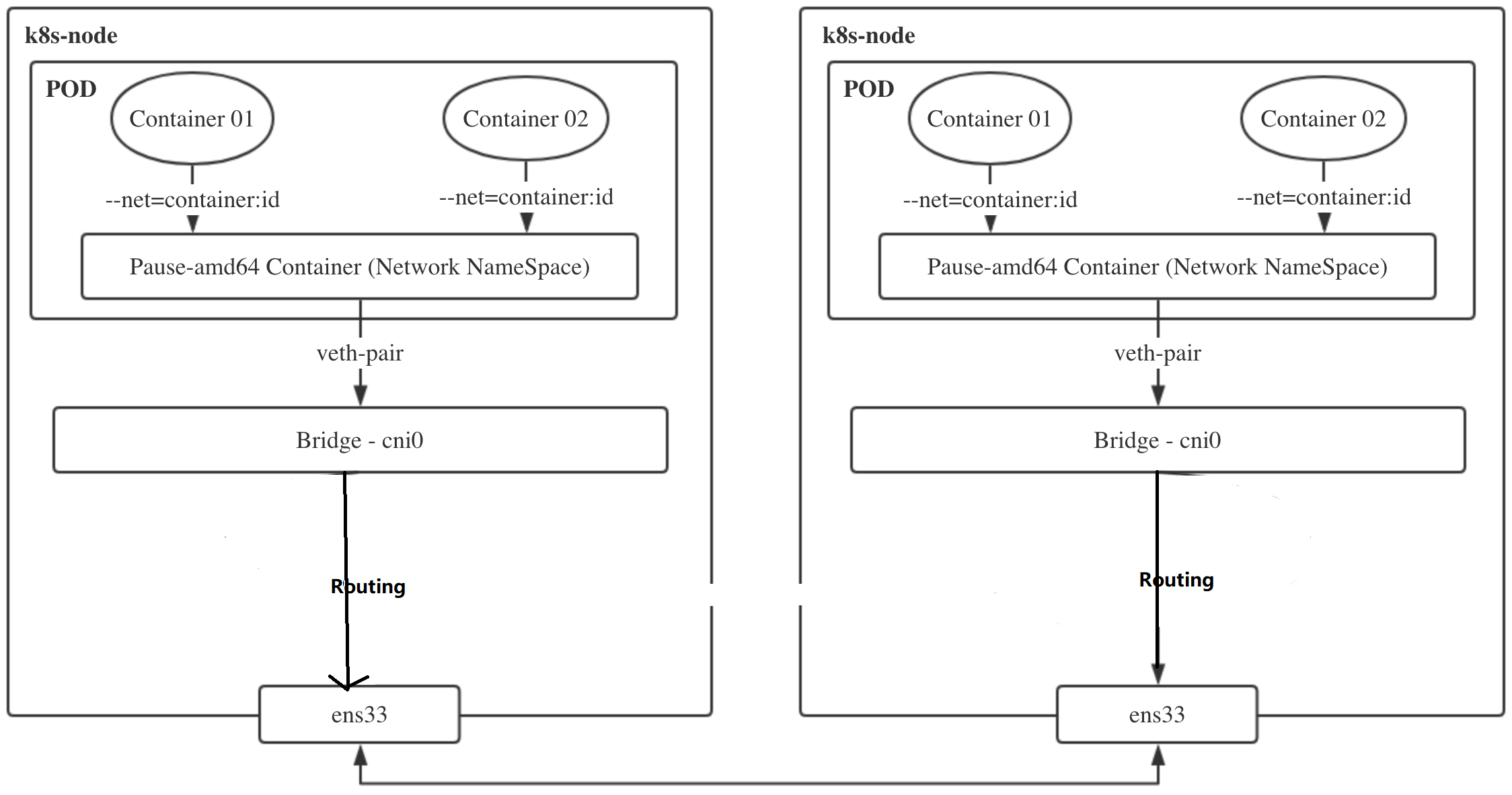
$ ip a s cni0 15: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000 link/ether 6a:93:41:87:41:22 brd ff:ff:ff:ff:ff:ff inet 10.244.0.1/24 brd 10.244.0.255 scope global cni0 valid_lft forever preferred_lft forever inet6 fe80::6893:41ff:fe87:4122/64 scope link valid_lft forever preferred_lft forever $ yum install bridge-utils -y ...... $ brctl show bridge name bridge id STP enabled interfaces cni0 8000.6a9341874122 no veth8a587a83 docker0 8000.024289168674 no
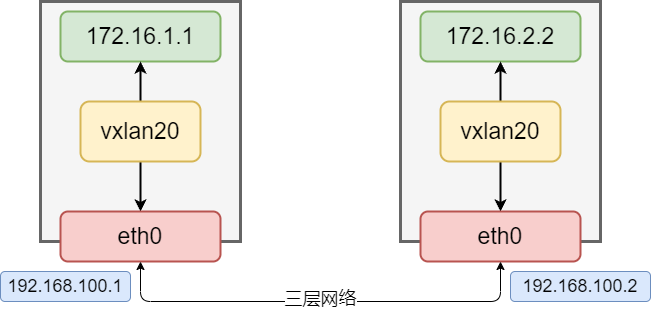
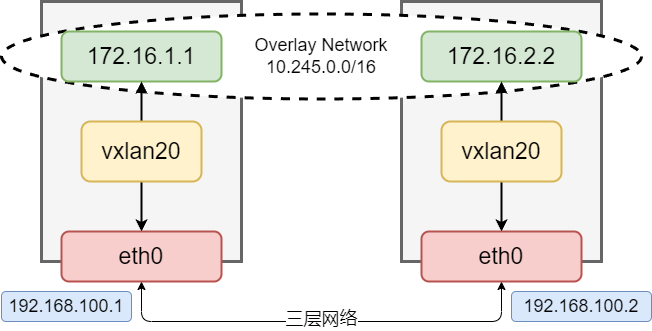
# 创建vTEP设备,对端指向192.168.100.2节点,指定VNI及underlay网络使用的网卡 $ sudo ip link add vxlan20 type vxlan id 20 remote 192.168.100.2 dstport 4789 dev ens224 # 查看设备信息 $ sudo ip -d link show vxlan20 # 启动设备 $ sudo ip linkset vxlan20 up # 设置ip地址 $ sudo ip addr add 172.16.1.1/24 dev vxlan20
192.168.100.2节点:
1 2 3 4 5 6
# 创建VTEP设备,对端指向192.168.100.1节点,指定VNI及underlay网络使用的网卡 $ sudo ip link add vxlan20 type vxlan id 20 remote 192.168.100.1 dstport 4789 dev ens224 # 启动设备 $ sudo ip linkset vxlan20 up # 设置ip地址 $ sudo ip addr add 172.16.2.2/24 dev vxlan20
# 查看集群中的Pod,查找两个不同节点的Pod,这里选取了myblog和testpod $ kubectl -n test get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myblog-84985b5b66-smpwb 1/1 Running 0 76d 10.244.1.5 k8s-node1 <none> <none> mysql-7f97cb6cc9-vzxpd 1/1 Running 0 76d 192.168.100.2 k8s-node1 <none> <none> testpod-865855cfc5-m2f99 1/1 Running 0 63d 10.244.2.13 k8s-node2 <none> <none>
$ kubectl -n testexec myblog-84985b5b66-smpwb -- ping 10.244.2.13 -c 6 PING 10.244.2.13 (10.244.2.13) 56(84) bytes of data. 64 bytes from 10.244.2.13: icmp_seq=1 ttl=62 time=1.05 ms 64 bytes from 10.244.2.13: icmp_seq=2 ttl=62 time=1.04 ms 64 bytes from 10.244.2.13: icmp_seq=3 ttl=62 time=0.856 ms 64 bytes from 10.244.2.13: icmp_seq=4 ttl=62 time=1.14 ms 64 bytes from 10.244.2.13: icmp_seq=5 ttl=62 time=1.03 ms 64 bytes from 10.244.2.13: icmp_seq=6 ttl=62 time=0.974 ms
