全部的 K8S学习笔记总目录,请点击查看。
实现原理
docker优势主要是轻量级的虚拟化以及容器快速启停。
而虚拟化核心需要解决两个问题:资源隔离与资源限制
- 虚拟机硬件虚拟化技术, 通过一个 hypervisor 层实现对资源的彻底隔离。
- 容器则是操作系统级别的虚拟化,利用的是内核的 Cgroup 和 Namespace 特性,此功能完全通过软件实现。
Namespace 资源隔离
命名空间是全局资源的一种抽象,将资源放到不同的命名空间中,各个命名空间中的资源是相互隔离的。
| 分类 | 系统调用参数 | 相关内核版本 |
|---|---|---|
| Mount namespaces | CLONE_NEWNS | Linux 2.4.19 |
| UTS namespaces | CLONE_NEWUTS | Linux 2.6.19 |
| IPC namespaces | CLONE_NEWIPC | Linux 2.6.19 |
| PID namespaces | CLONE_NEWPID | Linux 2.6.24 |
| Network namespaces | CLONE_NEWNET | 始于Linux 2.6.24 完成于 Linux 2.6.29 |
| User namespaces | CLONE_NEWUSER | 始于 Linux 2.6.23 完成于 Linux 3.8 |
我们知道,docker容器对于操作系统来讲其实是一个进程,我们可以通过原始的方式来模拟一下容器实现资源隔离的基本原理:
linux系统中,通常可以通过clone()实现进程创建的系统调用 ,原型如下:
1 | int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg); |
- child_func : 传入子进程运行的程序主函数。
- child_stack : 传入子进程使用的栈空间。
- flags : 表示使用哪些
CLONE_*标志位。 - args : 用于传入用户参数。
示例一:实现进程独立的UTS空间
1 |
|
执行编译并测试:
1 | $ gcc -o ns_uts ns_uts.c |
示例二:实现容器独立的进程空间
1 |
|
执行编译并测试:
1 | $ gcc -o ns_pid ns_pid.c |
如何确定进程是否属于同一个namespace:
1 | $ ./ns_pid |
综上:通俗来讲,docker在启动一个容器的时候,会调用Linux Kernel
Namespace的接口,来创建一块虚拟空间,创建的时候,可以支持设置下面这几种(可以随意选择),docker默认都设置。
- pid:用于进程隔离(PID:进程ID)
- net:管理网络接口(NET:网络)
- ipc:管理对 IPC 资源的访问(IPC:进程间通信(信号量、消息队列和共享内存))
- mnt:管理文件系统挂载点(MNT:挂载)
- uts:隔离主机名和域名
- user:隔离用户和用户组
linux namespace 可以支持创建进程的时候,通过参数传递(CLONE_NEW*)来确定这个新启动的进程以及进程衍生的子进程是否拥有独立的进程空间,网络空间,文件系统空间,用户空间等等。
docker容器对于宿主机来说,其实就是一个进程,创建容器时,给这个容器进程指定了独立的进程空间,网络空间,文件系统空间,用户空间等等,这样就实现了容器的资源隔离。
CGroup 资源限制
通过namespace可以保证容器之间的隔离,但是无法控制每个容器可以占用多少资源, 如果其中的某一个容器正在执行 CPU
密集型的任务,那么就会影响其他容器中任务的性能与执行效率,导致多个容器相互影响并且抢占资源。如何对多个容器的资源使用进行限制就成了解决进程虚拟资源隔离之后的主要问题。
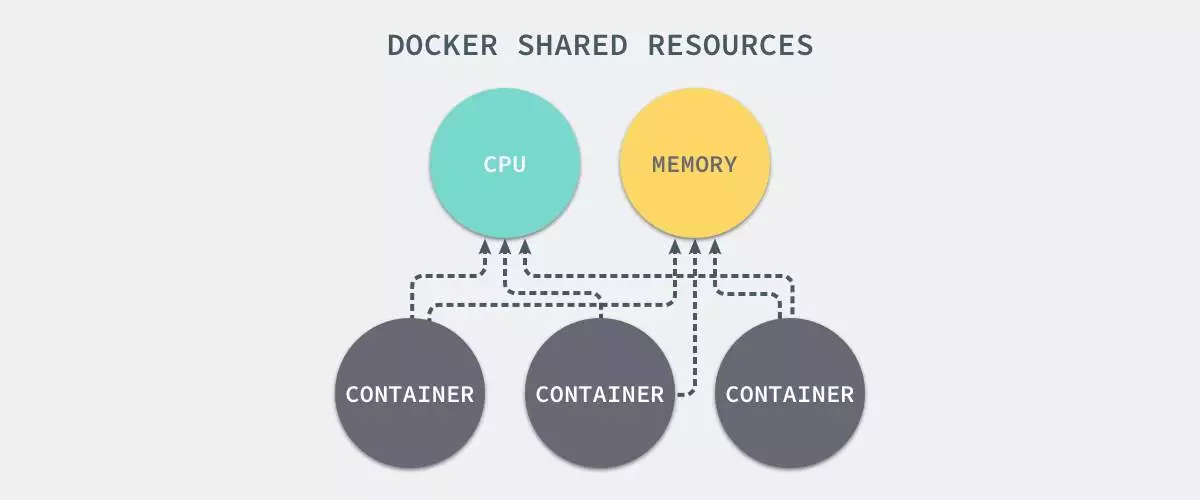
Control Groups(简称 CGroups)
cgroups是Linux内核提供的一种机制,这种机制可以根据需求吧一系列系统任务及其子任务整合(或分隔)
