后我们可以在流水线的后置条件中添加一个步骤,来发送钉钉通知。
1 | ... |
上面我们在 success 和 failure 后面使用两种方法添加了发送钉钉通知的步骤,这样当流水线执行成功或者失败的时候,就会发送钉钉通知。
使用凭据管理敏感信息
在流水线中,我们可能会使用一些敏感信息,比如用户名、密码等,这些信息不能直接写在流水线中,因为流水线是可以查看的,这样就会泄露敏感信息。
比如上面配置的钉钉通知的token信息,我们就不能直接写在流水线中,我们可以使用凭据管理来管理这些敏感信息。
Jenkins 的声明式流水线语法有一个 credentials() 辅助方法(在environment 指令中使用),它支持 secret 文本,带密码的用户名,以及 secret 文件凭据。
这里只是展示用户名和密码的方式,实际上我们可以使用其他方式,比如secret text。
如果使用用户名密码的方式创建了一个凭证testCred,并且使用 TESTCRED = credentials('testCred') 辅助方法,我们可以在流水线中使用这个凭据的环境变量如下:
${TESTCRED}:凭证的完整内容,格式为username:password${TESTCRED_USR}:凭证的用户名部分,系统会额外进行添加${TESTCRED_PSW}:凭证的密码部分,系统会额外进行添加
首先我们需要在 Jenkins 中创建一个凭据,这里还是使用username with password类型的凭据,然后填写用户名和密码,因为只需要一个token,因此我们可以将token写在密码中,然后点击保存,名称我们可以填写Dingtalk。
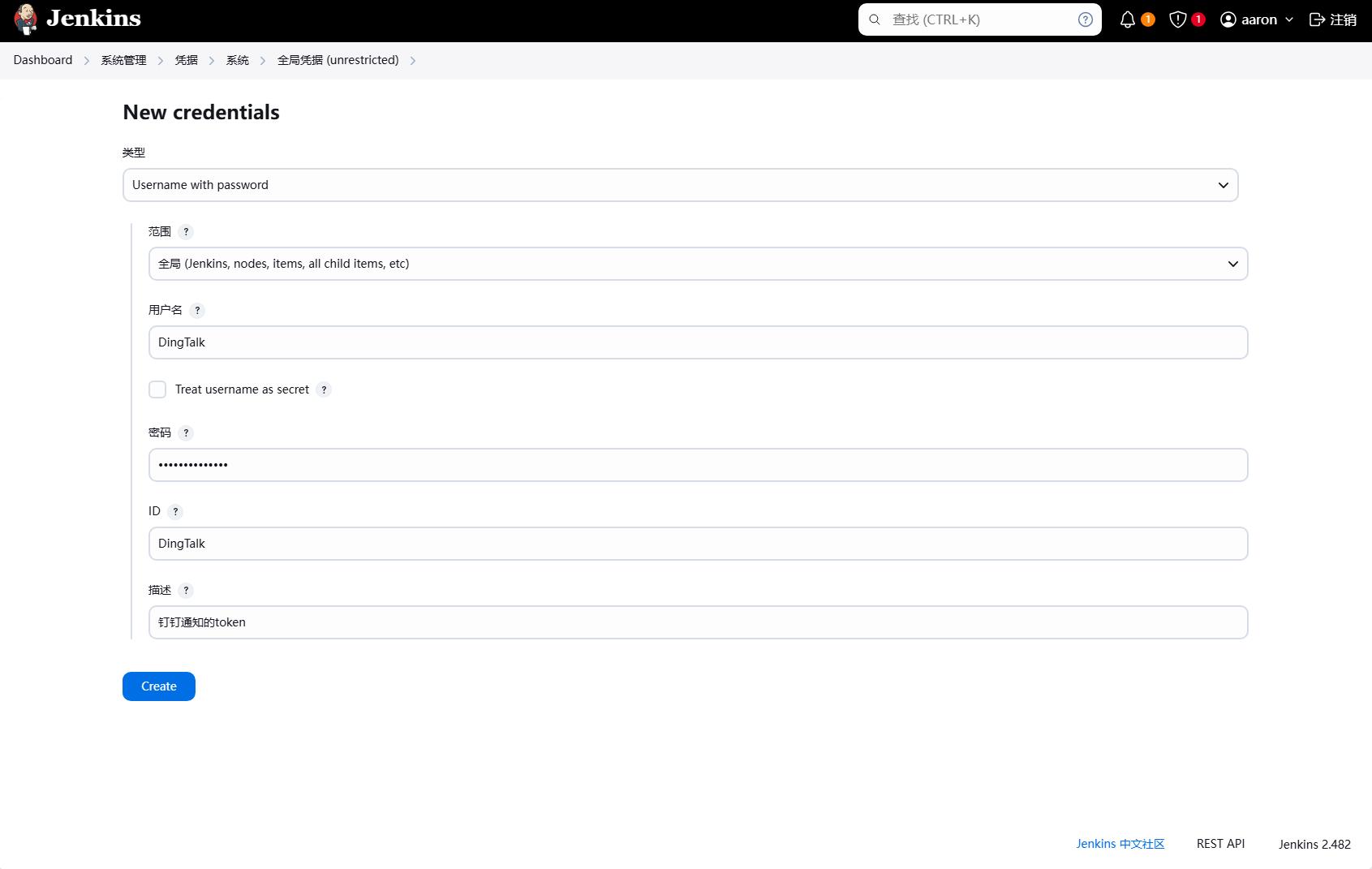
然后我们可以在流水线中使用这个凭据,比如上面的钉钉通知的token信息,我们可以使用凭据管理来管理这个token信息。
1 | ... |