--- 10.244.2.13 ping statistics --- 6 packets transmitted, 6 received, 0% packet loss, time 5005ms rtt min/avg/max/mdev = 0.856/1.014/1.143/0.086 ms
# 查看路由 $ kubectl -n testexec myblog-84985b5b66-smpwb -- route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.244.1.1 0.0.0.0 UG 0 0 0 eth0 10.244.0.0 10.244.1.1 255.255.0.0 UG 0 0 0 eth0 10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
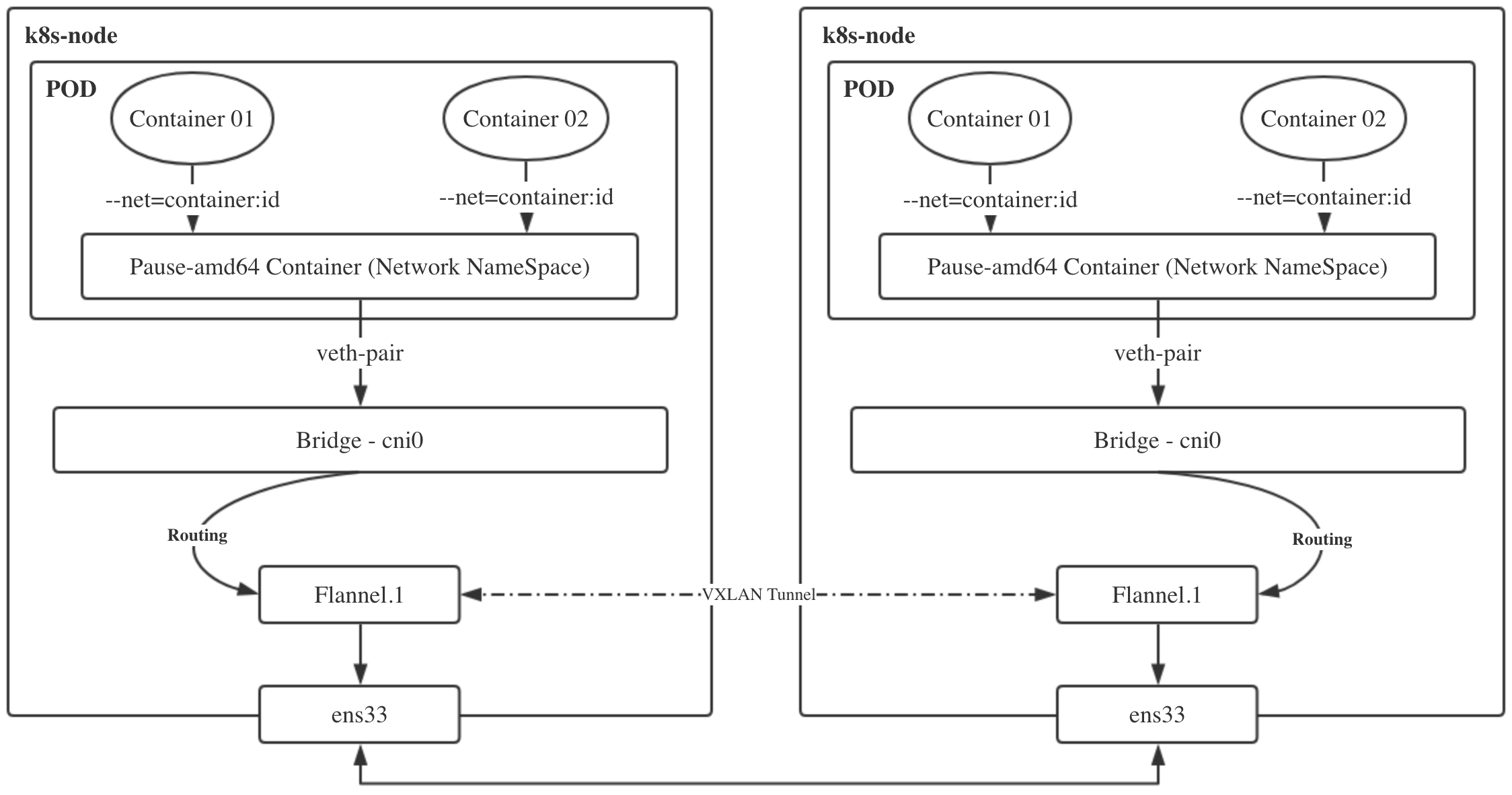
# 查看k8s-master 的veth pair 和网桥 $ brctl show bridge name bridge id STP enabled interfaces cni0 8000.6a9341874122 no veth8a587a83 vethe7a6a0e0 docker0 8000.024289168674 no
# 流量到了cni0后,查看master节点的route $ ip r s default via 10.209.0.200 dev ens192 proto dhcp src 10.209.0.13 metric 100 default via 192.168.100.254 dev ens224 proto static metric 101 10.209.0.0/21 dev ens192 proto kernel scope link src 10.209.0.13 metric 100 10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink 10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink 172.7.21.0/24 dev docker0 proto kernel scope link src 172.7.21.1 linkdown 192.168.100.0/24 dev ens224 proto kernel scope link src 192.168.100.1 metric 101
# 流量转发到了flannel.1网卡,查看该网卡,其实是vtep设备 $ ip -d link show flannel.1 $ ip -d link show flannel.1 6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default link/ether 0e:af:83:0c:88:29 brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535 vxlan id 1 local 10.209.0.13 dev ens192 srcport 0 0 dstport 8472 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 tso_max_size 65536 tso_max_segs 65535 gro_max_size 65536
# 该转发到哪里,通过etcd查询数据,然后本地缓存,流量不用走多播发送 $ bridge fdb show dev flannel.1 f6:62:9f:90:cf:fe dst 10.209.0.15 self permanent 66:1a:39:32:d5:13 dst 10.209.0.11 self permanent
查看k8s-node1的路由