到按资源划分等级的不同组中,从而为系统资源管理提供一个统一的框架。
CGroups能够隔离宿主机器上的物理资源,例如 CPU、内存、磁盘 I/O 。每一个 CGroup
都是一组被相同的标准和参数限制的进程。而我们需要做的,其实就是把容器这个进程加入到指定的Cgroup中。
验证cgroup的内存限制:
准备一个程序,每秒钟申请1MB的内存,
mem-allocate.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main(int argc, char *argv[])
{
char *p;
int i = 0;
while(1) {
p = (char *)malloc(MB);
memset(p, 0, MB);
printf("%dM memory allocated\n", ++i);
sleep(1);
}
return 0;
}创建cgroup文件及脚本
1
2
3
4cd /sys/fs/cgroup/memory/
mkdir -p memory-process && cd memory-process
echo 30M > memory.limit_in_bytes
gcc mem-allocate.c -o mem-allocate准备脚本
cgroup-test.sh1
2sleep 30
./mem-allocate用cgroup限制进程
1
2
3
4
5
6# 启动程序
./cgroup-test.sh
# 查看程序进程
ps aux|grep cgroup-test
echo 16079 > /sys/fs/cgroup/memory/memory-process/cgroup.procs
UnionFS 联合文件系统
Linux namespace和cgroup分别解决了容器的资源隔离与资源限制,那么容器是很轻量的,通常每台机器中可以运行几十上百个容器,
这些个容器是共用一个image,还是各自将这个image复制了一份,然后各自独立运行呢?
如果每个容器之间都是全量的文件系统拷贝,那么会导致至少如下问题:
- 运行容器的速度会变慢
- 容器和镜像对宿主机的磁盘空间的压力
怎么解决这个问题呢?这就需要联合文件系统(UnionFS)了。
Docker使用了UnionFS的存储驱动。
- 镜像分层存储 + 写时复制
- UnionFS
Docker 镜像是由一系列的层组成的,每层代表 Dockerfile 中的一条指令,比如下面的 Dockerfile 文件:
1 | FROM ubuntu:15.04 |
这里的 Dockerfile 包含4条命令,其中每一行就创建了一层,下面显示了上述Dockerfile构建出来的镜像运行的容器层的结构。
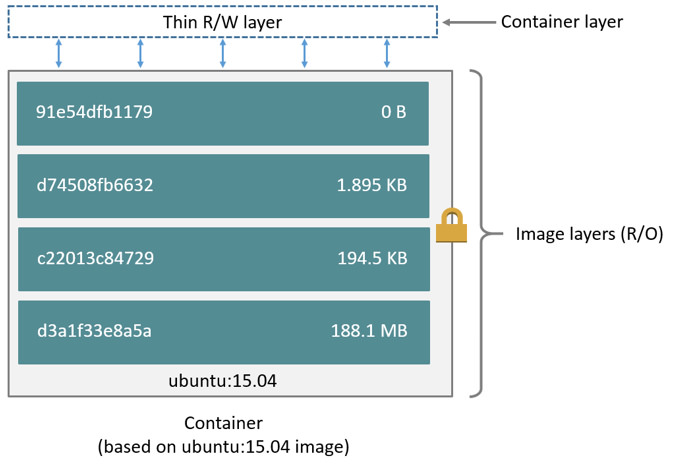
镜像就是由这些层一层一层堆叠起来的,镜像中的这些层都是只读的,当我们运行容器的时候,就可以在这些基础层至上添加新的可写层,也就是我们通常说的容器层
,对于运行中的容器所做的所有更改(比如写入新文件、修改现有文件、删除文件)都将写入这个容器层。
对容器层的操作,主要利用了写时复制(CoW)技术。CoW就是copy-on-write,表示只在需要写时才去复制,这个是针对已有文件的修改场景。
CoW技术可以让所有的容器共享image的文件系统,所有数据都从image中读取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。所以无论有多少个容器共享同一个image,所做的写操作都是对从image中复制到自己的文件系统中的复本上进行,并不会修改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个复本,每个容器修改的都是自己的复本,相互隔离,相互不影响。使用CoW可以有效的提高磁盘的利用率。
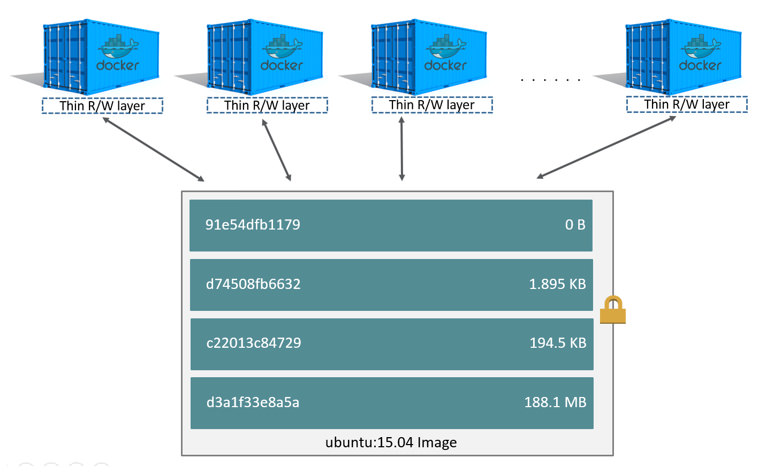
镜像中每一层的文件都是分散在不同的目录中的,如何把这些不同目录的文件整合到一起呢?