1 2 3 4 5 6 7 8 9 10 11
# 对端的vtep设备接收到请求后做解包,取出源payload内容 $ route -n Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 172.21.64.190 0.0.0.0 UG 0 0 0 eth0 10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1 10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 #根据路由规则转发到cni0网桥,然后由网桥转到具体的Pod中
$ kubectl -n kube-flannel get pod NAME READY STATUS RESTARTS AGE kube-flannel-ds-6tx4f 1/1 Running 0 88d kube-flannel-ds-7p2rb 1/1 Running 0 88d kube-flannel-ds-rx54g 1/1 Running 0 88d
$ kubectl -n kube-flannel delete po kube-flannel-ds-6tx4f kube-flannel-ds-7p2rb kube-flannel-ds-rx54g
# 等待Pod新启动后,查看日志,出现Backend type: host-gw字样 $ kubectl -n kube-flannel logs -f kube-flannel-ds-xbbg2 Defaulted container "kube-flannel" out of: kube-flannel, install-cni-plugin (init), install-cni (init) I1121 17:30:43.302575 1 main.go:212] CLI flags config: {etcdEndpoints:http://127.0.0.1:4001,http://127.0.0.1:2379 etcdPrefix:/coreos.com/network etcdKeyfile: etcdCertfile: etcdCAFile: etcdUsername: etcdPassword: version:false kubeSubnetMgr:true kubeApiUrl: kubeAnnotationPrefix:flannel.alpha.coreos.com kubeConfigFile: iface:[ens224] ifaceRegex:[] ipMasq:true ifaceCanReach: subnetFile:/run/flannel/subnet.env publicIP: publicIPv6: subnetLeaseRenewMargin:60 healthzIP:0.0.0.0 healthzPort:0 iptablesResyncSeconds:5 iptablesForwardRules:true netConfPath:/etc/kube-flannel/net-conf.json setNodeNetworkUnavailable:true useMultiClusterCidr:false} W1121 17:30:43.302852 1 client_config.go:617] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work. I1121 17:30:43.336114 1 kube.go:145] Waiting 10m0s for node controller to sync I1121 17:30:43.336353 1 kube.go:489] Starting kube subnet manager I1121 17:30:43.345998 1 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.244.0.0/24] I1121 