UnionFS 其实是一种为 Linux 操作系统设计的用于把多个文件系统联合到同一个挂载点的文件系统服务。它能够将不同文件夹中的层联合(Union)到了同一个文件夹中,整个联合的过程被称为联合挂载(Union
Mount)。
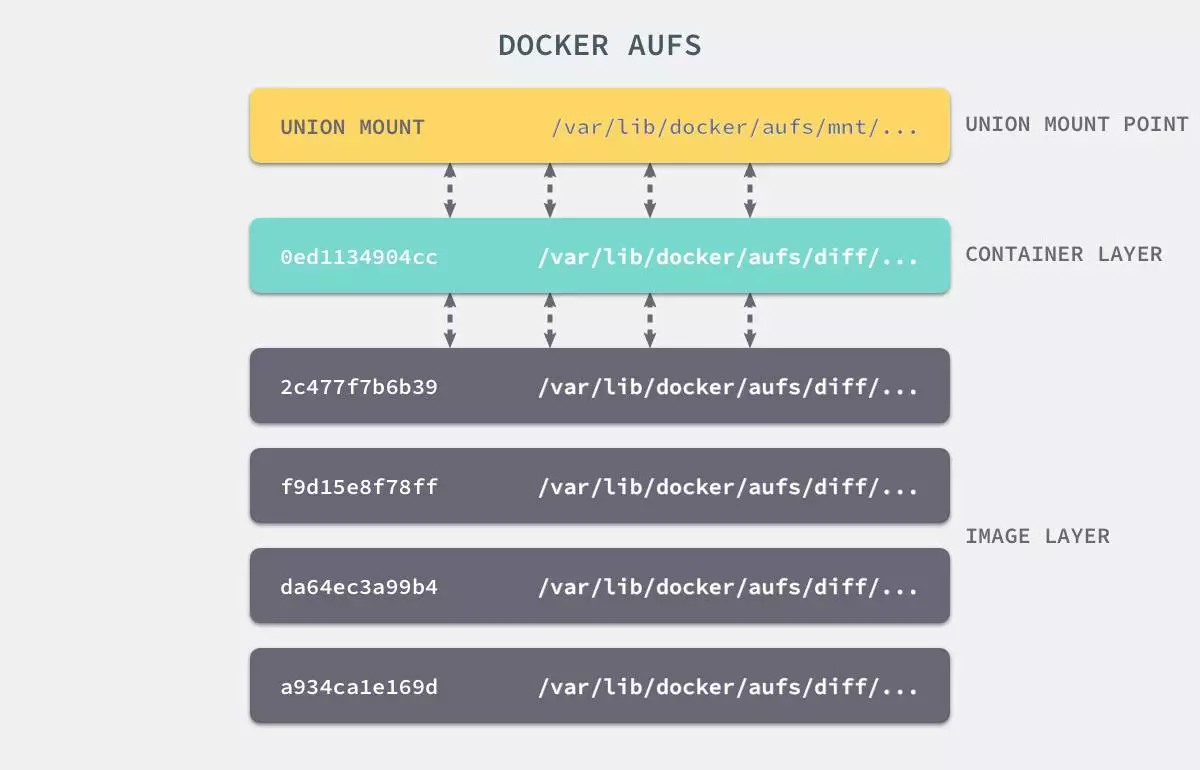
上图是AUFS的实现,AUFS是作为Docker存储驱动的一种实现,Docker 还支持了不同的存储驱动,包括 aufs、devicemapper、overlay2、zfs 和
Btrfs 等等,在最新的 Docker 中,overlay2 取代了 aufs 成为了推荐的存储驱动,但是在没有 overlay2 驱动的机器上仍然会使用 aufs
作为 Docker 的默认驱动。