17:30:43.346170 1 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.244.1.0/24] I1121 17:30:43.346257 1 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.244.2.0/24] I1121 17:30:44.337195 1 kube.go:152] Node controller sync successful I1121 17:30:44.337292 1 main.go:232] Created subnet manager: Kubernetes Subnet Manager - k8s-master I1121 17:30:44.337312 1 main.go:235] Installing signal handlers I1121 17:30:44.337914 1 main.go:543] Found network config - Backend type: host-gw I1121 17:30:44.339623 1 match.go:259] Using interface with name ens224 and address 192.168.100.1 I1121 17:30:44.339696 1 match.go:281] Defaulting external address to interface address (192.168.100.1) I1121 17:30:44.360432 1 main.go:357] Setting up masking rules I1121 17:30:44.361152 1 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.244.0.0/24] I1121 17:30:44.417318 1 main.go:408] Changing default FORWARD chain policy to ACCEPT I1121 17:30:44.422345 1 iptables.go:290] generated 7 rules I1121 17:30:44.428274 1 iptables.go:290] generated 3 rules I1121 17:30:44.428651 1 main.go:436] Wrote subnet file to /run/flannel/subnet.env I1121 17:30:44.428713 1 main.go:440] Running backend. I1121 17:30:44.429253 1 route_network.go:56] Watching for new subnet leases ......
查看节点路由表:
1 2 3 4 5 6 7 8 9
$ ip r s default via 10.209.0.200 dev ens192 proto dhcp src 10.209.0.13 metric 100 default via 192.168.100.254 dev ens224 proto static metric 101 10.209.0.0/21 dev ens192 proto kernel scope link src 10.209.0.13 metric 100 10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 10.244.1.0/24 via 192.168.100.2 dev ens224 10.244.2.0/24 via 192.168.100.3 dev ens224 172.7.21.0/24 dev docker0 proto kernel scope link src 172.7.21.1 linkdown 192.168.100.0/24 dev ens224 proto kernel scope link src 192.168.100.1 metric 101